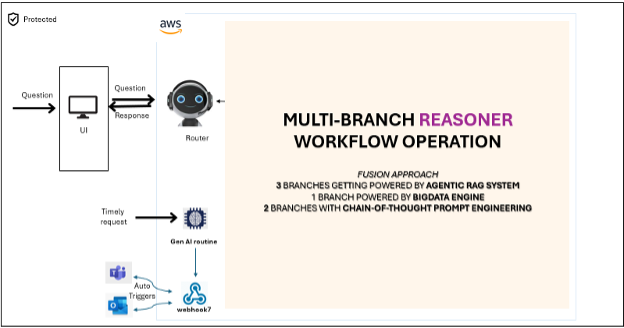
Apollo Tyres співпрацює з Amazon Web Services для цифрової трансформації, використовуючи генеративний штучний інтелект для оптимізації виробничих процесів. Рішення Manufacturing Reasoner автоматизує завдання, підключається до Інтернету речей і дозволяє приймати рішення на основі даних для підвищення операційної ефективності.

Консорціум MIT AgeLab's AVT Consortium відзначає десятиріччя галузевої співпраці, зосереджуючись на реакції водіїв на передові транспортні технології. Лідери галузі закликають до стратегічного, заснованого на даних підходу до автомобільної безпеки, ставлячи перед галуззю завдання визначити пріоритети інновацій та узгодження регулювання.
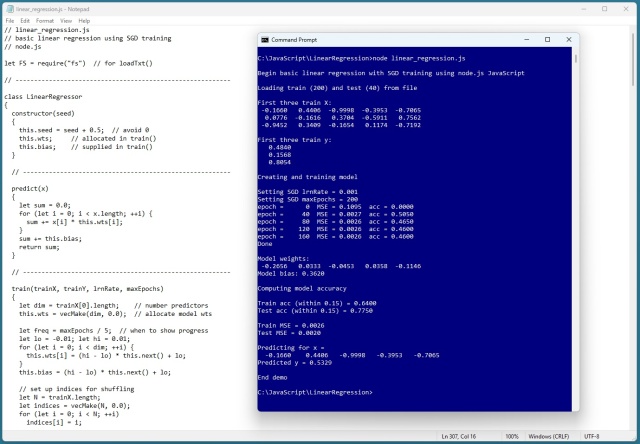
Демонстрація лінійної регресії на JavaScript використовує SGD для навчання. Прогнозує дохід від віку, зросту, освіти з точністю 64%.

Урядовий інструмент штучного інтелекту Humphrey використовує моделі з Op Усі чиновники в Англії та Уельсі пройдуть навчання з інструментарію штучного інтелекту в рамках програми підвищення ефективності державної служби.

Генеральний директор BT Елісон Кіркбі передбачає подальше скорочення робочих місць за допомогою штучного інтелекту з метою оптимізації компанії. До кінця десятиліття BT планує звільнити до 55 000 працівників, щоб стати більш економним бізнесом.

Розслідування Guardian виявило 7 000 випадків списування за допомогою штучного інтелекту серед студентів британських університетів, що перевищує традиційний плагіат. Експерти попереджають, що це лише початок, і кількість таких випадків зростає.

Генеративний штучний інтелект швидко впроваджується в різних галузях, від охорони здоров'я до освіти, але виникає занепокоєння через тенденцію великих мовних моделей генерувати неточну інформацію. Критики ставлять під сумнів справжню цінність цієї технології для економіки Великої Британії через постійну ваду LLM, яка полягає в тому, що вони все вигадують.

Чат-бот ChatGPT AI протестований для консультацій з особистих фінансів людьми-експертами. Чи може АІ ефективно управляти нашими грошима?

