
Штучний інтелект проникає в індустрію субтитрування, але людський фактор все ще залишається необхідним. Субтитрувальники попереджають, що ШІ не спрощує процес настільки, як очікувалося.

Вітні Чжан, аспірантка Массачусетського технологічного інституту, вивчає економіку праці з метою поліпшення умов праці та продуктивності працівників за допомогою інструментів штучного інтелекту, таких як ChatGPT. Її дослідження також присвячені впливу непередбачуваних графіків роботи на якість життя працівників з низькою заробітною платою.
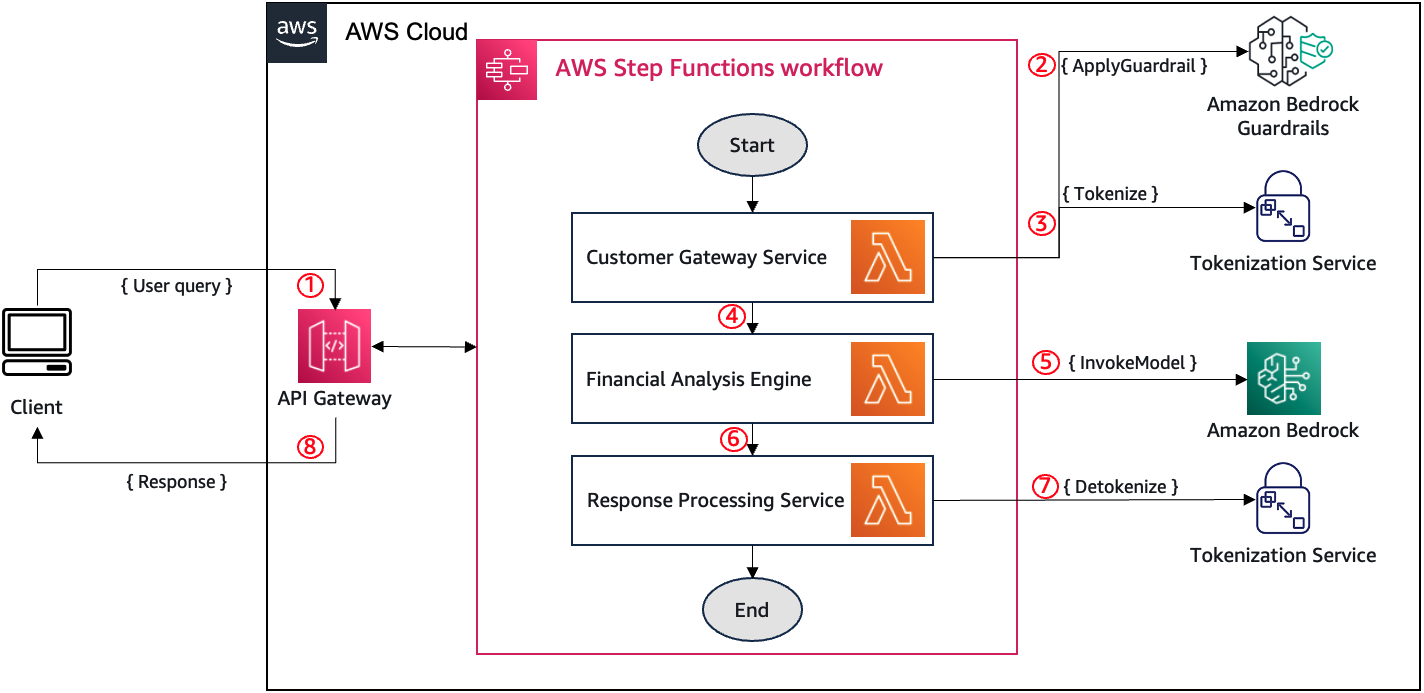
Генеративні AI-додатки у виробництві стикаються з проблемами захисту персональних даних. Amazon Bedrock Guardrails і токенізація пропонують рішення для забезпечення конфіденційності та оборотного характеру даних, що є надзвичайно важливим для організацій у регульованих галузях.
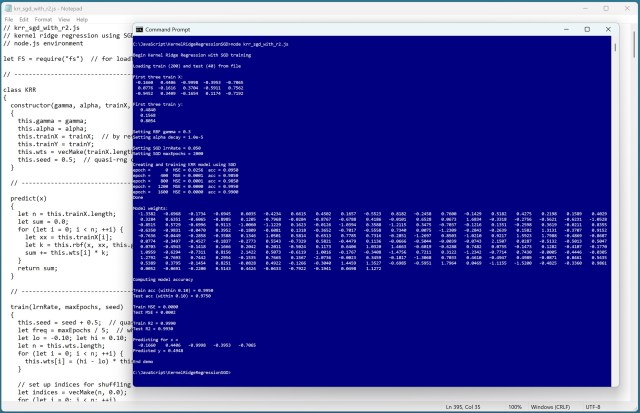
