
Компанія NVIDIA представляє RTX Spark — суперчіп для ПК на базі Windows, що забезпечує покращений ігровий досвід завдяки технологіям штучного інтелекту та трасування променів. Співпраця з провідними корейськими розробниками ігор, зокрема KRAFTON та NC, спрямована на те, щоб зробити популярні ігри доступними для систем на базі RTX Spark, що викликає великий ажіотаж у ігровому співтоваристві.
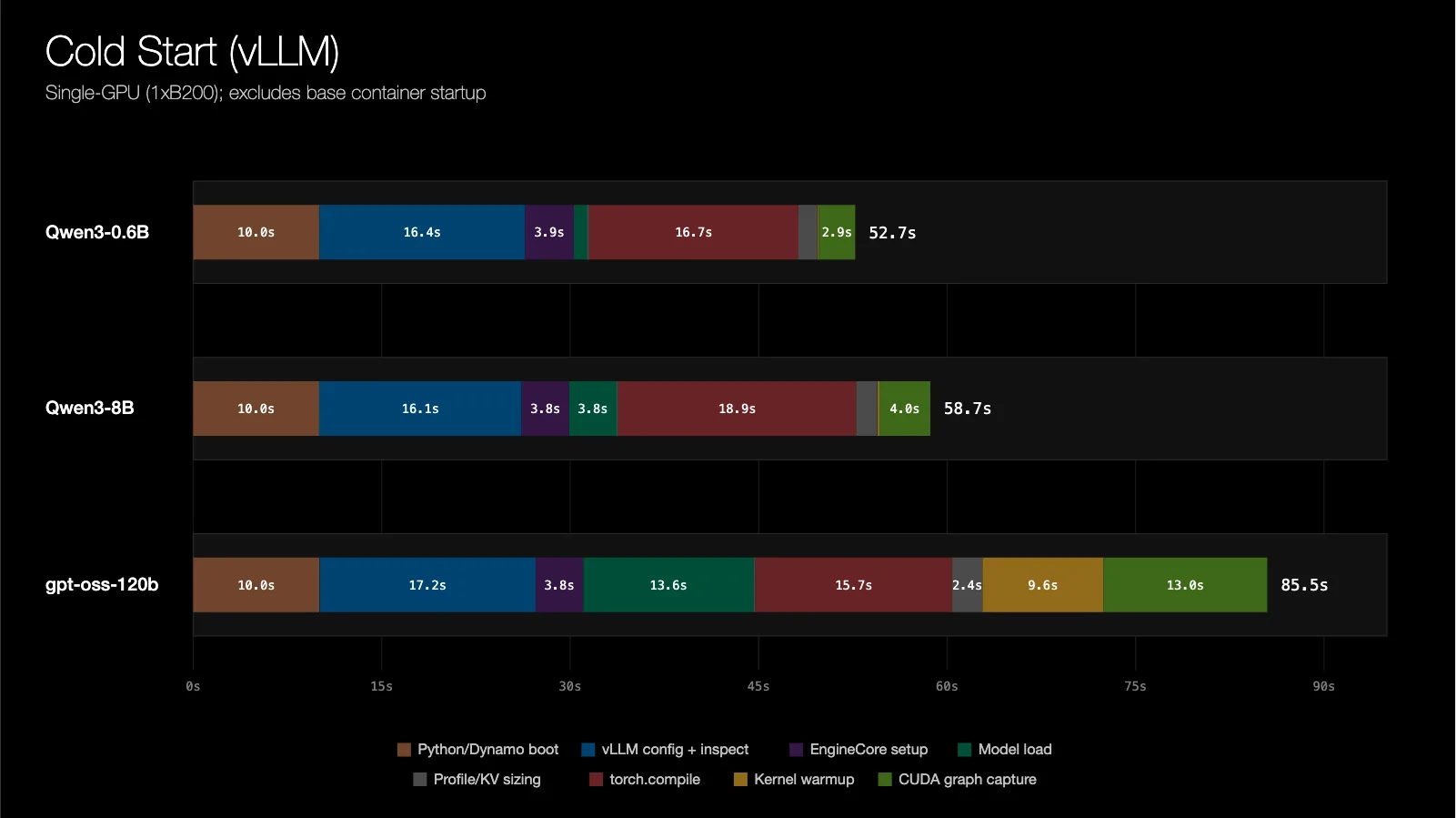
Компанія NVIDIA представляє технологію Dynamo Snapshot для виконання завдань штучного інтелекту на платформі Kubernetes, що дозволяє зменшити затримку при першому запуску та покращити масштабованість під час пікових навантажень. Технології CRIU та cuda-checkpoint працюють разом для збереження стану GPU та CPU, забезпечуючи безперебійне відновлення та мінімальний час простою.

