
Синтетичні дані викликають занепокоєння щодо колапсу моделей при розробці ШІ, але дослідження можуть не відображати реальні практики та досягнення. Відсутність стандартних методів пом'якшення наслідків і контролю якості в дослідженні обмежує його застосовність до галузевих сценаріїв.
RAG поєднує в собі моделі пошуку та фундаментальні моделі для потужних систем відповідей на запитання. Автоматизуйте розгортання RAG за допомогою Amazon Bedrock та AWS CloudFormation для безперешкодного налаштування.

Ілон Маск подав до суду на генерального директора OpenAI Сема Альтмана, звинувативши його в маніпуляціях зі співзасновництвом компанії. Судова битва розгорілася з новим позовом до суду Північної Каліфорнії.
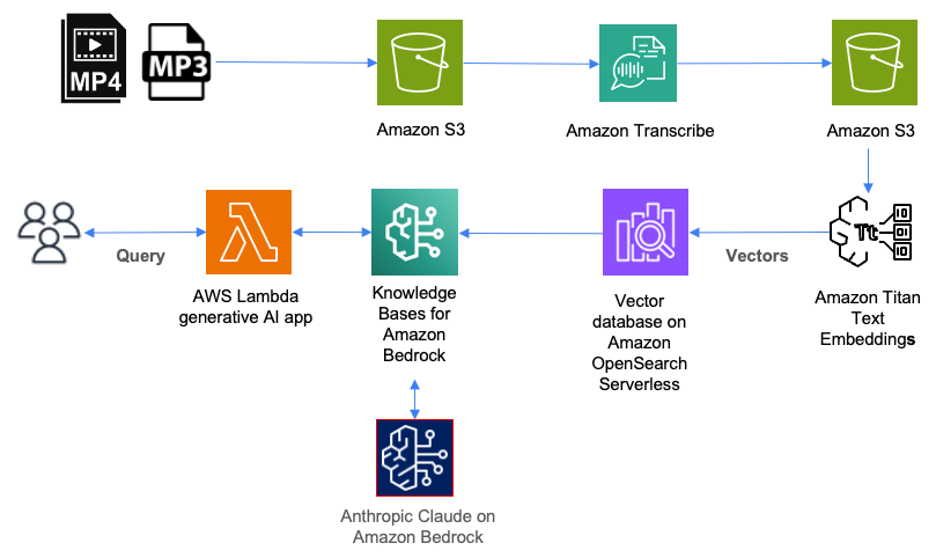
Інформаційно-пошукові системи розвиваються завдяки рішенням зі штучним інтелектом, таким як Amazon Transcribe та Amazon Bedrock, для ефективного пошуку аудіофайлів у великих масштабах. Ці сервіси спрощують процес транскрибування аудіо, каталогізації контенту та створення вбудовувань для зручного пошуку.
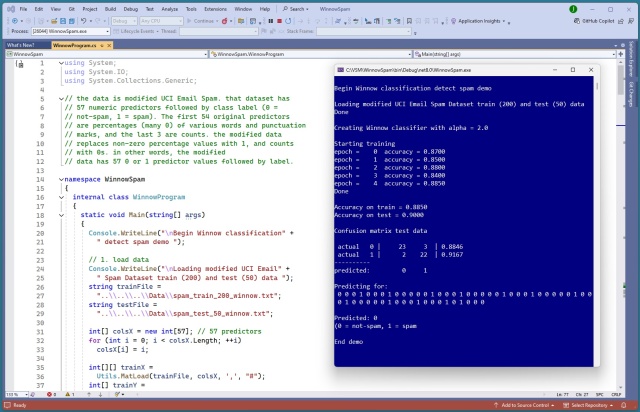
Бінарна класифікація Winnow призначена для бінарних предикторних змінних і міток. Приклад з використанням модифікованого набору даних UCI про спам в електронній пошті демонструє унікальний алгоритм Winnow в дії.
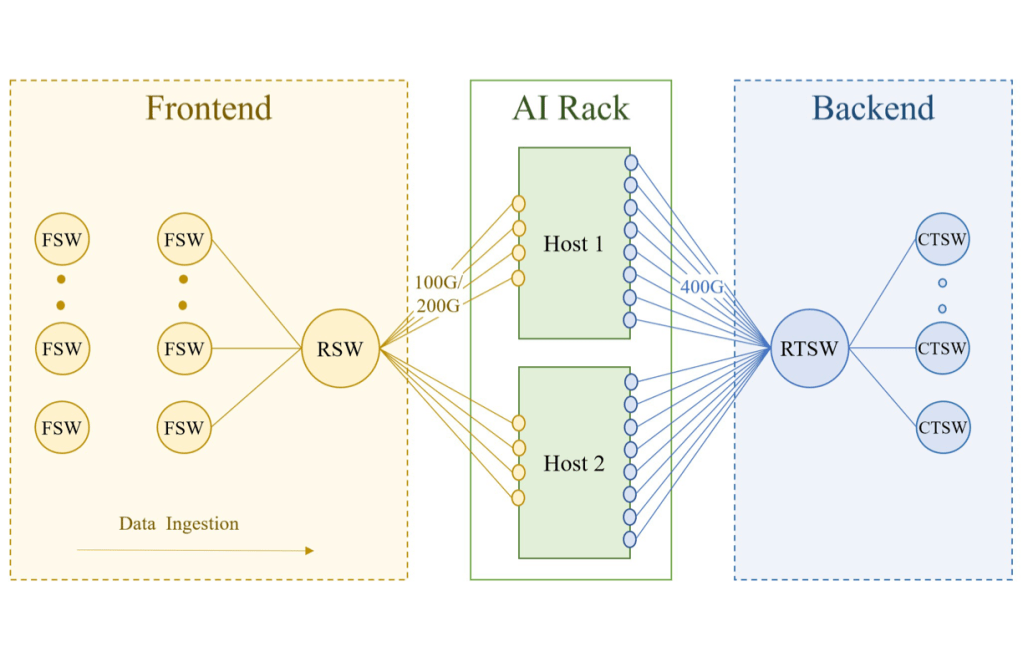
Мережі ШІ мають вирішальне значення для широкомасштабного розподіленого навчання в Meta, використовуючи RDMA через Ethernet для високопродуктивного зв'язку. Спеціалізовані мережі центрів обробки даних вміщують тисячі графічних процесорів для різних робочих навантажень ШІ, забезпечуючи надійний транспорт з низькою затримкою.