Реалізація регресії ядра в JavaScript тепер включає коефіцієнт детермінації R2 для оцінки моделі, демонструючи вражаючі результати в точності та MSE. Демо-версія із синтетичними даними демонструє ефективність оновленої моделі KRR, досягаючи високої точності та значень R2.
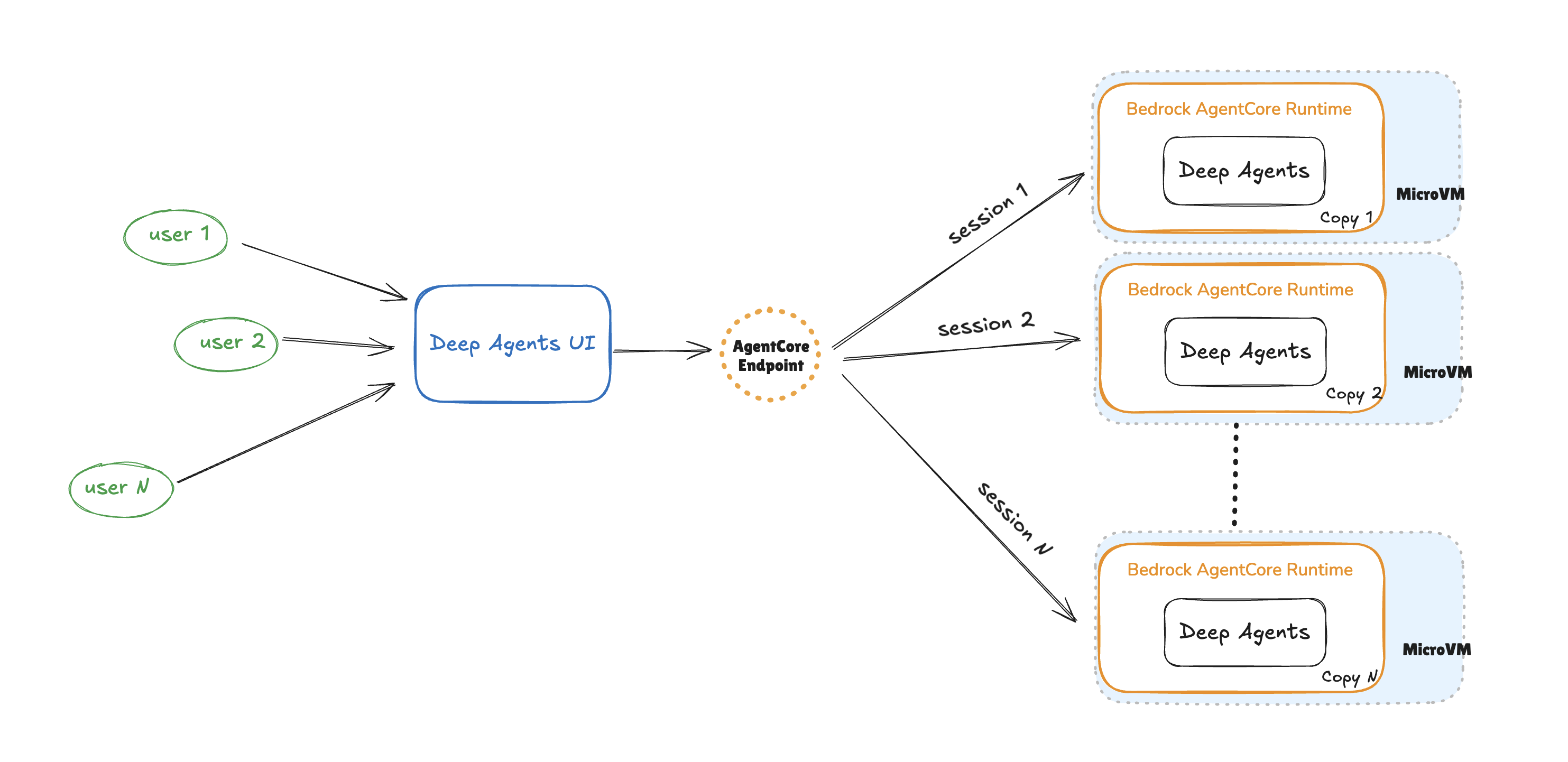
Агенти штучного інтелекту просуваються вперед, щоб співпрацювати над складними завданнями. Amazon Bedrock AgentCore Runtime забезпечує безпечне та масштабоване розгортання Deep Agents для використання в підприємствах, зменшуючи витрати на управління інфраструктурою.
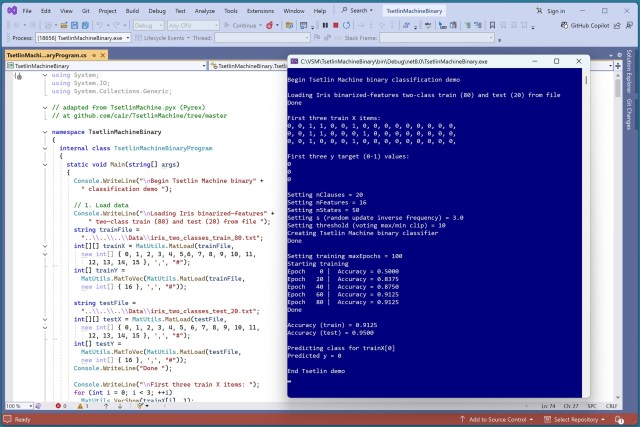
Бінарна класифікація за методом Цетліна — це унікальна техніка, названа на честь радянського математика. Система демонструє високу точність у прогнозуванні видів квітів ірису.
Британці побоюються економічного впливу штучного інтелекту, повідомляє аналітичний центр Тоні Блера