Симпозіум SERC у Массачусетському технологічному інституті (MIT) був присвячений впливу штучного інтелекту на суспільство; у його рамках відбулися доповіді щодо прогнозування забруднення повітря та етичного впровадження штучного інтелекту. Під час панельних дискусій було розглянуто проблеми узгодження штучного інтелекту з людськими цінностями та управління системами штучного інтелекту.

Цього місяця GeForce NOW пропонує 18 нових ігор, серед яких довгоочікувана NTE: Neverness to Everness. Відкривайте для себе сюрреалістичні світи та класичні ремейки миттєво завдяки хмарному стримінгу — завантаження не потрібне.

Массачусетський технологічний інститут (MIT), Державний університет Джорджії та партнери запускають програму PATH, щоб забезпечити навчання у сфері штучного інтелекту для коледжів, орієнтоване на потреби промисловості, з акцентом на практичному навчанні та співпраці. Програма спрямована на формування практичних навичок та мислення у сфері штучного інтелекту у фахівців, готових до викликів майб...
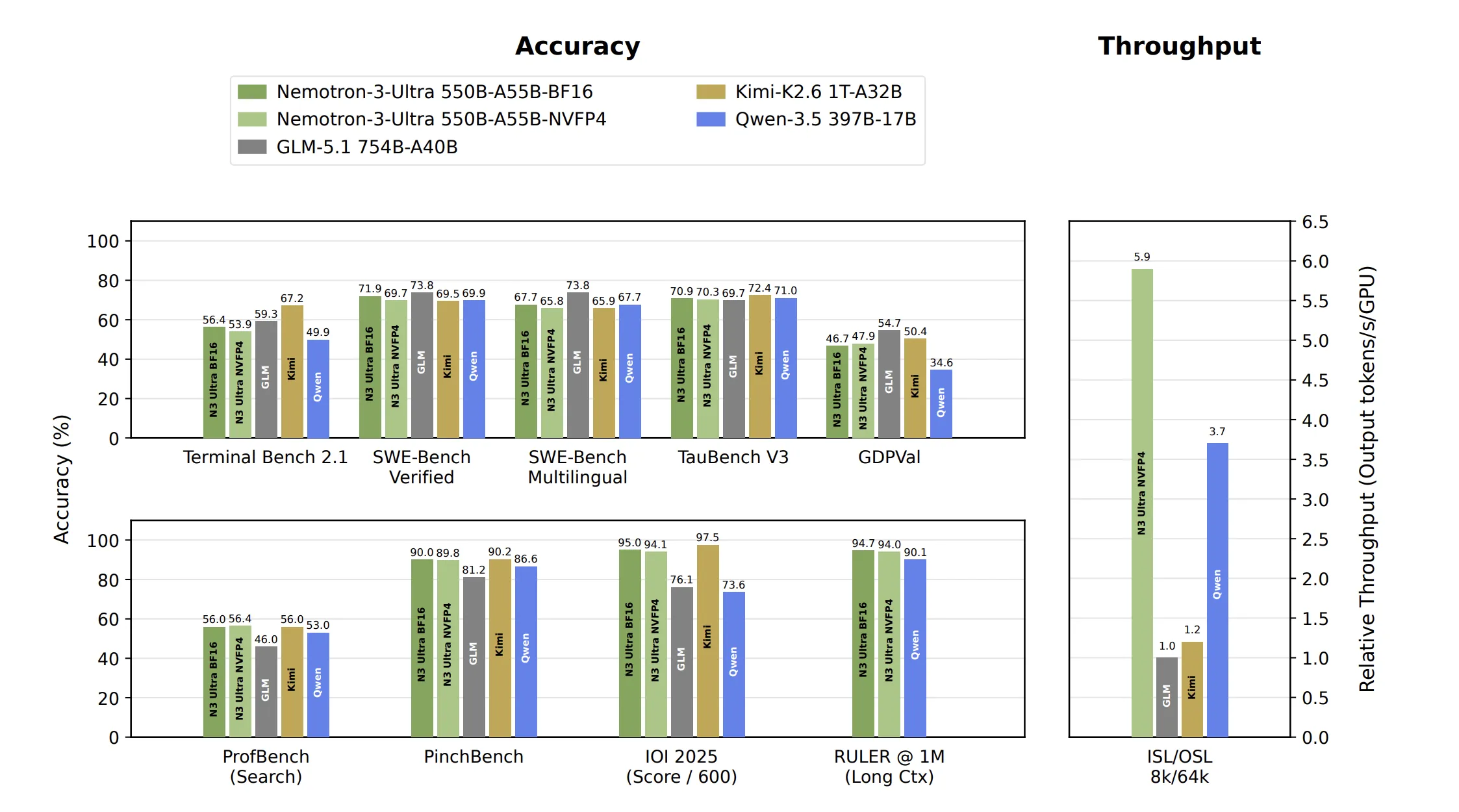
Компанія NVIDIA представляє Nemotron 3 Ultra — модель із 550 мільярдами параметрів та гібридною архітектурою Mamba-Attention, яка забезпечує в 6 разів вищу пропускну здатність при інференції. Модель використовує алгоритм Multi-Token Prediction для прискорення генерації та забезпечує стабільне й точне навчання завдяки типу даних NVFP4.
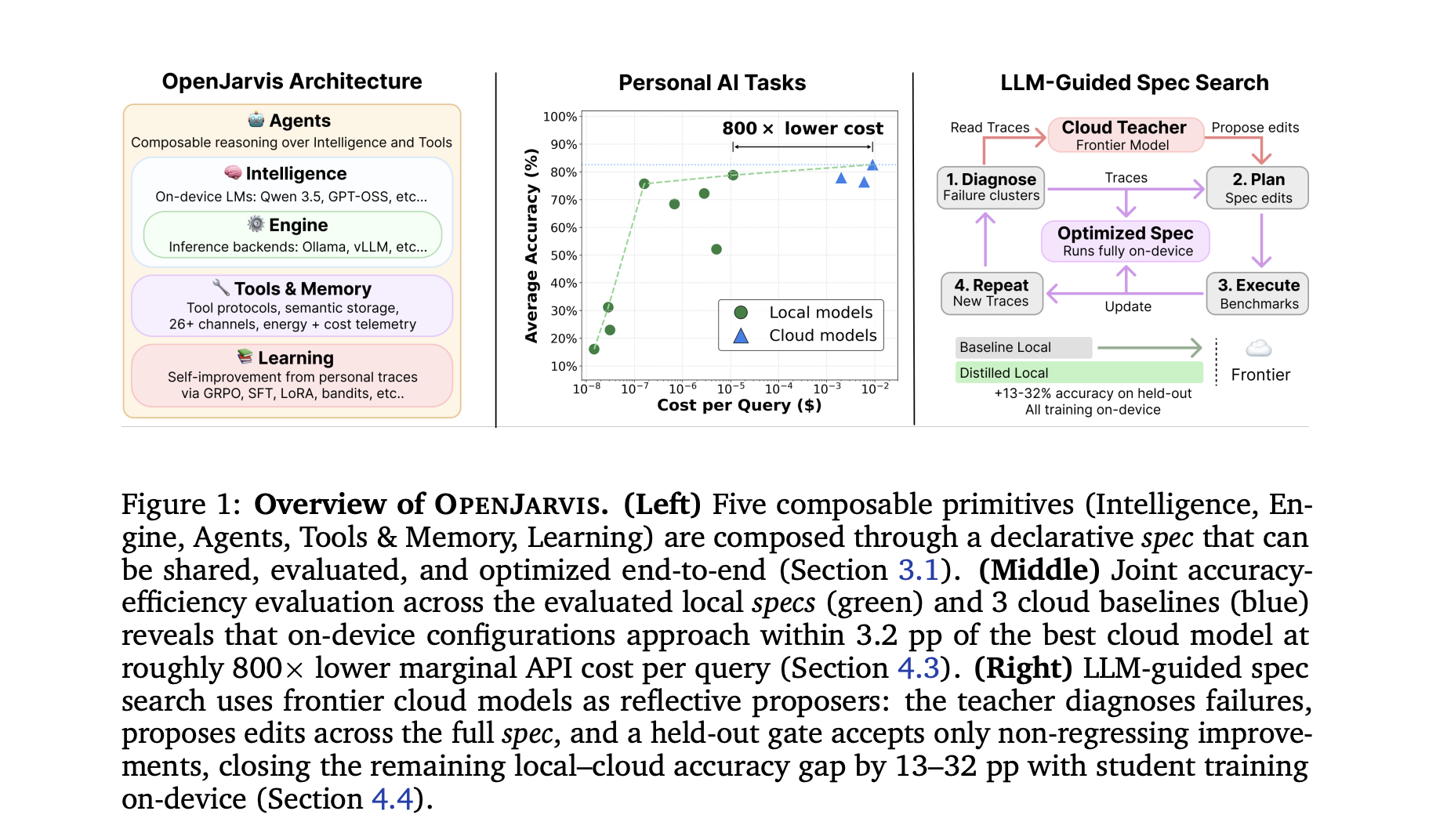