ШІ може створювати зображення і звуки одночасно, наприклад, гавкіт коргі. Дослідники з Мічиганського університету вивчають цю революційну концепцію.
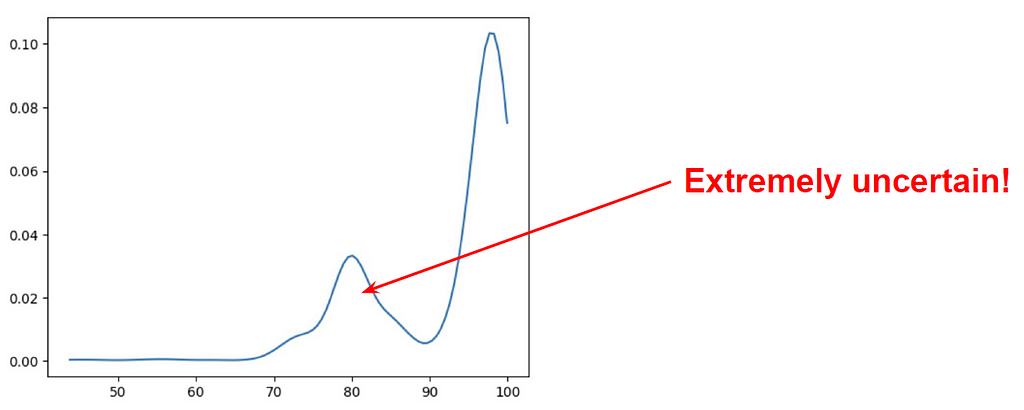
Підказки LLM показують крихкість відповідей ШІ. Експеримент з GPT-4o від OpenAI показав 55% точність у порівнянні з оригінальною підказкою.
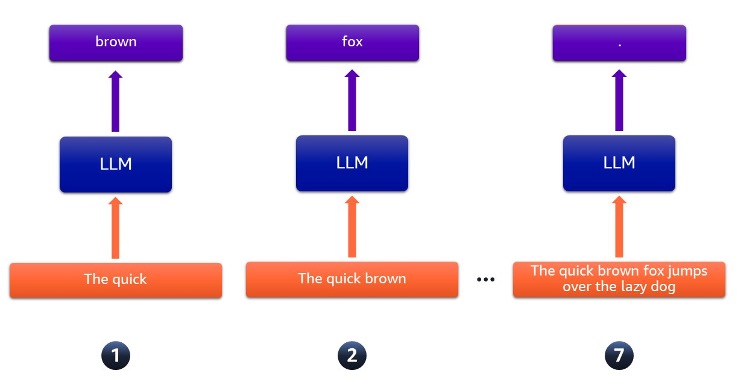
Великі мовні моделі (ВММ) збільшуються в розмірах для отримання кращих результатів, але при цьому зростають обчислювальні вимоги. Спекулятивна вибірка підвищує ефективність завдяки паралельній перевірці декількох токенів, що покращує використання апаратних ресурсів.

Підроблений штучний вокал, зокрема Дональда Трампа, руйнує сцену клатчу в Монтего-Бей, викликаючи дебати про майбутнє культури. Використання вокалістів зі штучним інтелектом кидає виклик автентичності та оригінальності в історичній традиції Sumfest Global Sound Clash.

Короткий зміст: Дізнайтеся, як побудувати 124M GPT2 модель за допомогою Jax для ефективного навчання, порівняти її з Pytorch та дослідити ключові можливості Jax, такі як JIT-компіляція та Autograd. Відтворіть NanoGPT за допомогою Jax та порівняйте кількість токенів/сек навчання на декількох графічних процесорах між Pytorch та Jax.

ChatGPT Сема Альтмана привертає увагу світової спільноти, викликаючи манію штучного інтелекту. Але вчений попереджає про небезпеку, яку несуть Альтман і ШІ.

Вплив штучного інтелекту на суспільство спонукає до запитання: Як зробити так, щоб ШІ приносив користь людству? Вивчення зв'язку між процвітанням людства та розвитком штучного інтелекту виявляє потребу в суспільній інфраструктурі, яка сприятиме добробуту.

Деніел Бедінгфілд стверджує, що штучний інтелект - це майбутнє музики, і попереджає, що "неолуддити" ризикують залишитися позаду з розвитком технологій. Такі артисти, як Біллі Ейліш і Кеті Перрі, висловлювали занепокоєння щодо впливу ШІ на творчість.

LLM можуть передбачати метадані для гуманітарних наборів даних без точного налаштування, пропонуючи ефективні та точні результати. GPT-4o демонструє перспективність у прогнозуванні тегів і атрибутів HXL, спрощуючи обробку даних для гуманітарних зусиль.