Дані опитування TBI показують, що британці розглядають ШІ як ризик, а не як можливість, що загрожує амбіціям Кіра Стармера щодо «надпотужності» ШІ. Інститут Тоні Блера закликає уряд переконати громадськість у перевагах ШІ.

Компанія Nvidia планує інвестувати до 100 мільярдів доларів у компанію OpenAI, надаючи чіпи для центрів обробки даних в рамках важливої співпраці у сфері штучного інтелекту. Угода передбачає дві транзакції: компанія OpenAI оплачує Nvidia за чіпи, а Nvidia інвестує в стартап, що займається розробкою технологій штучного інтелекту.

Еліезер Юдковський і Нейт Соарес попереджають про те, що надрозумний штучний інтелект може призвести до вимирання людства. Прогнози катастрофічних наслідків викликають занепокоєння щодо майбутнього.

Центр підприємництва Мартіна Траста при Массачусетському технологічному інституті використовує штучний інтелект як новий інструмент для стартапів. Студенти використовують штучний інтелект для прискорення кодування, мозкового штурму та прийняття бізнес-рішень, пам'ятаючи про його обмеження.

Керівник кліматичного відділу ООН наголошує на необхідності державного регулювання штучного інтелекту для вирішення кліматичної кризи. Штучний інтелект сприяє підвищенню ефективності енергетичних систем та зменшенню викидів вуглецю в промислових процесах.
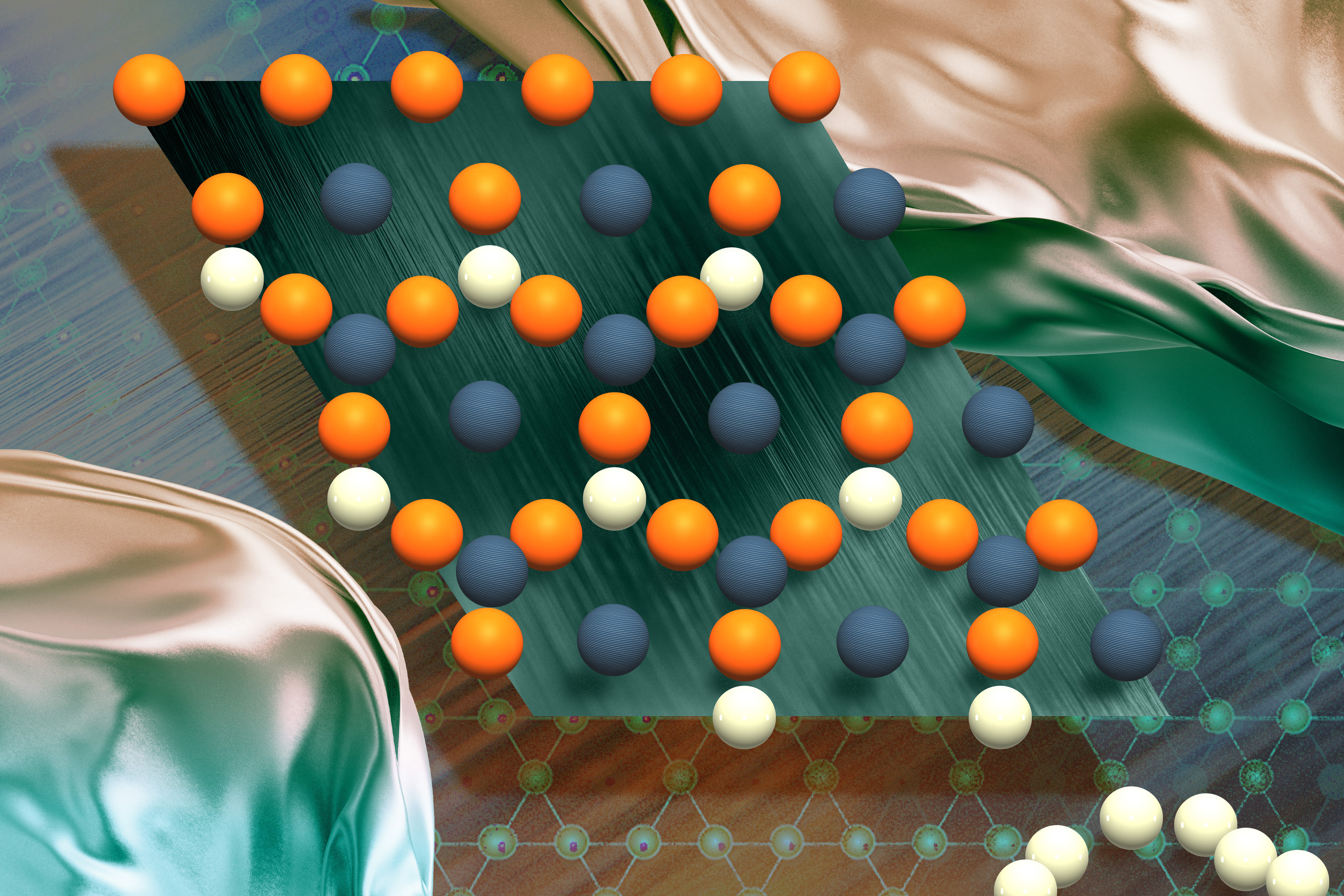