Дослідники зі Стенфордського університету та компанії Lambda Labs розробили OpenJarvis – платформу для роботи на локальних пристроях, яка за ефективністю та швидкістю обробки конкурує з хмарними моделями. OpenJarvis забезпечує легке поєднання моделей, агентів і пам'яті, а також має унікальну систему пошуку оптимальних параметрів, керовану великою мовною моделлю (LLM).
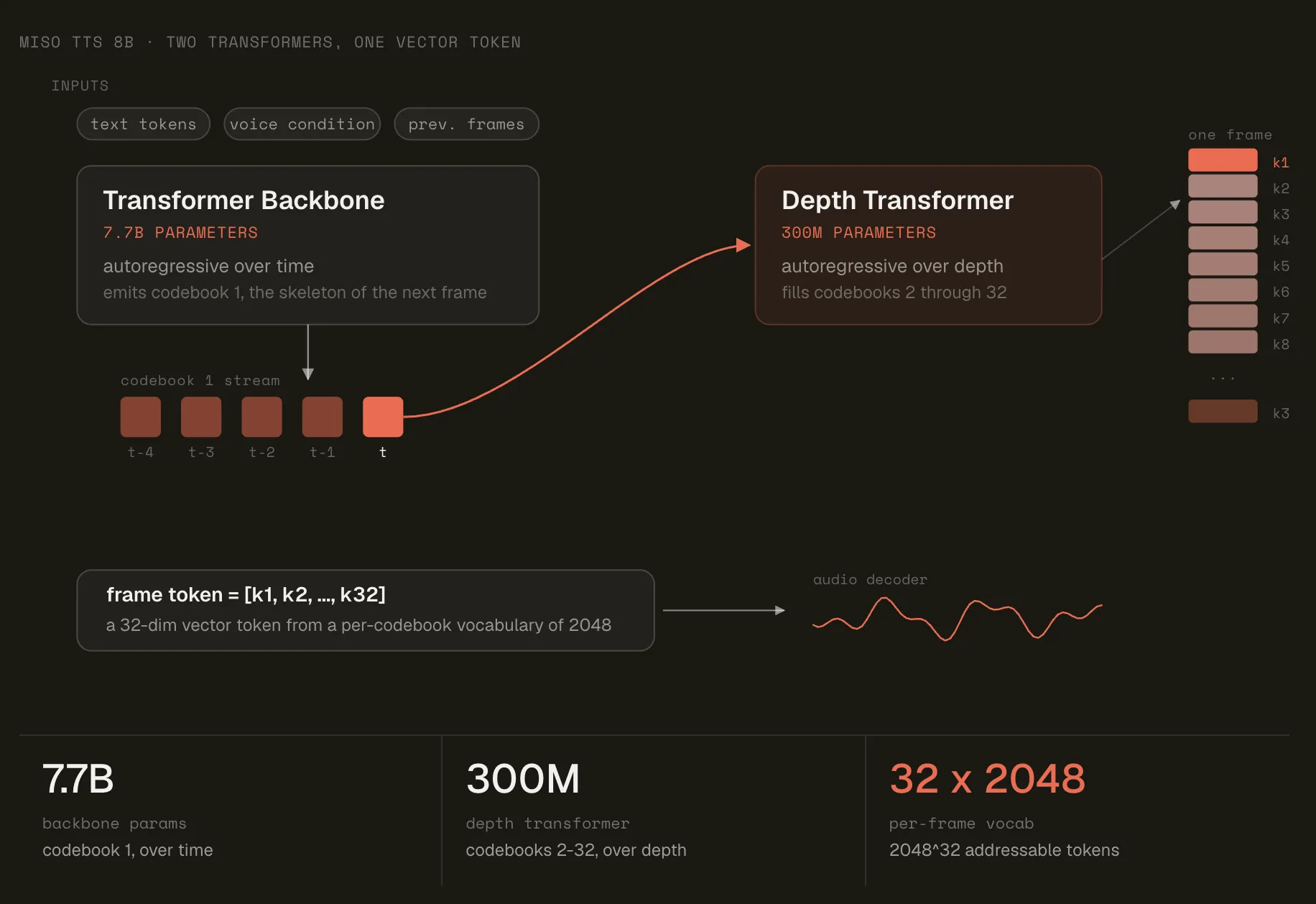
Компанія Miso Labs представляє MisoTTS — модель перетворення тексту в мову з 8 мільярдами параметрів, яка використовує алгоритм RVQ для розширення звукового діапазону та адаптації до інтонації мовця. Вирішуючи проблеми, пов’язані з розміром словника та обумовленням, MisoTTS забезпечує підтримку 2048³² токенів без додавання додаткових параметрів, перевершуючи конкурентів за показниками затримки.
