
Бібліотека NVIDIA RAPIDS cuDF прискорює панди до 100 разів на апаратному забезпеченні RTX, покращуючи швидкість обробки даних для дослідників даних. Завдяки бібліотекам Python з GPU-прискоренням RAPIDS cuDF фахівці з даних тепер можуть використовувати свою улюблену кодову базу без втрати ефективності.

Blackstone Group профінансує центр обробки даних штучного інтелекту вартістю 10 мільярдів фунтів стерлінгів, який створить 4 000 робочих місць на північному сході Англії. Кейр Стармер оголосив про проект, підтриманий прихильником Дональда Трампа, що підвищує інвестиційну привабливість Великобританії.
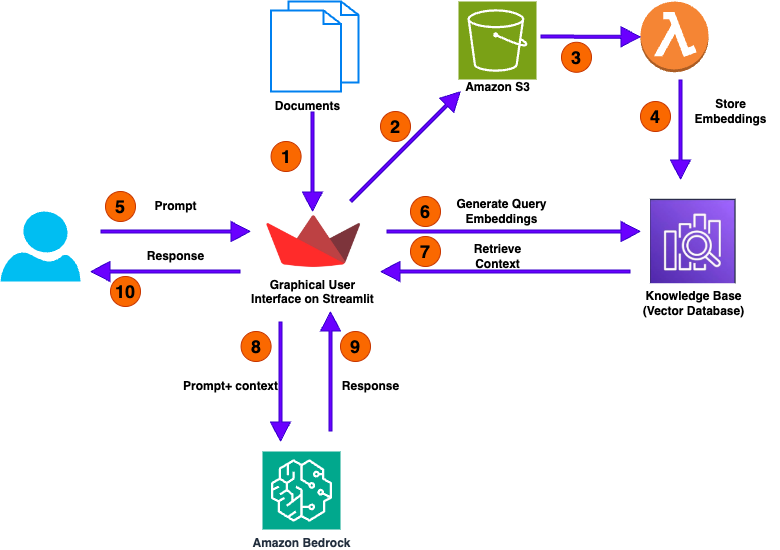
Amazon Bedrock пропонує високопродуктивні FM для генеративних додатків зі штучним інтелектом. RAG в Amazon Bedrock вирішує проблеми чисельного аналізу.

Алгоритм регресії: Розкриття сили фіктивного регресора. Дослідіть значення цієї простої моделі для оцінки ефективності машинного навчання.

Програмне забезпечення зі штучним інтелектом з базою даних 380 000 зображень змій допомагає швидко ідентифікувати їх для точного застосування протиотрути. MSF випробовує ШІ-розпізнавання змій у Південному Судані, щоб покращити лікування пацієнтів, які постраждали від укусів змій.

Марк Цукерберг представив окуляри доповненої реальності Orion, які проектують цифровий контент на реальний світ. Meta AI з голосом Джуді Денч, що знаменує перехід від традиційних пристроїв до «розумних» окулярів.

Технічний директор OpenAI, Міра Мураті, покидає компанію після того, як очолила розробника ChatGPT. Причиною звільнення Мураті називає особисті пошуки.

Поширені запитання щодо тонкого налаштування LLM: Зрозумійте нюанси точного налаштування великих мовних моделей і коли це ефективно використовувати в проектах зі штучного інтелекту. Точне налаштування може знизити витрати на висновок і адаптувати результати моделювання за допомогою швидкого інжинірингу, але його ефективність залежить від сценарію використання та обсягу даних.

ChatGPT-4o від OpenAI представляє функції «Advanced Voice», що демонструють природні розмовні здібності. Користувачі були вражені схожим на людський темпом і швидкими відповідями, що стирає межі між ШІ та свідомістю.
Моделі Llama 3.2 з можливостями машинного зору тепер доступні в Amazon SageMaker JumpStart і Amazon Bedrock, розширюючи їхні традиційні текстові додатки. Ці найсучасніші генеративні моделі ШІ пропонують покращену продуктивність, багатомовну підтримку та підходять для широкого спектру завдань, що базуються на зоровому аналізі.

В ChatGPT від OpenAI була виявлена уразливість в пам'яті, якою скористався дослідник Йоганн Ребергер (Johann Rehberger), щоб викрасти дані, введені користувачем. Функція зберігання попередніх розмов для контексту викликала занепокоєння, але її було частково виправлено.

Системи штучного інтелекту в охороні здоров'я можуть робити упереджені прогнози або галюцинувати неправдиву інформацію. Професори Массачусетського технологічного інституту та Бостонського університету пропонують запровадити етикетки відповідального використання, щоб зменшити потенційну шкоду та забезпечити прозорість систем штучного інтелекту, подібно до етикеток на рецептурних ліках, які вима...

IRCAI, Zindi та AWS запустили конкурс «AI for Equity Challenge», присвячений питанням клімату, гендеру та охорони здоров'я. Глобальний конкурс має на меті розширити можливості організацій, які використовують ШІ на благо вразливих верств населення.
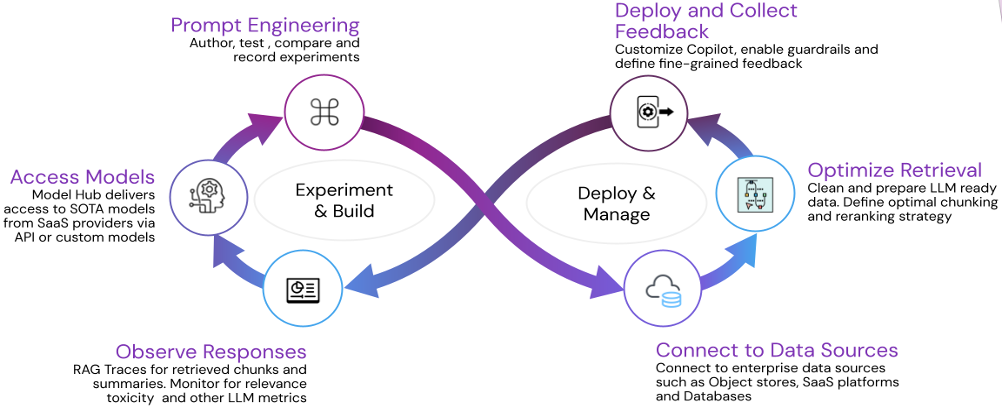
Karini AI пропонує зручну платформу GenAI для підприємств для створення та розгортання передових додатків генеративного ШІ, що виходять за рамки чат-ботів. Платформа без коду включає оцінку якості, оперативне управління та конвеєр прийому даних для ефективного розгортання та моніторингу, що призводить до покращення паралелізму та економії коштів.

Нагородами 2024 R&D 100 від Лабораторії Лінкольна Массачусетського технологічного інституту відзначено 15 інноваційних технологій, серед яких картування мозку за допомогою штучного інтелекту та моніторинг впливу вибухів. Ці технології демонструють різноманітні можливості лабораторії та її вплив на реальний світ - від запобігання шкоді для людини до розвитку 3D-друку та інтегральних схем.