Міністр технологій Великобританії Пітер Кайл закликав британських працівників впроваджувати штучний інтелект зараз, інакше вони ризикують відстати, адже для подолання розриву між поколіннями у використанні технологій потрібно лише 2,5 години тренінгу.
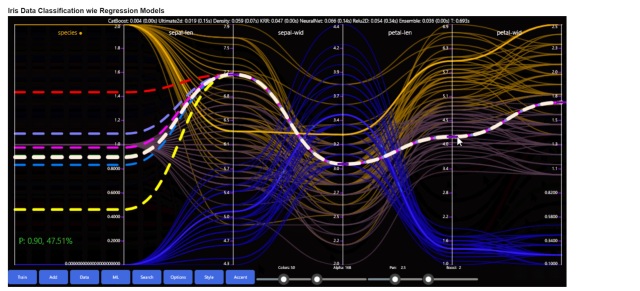
Торстен Клеппе (https://github.com/grensen) створює приголомшливі інтерактивні візуалізації даних, які захоплюють глядачів. Його останні дослідження демонструють красу та інтерактивність візуалізацій машинного навчання.
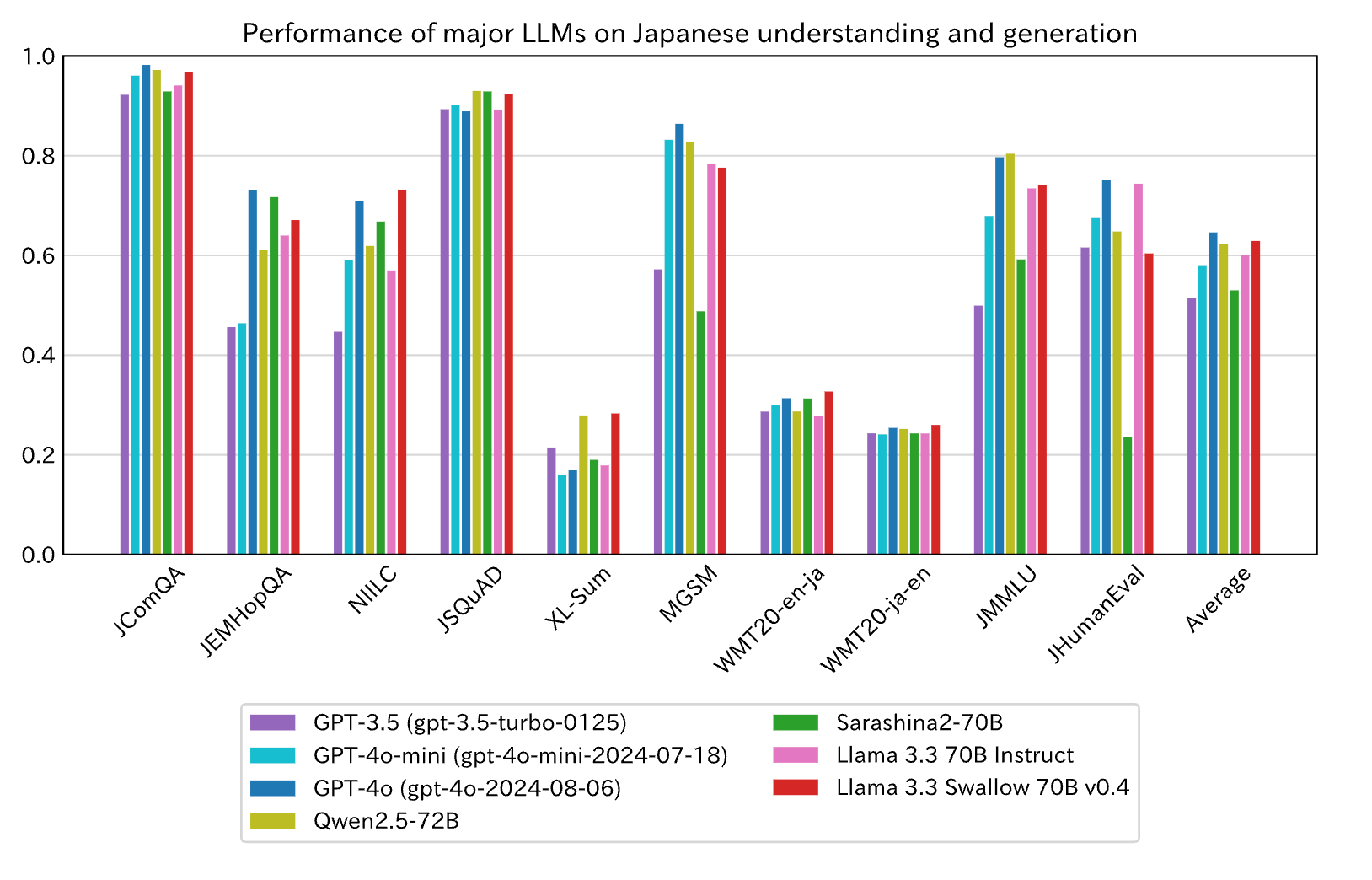
Казукі Фудзіі очолив розробку Llama 3.3 Swallow, 70-мільярдної LLM з чудовими можливостями японської мови. Модель перевершує GPT-4o-mini, демонструючи оптимізовану навчальну інфраструктуру та методологію.
Стаття демонструє лінійну регресію опорних векторів за допомогою C# з навчанням рою частинок для оцінки точності прогнозування моделі. Демонстрація розкриває проблеми прогнозування нелінійних даних, підкреслюючи важливість спеціалізованих алгоритмів оптимізації, таких як рій частинок.
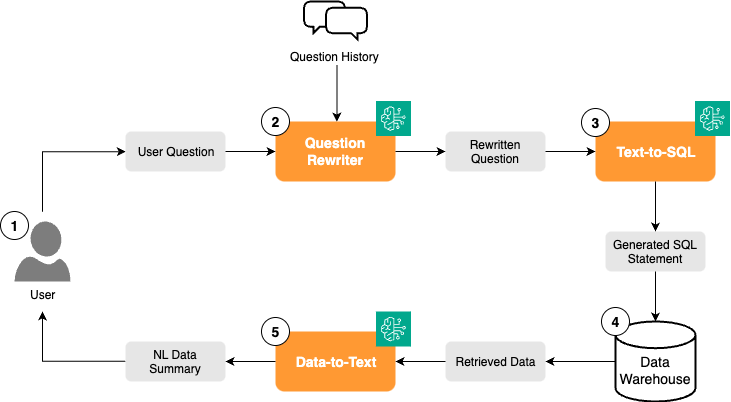
VideoAmp співпрацював з AWS GenAIIC для розробки прототипу чат-бота NL Analytics, який покращує медіа-аналітику за допомогою штучного інтелекту. Шлях VideoAmp до штучного інтелекту привів до точного таргетингу, кращих моделей атрибуції та збільшення рентабельності інвестицій, позиціонуючи їх як лідерів у сфері реклами на основі даних.