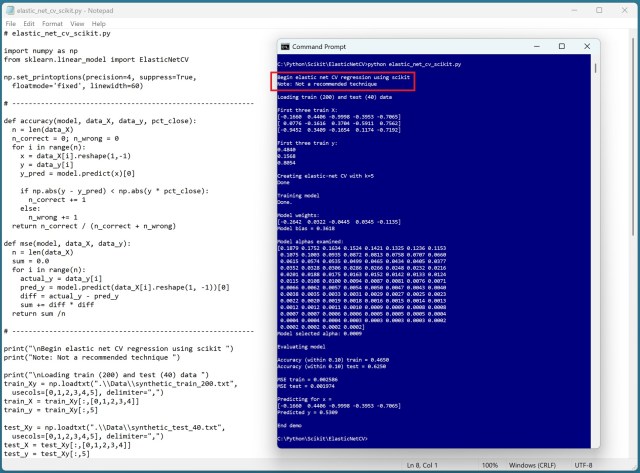
Досвідчений фахівець вважає перехресну валідацію в машинному навчанні неефективною через численні недоліки як у методі k-кратного поділу, так і в методі «залишити один випадок поза вибіркою». Відсутність узагальнюваності та ненадійність налаштування гіперпараметрів роблять перехресну валідацію справжньою головоломкою

Національний науковий фонд (NSF) продовжив фінансування проекту IAIFI Массачусетського технологічного інституту (MIT), зосередивши увагу на тому, як штучний інтелект сприяє розвитку фізики, а фізика — вдосконаленню штучного інтелекту. Спільні дослідження у сферах фізики та штучного інтелекту призводять до революційних відкриттів та інноваційних наукових підходів.