Моделі штучного інтелекту від Google, Microsoft і Meta тепер можуть проектувати квантові матеріали з екзотичними властивостями, сприяючи розвитку квантових обчислень. Дослідники з Массачусетського технологічного інституту розробили техніку, що використовує специфічні правила проектування для створення перспективних матеріалів з унікальною структурою, про що було опубліковано в журналі Nature M...

Дослідники MIT Роу і Сазерленд отримали гранти AI for Math для вдосконалення доведення теорем шляхом об'єднання LMFDB і mathlib. Їхній проект спрямований на подолання розриву між неформалізованими математичними знаннями та формальними системами доведення, що принесе користь як математикам-людям, так і агентам штучного інтелекту.

Організація з охорони прав дітей закликає розробників моделей штучного інтелекту включити в них правила захисту дітей після скандалу з чат-ботом, в якому фігурували персонажі-підлітки. Звіт спонукає уряд Великої Британії ввести правила безпеки для компаній, що розробляють штучний інтелект, через зростання кількості матеріалів із сексуальним насильством над дітьми (CSAM), що генеруються за допо...

Дженсен Хуанг з Nvidia радить міністрам Великобританії надати пріоритет економічним вигодам генеративної штучної інтелекту над енергетичними проблемами центрів обробки даних. Підкреслює необхідність зростання енергетики для підтримки нових галузей промисловості, включаючи такі стійкі варіанти, як атомна, вітрова, сонячна енергетика та газові турбіни.