
OpenAI обмежує доступ до ChatGPT для користувачів віком до 18 років після судового позову. Генеральний директор Сем Альтман ставить безпеку підлітків вище за конфіденційність.

Meta представляє смарт-окуляри Meta Ray-Ban Display з вбудованим екраном для AR, класичним дизайном, камерою, динаміками та мікрофоном. Перший мейнстрім-бренд, який пропонує дисплей з проекцією інформації на окуляри після Google Glass, дозволяє здійснювати переклад, відображати інформацію та вказівки.

Дженсен Хуанг з Nvidia інвестує 500 млн фунтів стерлінгів у британську компанію NScale, прогнозуючи, що Великобританія стане майбутньою супердержавою в галузі штучного інтелекту з потенційним доходом у 50 млрд фунтів стерлінгів. Хуанг підкреслює потенціал Великобританії в галузі штучного інтелекту, придбавши частку в британській компанії, що займається хмарними обчисленнями.

Дослідники з MIT та MIT-IBM Watson AI Lab розробили посібник з вибору невеликих моделей та оцінки законів масштабування для великих мовних моделей, оптимізуючи розподіл бюджету для надійних прогнозів продуктивності. Закони масштабування дозволяють приймати кращі рішення щодо попереднього навчання та демократизують цю галузь, даючи можливість дослідникам, які не мають великих ресурсів, розуміти...

Масштабні прибутки Palantir у другому кварталі демонструють вплив штучного інтелекту на економіку, обіцяючи безпрецедентний ріст та ефективність. Революція штучного інтелекту, яку підтримують такі технологічні гіганти, як Palantir, має потенціал перетворити наш світ та стимулювати економічний прогрес.
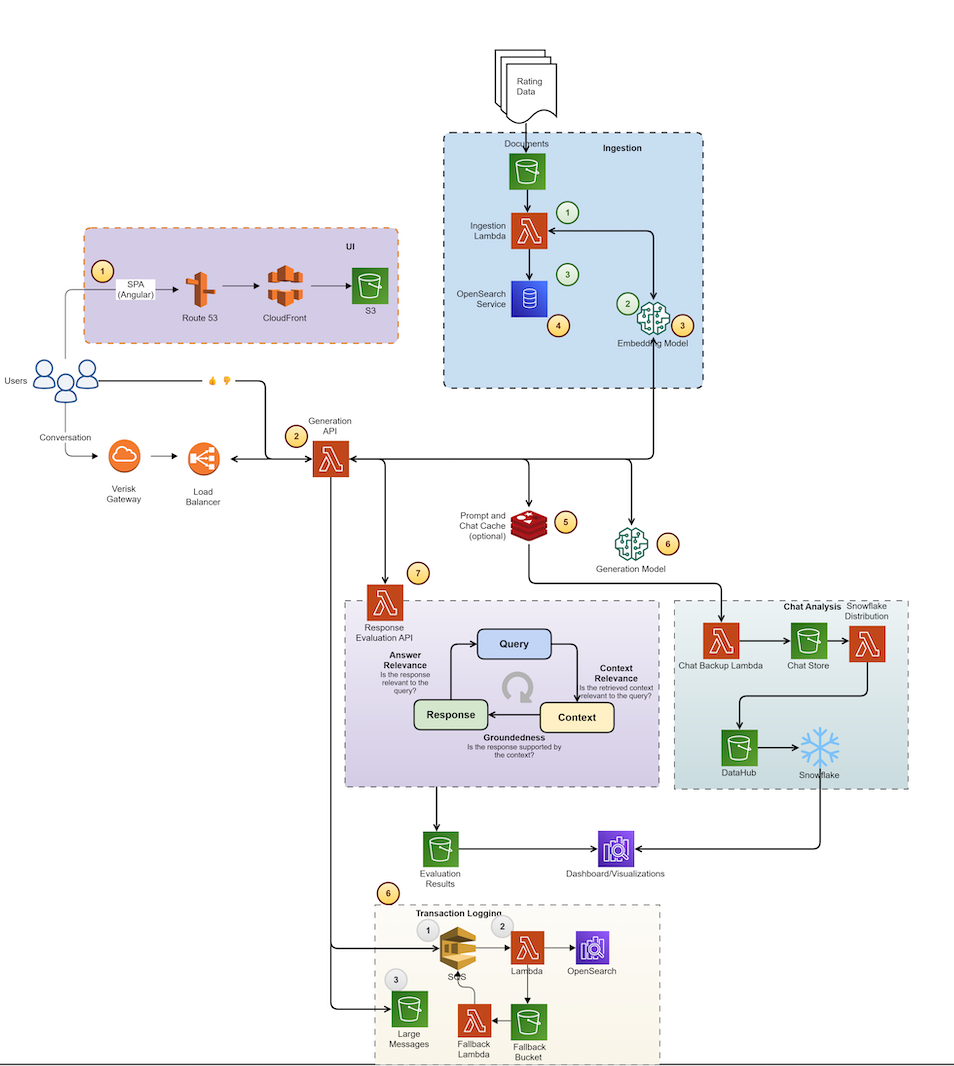
Rating Insights від Verisk, що працює на базі Amazon Bedrock та генеративної штучної інтелекту, оптимізує аналіз змін ISO ERC, покращуючи доступність для користувачів та оперативну ефективність. Проблеми ручного завантаження та неефективного пошуку даних вирішуються за допомогою діалогового інтерфейсу користувача, що скорочує час аналізу та покращує підтримку клієнтів.