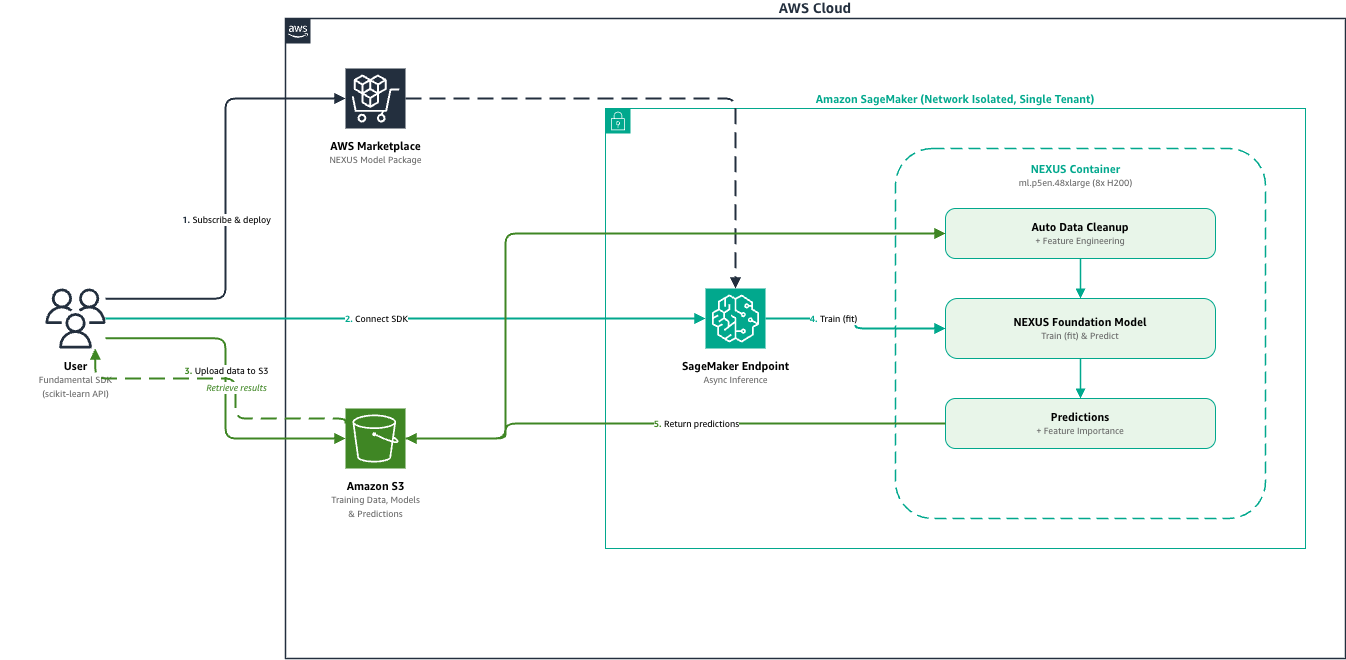
Amazon SageMaker AI тепер підтримує модель NEXUS від Fundamental, що дозволяє отримувати точні прогнози щодо табличних даних за лічені дні. NEXUS забезпечує детерміновані результати, вбудоване розуміння табличних даних та несеквенційне міркування для аналізу структурованих даних.
