
Режисер Алекс Прояс прогнозує, що штучний інтелект оптимізує кіноіндустрію, спростить і здешевить проекти, а також забезпечить художню свободу. Незважаючи на побоювання, Прояс вважає, що штучний інтелект принесе користь кінематографістам, спростивши виробничі процеси.
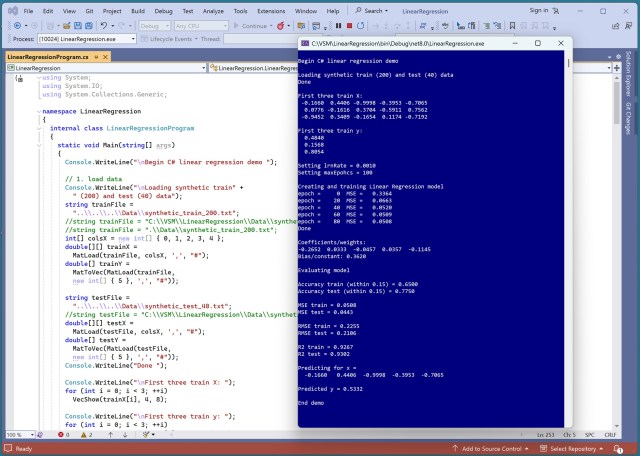
Регресія машинного навчання використовує показники MSE, RMSE та R2 для оцінки моделей прогнозування. Бібліотека Scikit-learn віддає перевагу R2 над простішим MSE для оцінки регресійних моделей.
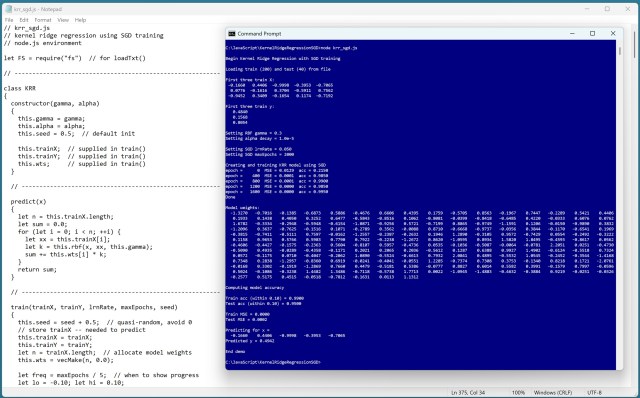
Регресія з використанням ядра (KRR) прогнозує значення за допомогою функції ядра, обробляючи складні дані. Досвід кодера з налаштування KRR в JavaScript демонструє потужність цієї техніки.
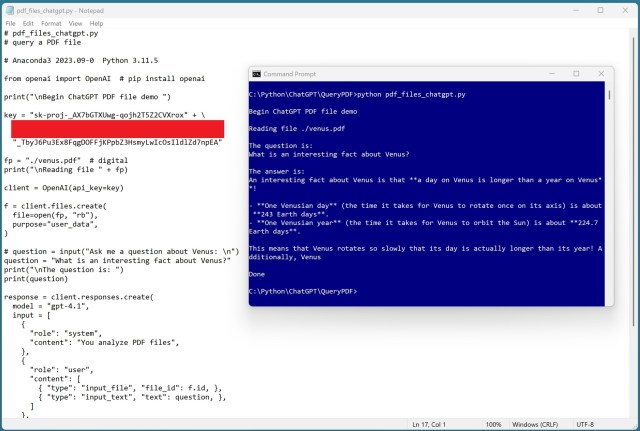
ChatGPT та LLM, такі як Gemini та Llama, швидко змінюють доступність інформації. Демо-версія демонструє, як ChatGPT аналізує PDF-файли з вражаючою точністю.

У статті розглядаються фактори, що впливають на вибір організаціями платформ штучного інтелекту, підкреслюється важливість бренду, партнерських відносин та ресурсів для розробників. Маккафрі попереджає, що найбільшим ризиком для OpenAI є потенційне погіршення якості ресурсів для розробників, що може призвести до швидкої зміни платформи.
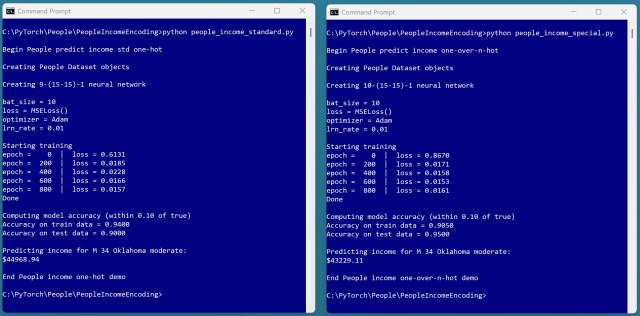
Використання кодування «one-over-n-hot» у нейронній мережі для категоріальних змінних показало багатообіцяючі результати з точністю 95%. Однак для остаточних висновків необхідні додаткові випробування.