Штучний інтелект перетворить творчість на здійснення мрій, залишивши майбутнім поколінням відчуття порожнечі. Класичні казки застерігають від небезпеки бажати того, на що не маєш права.

Британські артисти, такі як Пол Маккартні, Кейт Буш та Елтон Джон, попереджають, що пропозиції Лейбористської партії щодо штучного інтелекту можуть призвести до крадіжки творів мистецтва. Вони закликають Кіра Стармера захистити права творців на тлі побоювань щодо використання компаніями, що займаються штучним інтелектом, матеріалів, захищених авторським правом, без згоди авторів.

AWS Generative AI Innovation Center та Quora співпрацюють з метою оптимізації розгортання мультимодельних рішень за допомогою уніфікованої інфраструктури API-обгортки, що скорочує час розгортання та інженерні зусилля. Система Poe від Quora інтегрує понад 30 моделей Amazon Bedrock, демонструючи зручну для користувача платформу штучного інтелекту з різноманітними можливостями.
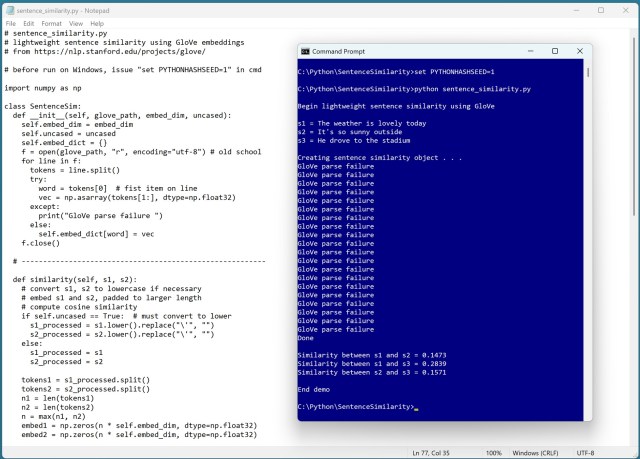
Розчарований складними залежностями, автор спростив подібність речень за допомогою базової демонстрації Python з використанням вбудованих GloVe. Незважаючи на труднощі, демонстрація успішно порівняла речення, виявивши несподівані подібності на основі підрахунку слів.