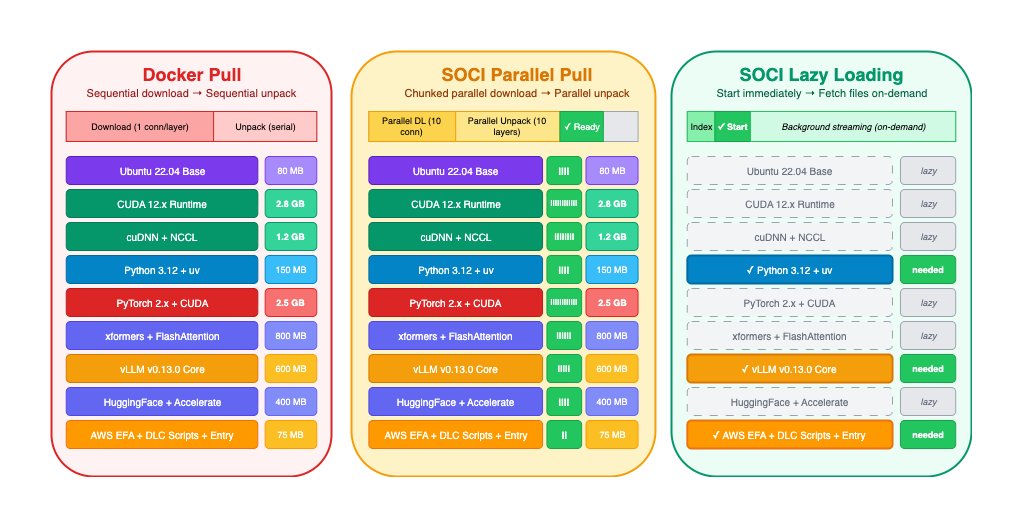
AMI для глибокого навчання та контейнери AWS Deep Learning тепер підтримують інструмент створення знімків та індекс SOCI для ефективного управління образами контейнерів. Функція відкладеного завантаження SOCI зменшує використання пропускної здатності мережі та скорочує час запуску контейнерів, що є корисним для організацій, які керують великими образами контейнерів у хмарних середовищах.
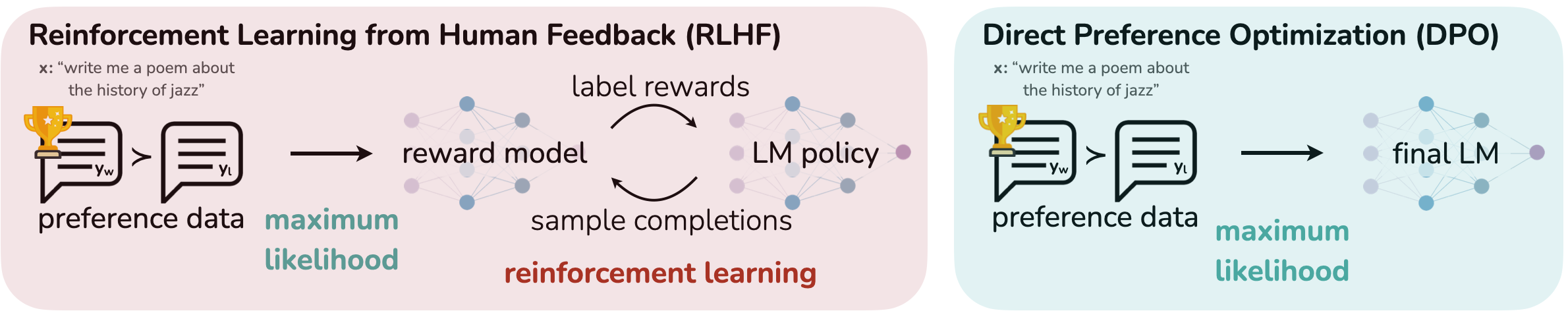
Штучний інтелект повинен підбирати відповідні інструменти для виконання завдань, щоб уникнути помилок і затримок. Дізнайтеся, як SFT і DPO підвищують точність виклику інструментів у мовних моделях для надійної автоматизації.

У 2026 році штучний інтелект чудово справляється з такими завданнями, як обслуговування клієнтів, але зазнає труднощів із складними запитами. Дослідники з Массачусетського технологічного інституту та Гарвардського університету вдосконалили здатність штучного інтелекту ставити запитання за допомогою гри «Морський бій», що дозволило досягти значного підвищення продуктивності та ефективності.
