
ШІ виявив 303 нових геогліфи поблизу ліній Наска в Перу, що подвоює відомі цифри на цьому 2000-річному об'єкті. Співпраця між Університетом Ямагата та IBM Research дозволила виявити зображення тварин і людей, датовані 200 роком до нашої ери.

Дізнайтеся, як створити планувальник харчування за допомогою ChatGPT на Python, спростивши рішення щодо харчування та покупок продуктів. Використовуйте методи швидкого проектування, щоб максимізувати можливості ChatGPT, роблячи планування харчування простішим та ефективнішим.

Платформа хостингу штучного інтелекту Hugging Face налічує 1 мільйон списків моделей штучного інтелекту, пропонуючи кастомізацію для спеціалізованих завдань. Генеральний директор Delangue підкреслює важливість адаптованих моделей для окремих випадків використання, підкреслюючи універсальність платформи.

Остерігайтеся публікувати в соціальних мережах пости, які забороняють Meta доступ до ваших даних. Такі знаменитості, як Джеймс МакЕвой і Том Бреді, приєднуються до цієї тенденції.

Токенізація має вирішальне значення в НЛП для з'єднання людської мови та машинного розуміння, дозволяючи комп'ютерам ефективно обробляти текст. Великі мовні моделі, такі як ChatGPT і Claude, використовують токенізацію для перетворення тексту в числове представлення для отримання змістовних результатів.
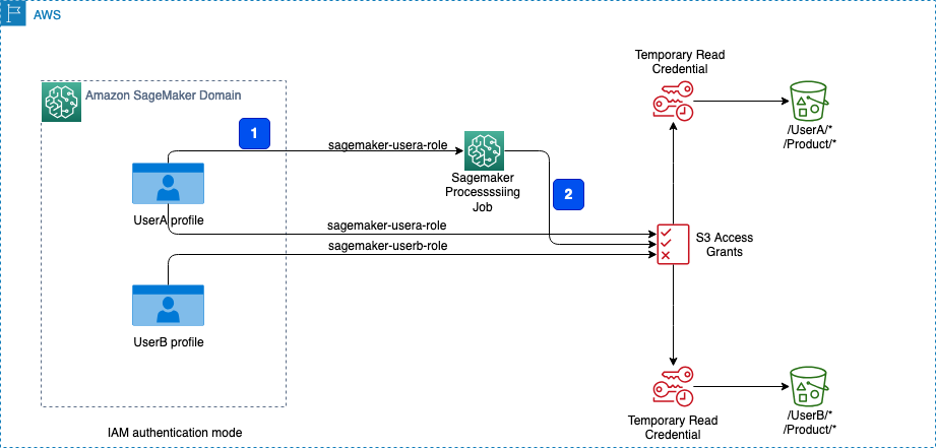
Amazon SageMaker Studio пропонує уніфікований інтерфейс для аналітиків даних, інженерів машинного навчання та розробників для побудови, навчання та моніторингу моделей машинного навчання з використанням даних Amazon S3. S3 Access Grants спрощує управління доступом до даних без необхідності частого оновлення ролей IAM, надаючи гранульовані дозволи на рівні бакетів, префіксів або об'єктів.

В АІ-версії рецензії Брайана Сьюелла відсутній його автентичний голос, що розчаровує читачів. Розкішного голосу та унікального стилю Сьюелла дуже бракує у спробі London Standard відтворити його стиль.

Проект Tor і Tails об'єднуються, щоб посилити зусилля по забезпеченню анонімності в Інтернеті. Tails отримає вигоду від операційної структури Tor, що дозволить їм зосередитися на вдосконаленні своєї ОС.

Дослідники Массачусетського технологічного інституту розробили квантовий протокол безпеки для хмарних моделей глибокого навчання, який забезпечує конфіденційність даних без шкоди для точності. Протокол використовує принцип квантової механіки, що не допускає клонування, щоб запобігти перехопленню інформації зловмисниками, зберігаючи 96-відсоткову точність у тестах.