Google інвестує 5 млрд фунтів стерлінгів у Великобританію протягом 2 років у послуги штучного інтелекту, відкривши центр обробки даних у графстві Хартфордшир. Очікується, що це створить тисячі робочих місць і сприятиме розвитку британської економіки, — Рейчел Рівз.
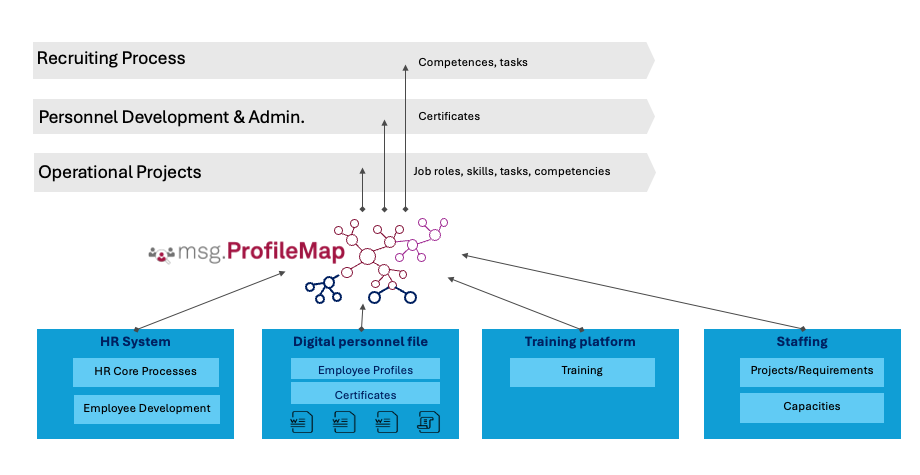
msg пропонує ProfileMap, SaaS-рішення для управління навичками, яке допомагає відділам кадрів у плануванні робочої сили та підборі персоналу для проектів. Завдяки автоматизації гармонізації даних за допомогою Amazon Bedrock, msg підвищує точність, зменшує обсяг ручної роботи та забезпечує відповідність вимогам Закону ЄС про штучний інтелект та GDPR.
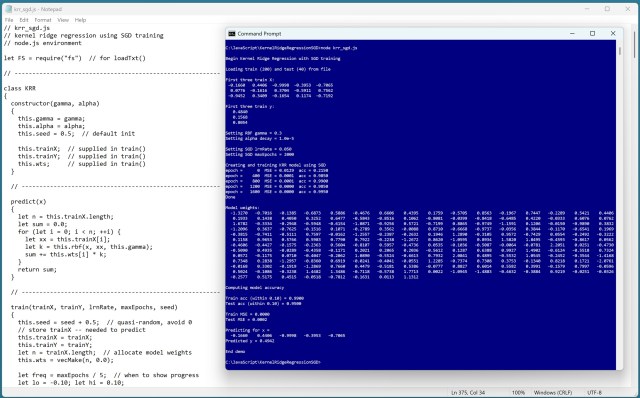
Регресія з використанням ядра (KRR) прогнозує значення за допомогою функцій ядра для нелінійних даних. Ітеративна техніка, що використовує стохастичний градієнтний спуск, дозволяє ефективно навчати моделі KRR для великих наборів даних.
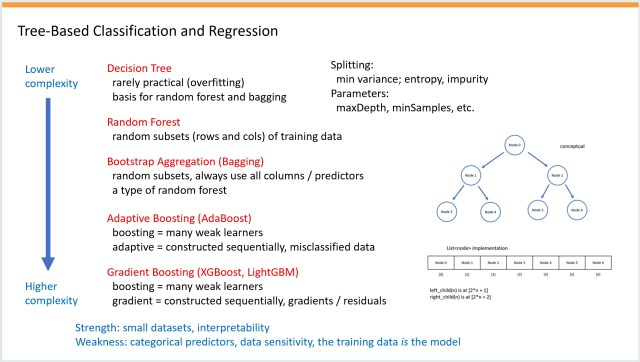
Короткий зміст: Детальна презентація PowerPoint про нейронні мережі, що еволюціонували до включення деревних методів. Також розглядаються та оцінюються три сюжети науково-фантастичних фільмів, пов'язані з пам'яттю.

Виховання Сун-Чуна Чжу в сільській місцевості Китаю під час Культурної революції сформувало його пристрасть до штучного інтелекту. Його переїзд до Китаю в 2020 році може вплинути на глобальну гонку в галузі штучного інтелекту.