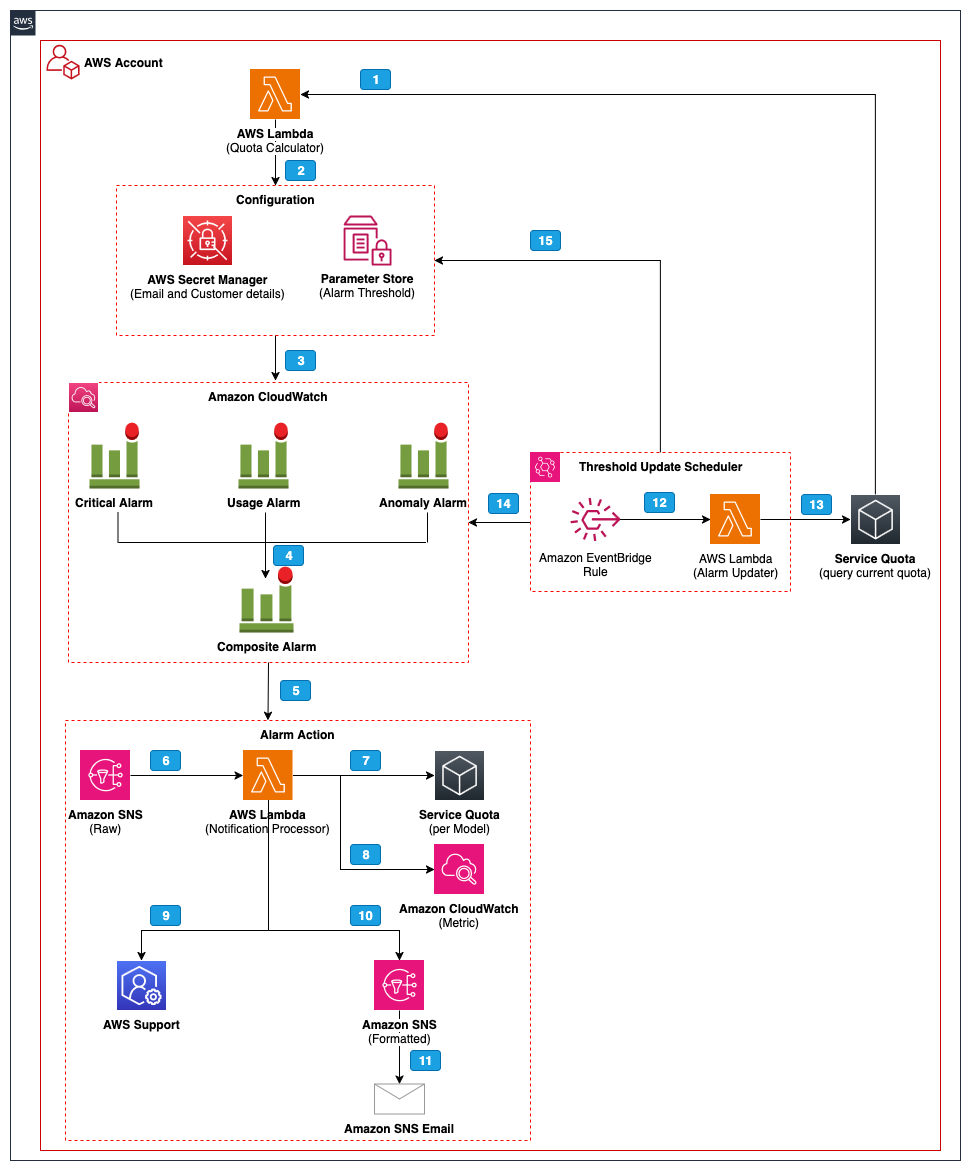
Amazon Bedrock надає доступ до генеративної штучної інтелектуальної технології понад 100 000 організацій по всьому світу, пропонуючи широкі можливості для сміливих інновацій. Представляємо Amazon Bedrock Ops Alert — рішення для проактивного моніторингу, призначене для сталого операційного управління робочими навантаженнями штучного інтелекту, яке дає командам можливість досягати реальних бізне...