ФБР досліджує штучний інтелект, який імітує Дмитра Кулебу під час допиту сенатора Бена Кардіна, що викликає занепокоєння щодо втручання у вибори. Інцидент з імітацією під час Zoom-дзвінка викликає занепокоєння щодо ризиків політичних маніпуляцій.

Штучний інтелект викликає паніку через комп'ютерне домінування, але справжня небезпека криється в хайпі. Автор: Навніт Аланґ.
Стаття: «Логістична регресія з пакетним навчанням SGD та розкладанням ваги за допомогою C#». Вона пояснює, як логістична регресія легко реалізується, добре працює з малими і великими наборами даних і дає результати, які легко інтерпретуються. У демонстраційній програмі використовується стохастичний градієнтний спуск з пакетним навчанням і спаданням ваги для точних прогнозів.
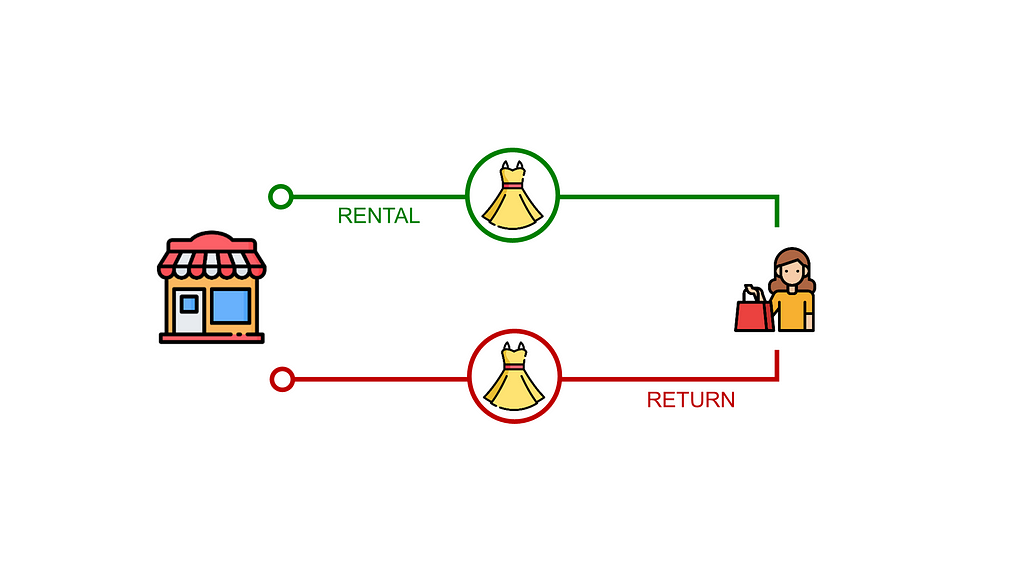
Роздрібний продавець модного одягу досліджує модель циркулярної оренди з використанням аналітики даних, щоб зменшити вплив на навколишнє середовище та підвищити ефективність використання ресурсів. Data scientist оцінює операційні виклики та показники, що мають вирішальне значення для переходу до циркулярної економіки, допомагаючи командам зі сталого розвитку та логістики у створенні переконлив...

Відомий ШІ-художник Рефік Анадол відкриє Dataland, перший у світі музей мистецтва штучного інтелекту в Лос-Анджелесі, присвячений «етичному ШІ» та відновлюваній енергетиці. Dataland дебютує у 2025 році поруч із провідними культурними центрами, демонструючи поєднання людської творчості та потенціалу машин.

Інженер з машинного навчання та кандидат наук провели специфічний для Нідерландів бенчмаркінг LLM, порівнюючи такі моделі, як o1-preview та GPT-4o, з реальними голландськими екзаменаційними питаннями. Дослідження підкреслює важливість перевірки моделей штучного інтелекту для голландськомовних завдань і пропонує цінну інформацію для компаній, націлених на голландський ринок.