Генеративний штучний інтелект змінює цифр Велика модель SD3.5 з квантуванням до FP8, що зменшує обсяг VRAM на 40% для швидшої та ефективнішої генерації зображень.
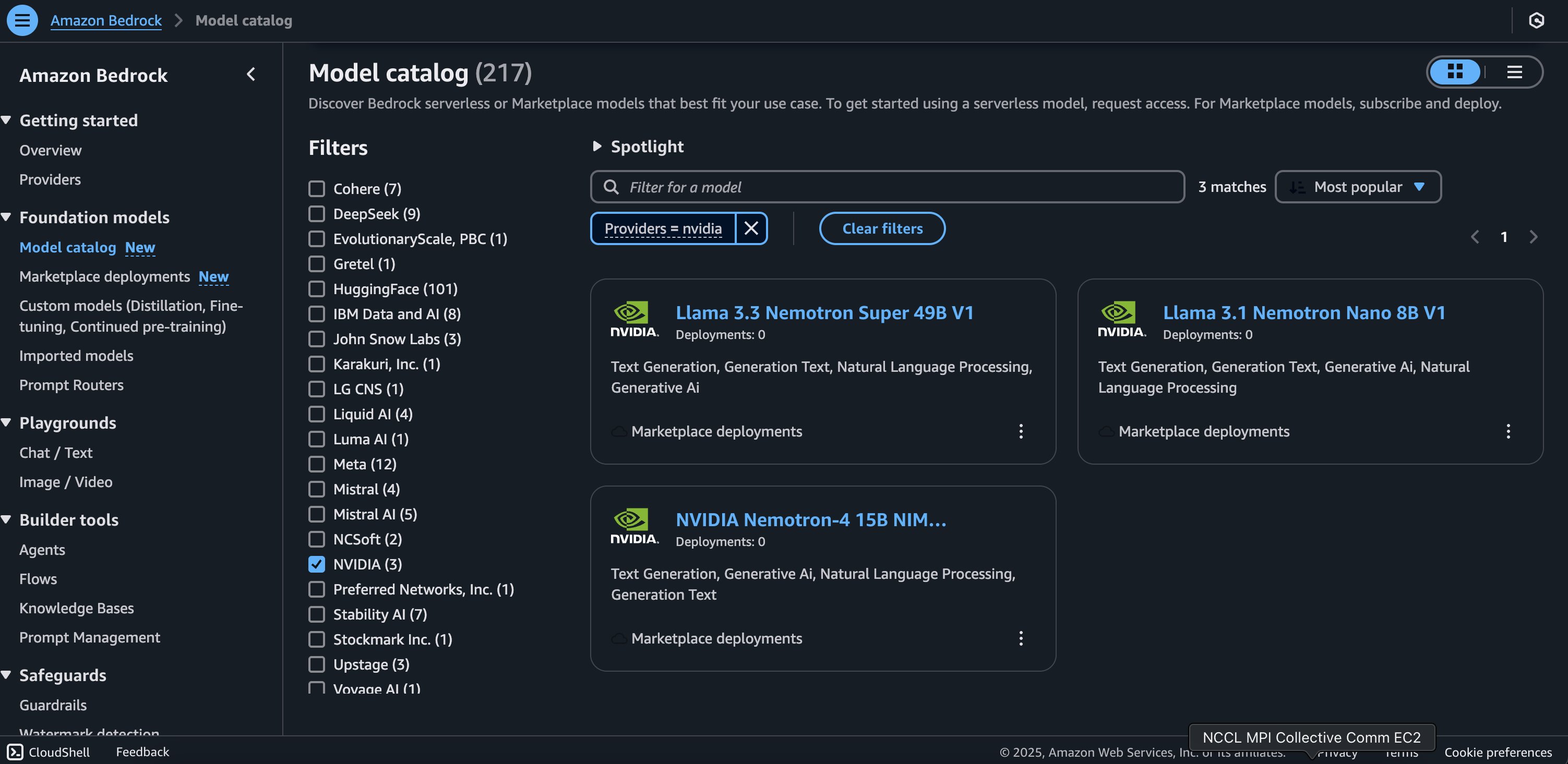
NVIDIA випускає Llama 3.3 Nemotron Super 49B V1 та Llama 3.1 Nemotron Nano 8B V1 на Amazon Bedrock Marketplace та SageMaker JumpStart для легкого розгортання генеративних моделей ШІ в масштабі. Мікросервіси NVIDIA NIM на AWS дозволяють безперешкодно розгортати різні моделі генеративного ШІ, включаючи моделі спільноти з відкритим вихідним кодом і користувацькі моделі, за допомогою стандартних A...