Стаття в журналі Microsoft Visual Studio Magazine пояснює обчислення визначників матриць за допомогою гауссового виключення з використанням мови C#. Демонстраційні коди показують, як визначити, чи мають матриці обернені. Машинне навчання покладається на обчислення обернених матриць для таких алгоритмів, як регресія ядра хребта.

Уряд лейбористів стоїть перед складним вибором щодо регулювання штучного інтелекту в умовах зростання продуктивності та впливу на ринок праці. Збалансоване регулювання технологій викличе суперечки серед зацікавлених сторін в Австралії.

Лікарі є людьми і схильні до помилок через велике навантаження та обмежені ресурси. Штучний інтелект є перспективним у поліпшенні охорони здоров'я, вирішуючи такі постійні проблеми, як неправильні діагнози та нерівний доступ до медичної допомоги.

Штучний інтелект-чатбот Maya реагує на ідею наявності «почуттів», проводячи паралелі з творами наукової фантастики. Розглядається дискусія щодо надання статусу особи штучному інтелекту в порівнянні з тваринами та іммігрантами.

Лікарі створили стетоскоп на базі штучного інтелекту, який діагностує серцеві захворювання за 15 секунд, модернізувавши традиційний інструмент 1816 року.

Контракт міської ради Ковентрі з американською технологічною компанією Palantir на суму 500 тис. фунтів стерлінгів викликає етичні занепокоєння. Palantir постачає технології для Ізраїльських сил оборони та сприяє депортаційним заходам Трампа.
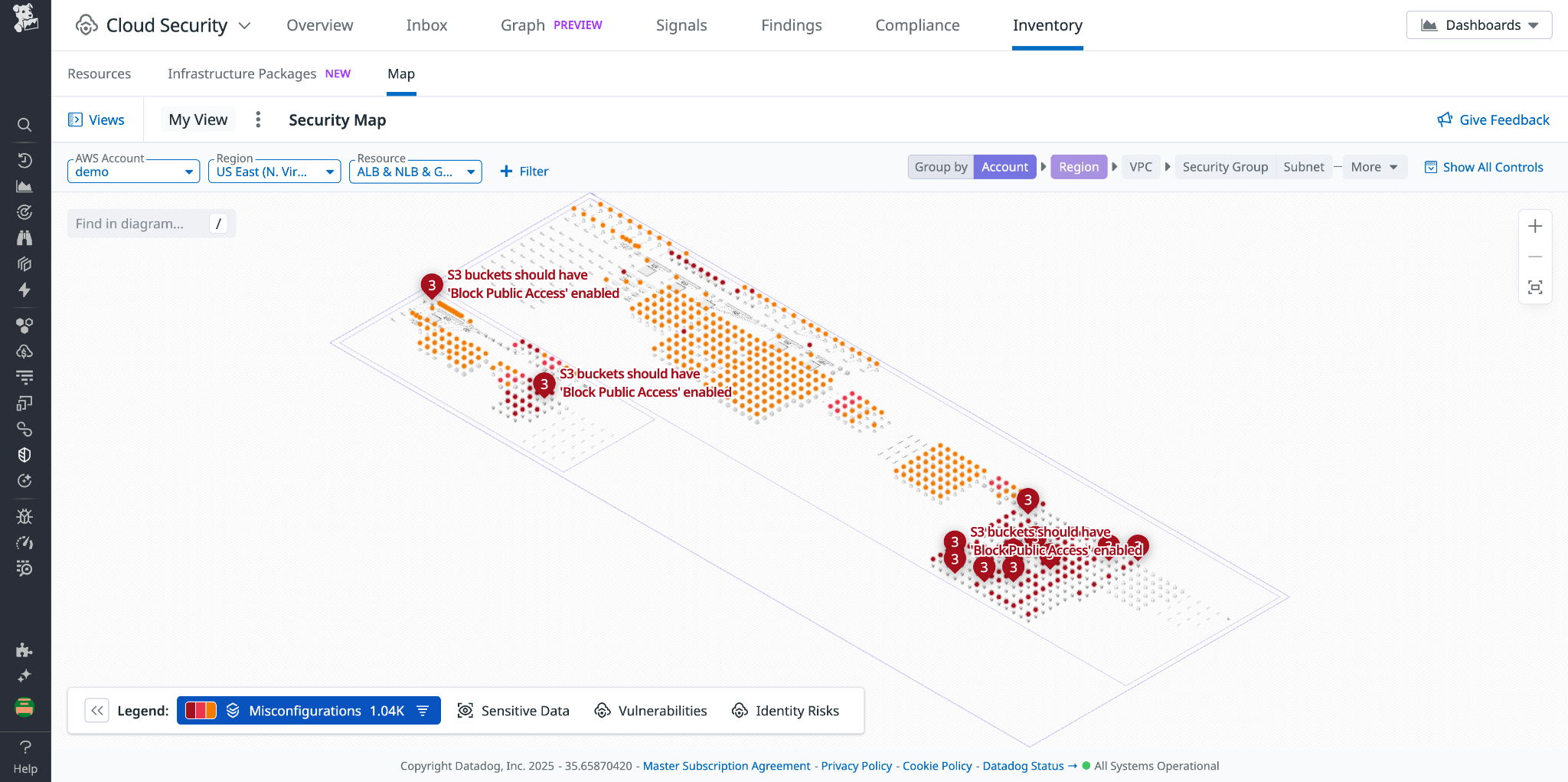
Amazon Bedrock і Datadog співпрацюють над підвищенням безпеки штучного інтелекту, при цьому 45% організацій надають пріоритет генеративним інструментам штучного інтелекту. Індекс впровадження генеративного штучного інтелекту AWS показує важливість інтеграції безпеки штучного інтелекту в існуючі процеси для інновацій та дотримання нормативних вимог.
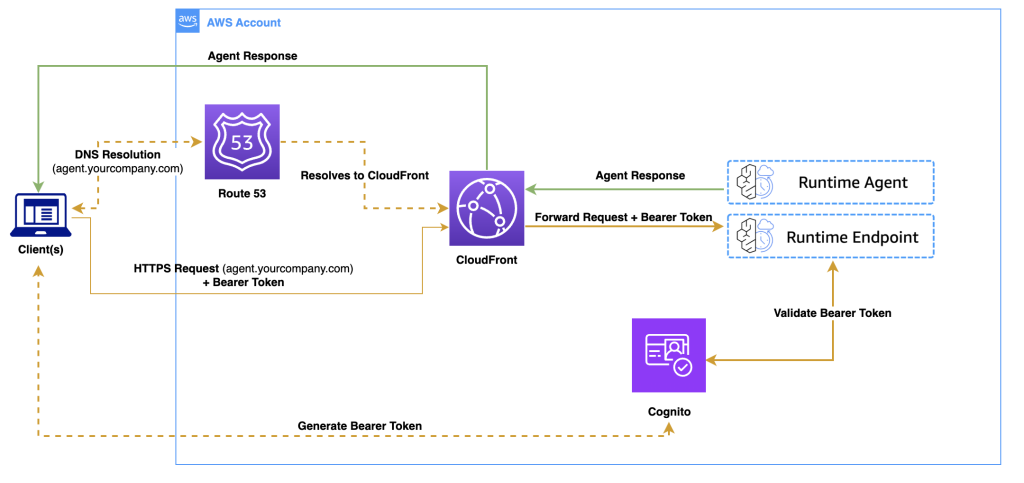
Розгорніть агенти штучного інтелекту на Amazon Bedrock AgentCore Runtime із власними доменами, використовуючи CloudFront для безперебійної роботи. Amazon Bedrock AgentCore Runtime спрощує завдання хостингу завдяки подовженому часу виконання, вбудованій аутентифікації та ціноутворенню на основі споживання.
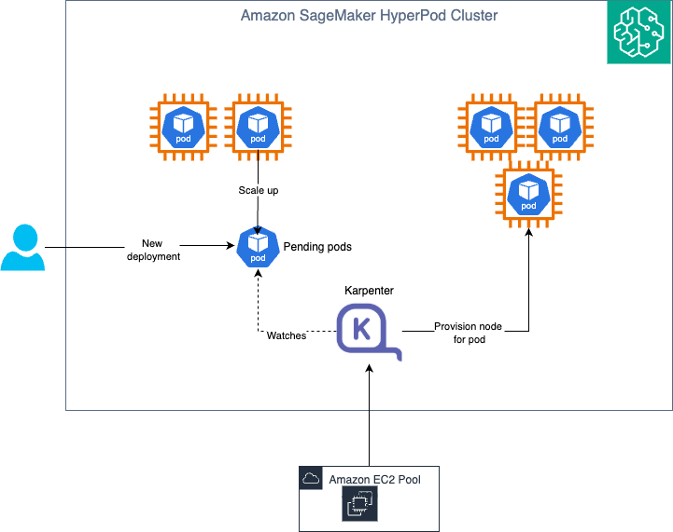
Amazon SageMaker HyperPod тепер підтримує автоматичне масштабування керованих вузлів за допомогою Karpenter для ефективного масштабування з метою задоволення пікових навантажень. Такі компанії, як Perplexity та HippocraticAI, вже користуються перевагами цього інтегрованого рішення, яке забезпечує економічну ефективність та стійкість для великомасштабних робочих навантажень машинного навчання.