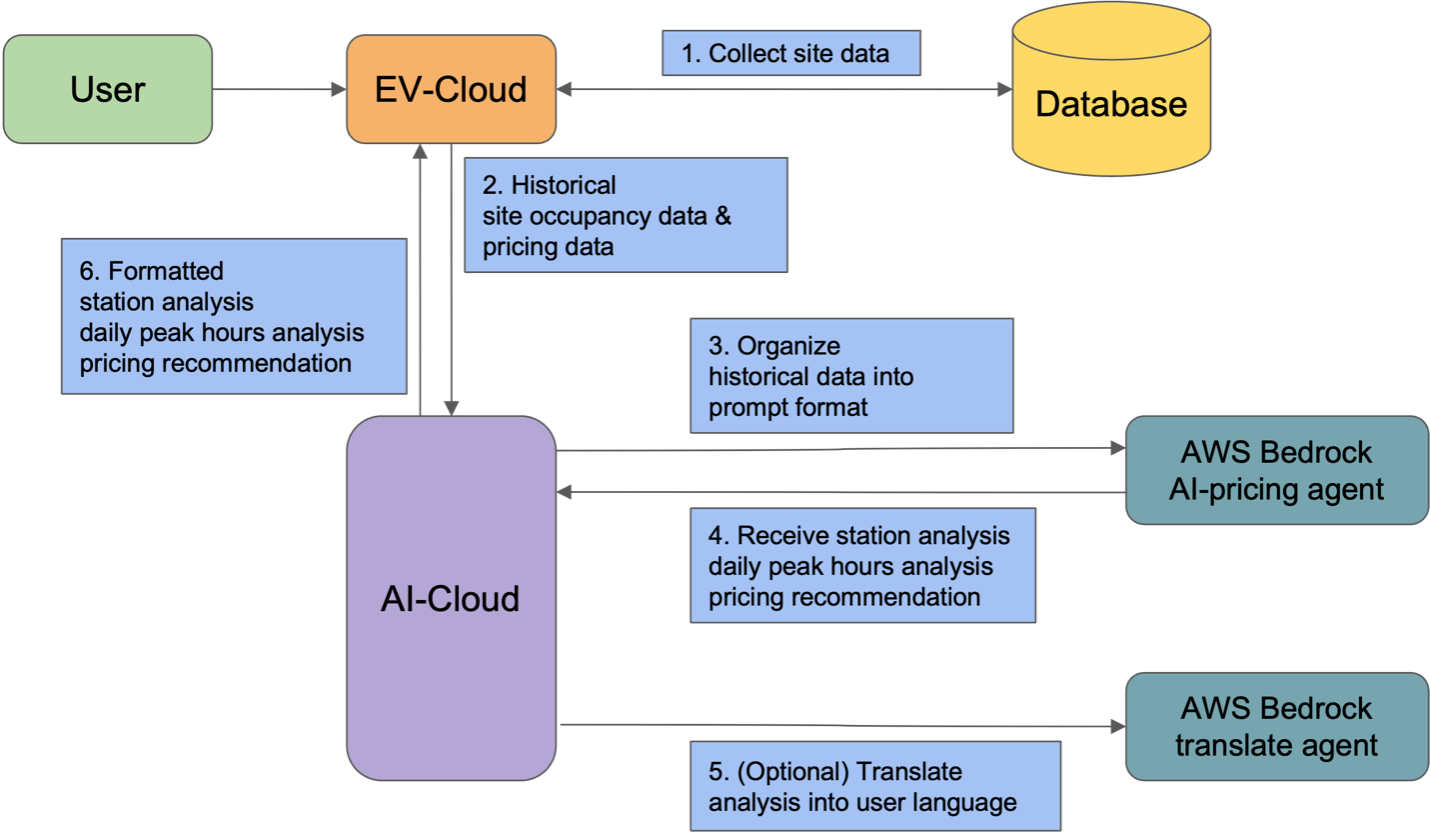
Noodoe використовує штучний інтелект і Amazon Bedrock для оптимізації операцій із заряджання електромобілів, пропонуючи інтелектуальну автоматизацію, доступ до даних у режимі реального часу та індивідуальні цінові рекомендації. Цей інноваційний підхід підвищує ефективність, стійкість та задоволеність клієнтів у конкурентній індустрії зарядних станцій для електромобілів.

Йошуа Бенгіо запускає компанію LawZero для розробки чесного ШІ, щоб запобігти обману людей у гонці озброєнь зі штучним інтелектом вартістю $1 трлн. Бенгіо, хрещений батько ШІ, прагне створити захист від зловмисних ШІ-агентів.
Themis AI вдосконалює моделі штучного інтелекту, щоб виявляти та виправляти невизначеності та упередження, забезпечуючи надійність у додатках з високими ставками. Цей спін-аут Массачусетського технологічного інституту пропонує рішення для вдосконалення моделей штучного інтелекту та запобігання руйнівним наслідкам шляхом прогнозування збоїв ще до того, як вони трапляться.

Письменник Юен Моррісон досліджує генеративний ШІ за допомогою ChatGPT, створюючи вигадані назви книг. Незважаючи на досягнення ШІ, Моррісон та інші протистоять використанню штучного інтелекту, побоюючись його потенційної шкоди, і віддають перевагу людській творчості.

Meta укладає першу угоду з Constellation Energy, яка забезпечить роботу американського реактора протягом 20 років, після того, як Google і Microsoft уклали угоди про енергопостачання дата-центрів за допомогою ядерної енергії. Великі технологічні компанії звертаються до ядерної енергетики, оскільки попит на електроенергію в США зростає через розвиток штучного інтелекту та потреби центрів обробк...

Міністр внутрішніх справ стикається з тиском на поліцію через пропозиції щодо дострокового звільнення. Джерела в оборонному секторі прогнозують, що на саміті НАТО Велика Британія візьме на себе зобов'язання щодо витрат на оборону в розмірі 3,5% ВВП до 2035 року. Лорди кидають виклик уряду щодо законопроекту про дані, звинувачуючи його в нехтуванні креативними індустріями всупереч ШІ.

Деміс Хассабіс (Demis Hassabis) з Google DeepMind прагне використовувати ШІ для оптимізації управління електронною поштою, вирішуючи проблему перевантаження поштових скриньок за допомогою поштових технологій нового покоління. Мета - автоматизувати рутинні завдання, такі як сортування та відповіді на електронні листи, що в кінцевому підсумку зменшить стрес від керування поштовою скринькою.

Лука Гуаданьїно веде переговори про зйомки фільму «Штучний», присвяченого драмі OpenAI про звільнення та повторний прийом на роботу Сема Альтмана у 2023 році. Комедійна драма пропонує зазирнути за лаштунки OpenAI у бурхливий період.

Генеративний ШІ трансформує робочі місця початкового рівня; інфлюенсери монетизують згенерований ШІ текст. Новий тест зі штучним інтелектом прогнозує переваги ліків від раку простати.

Глобальні інвестиції в ШІ стрімко зростають, і Nvidia лідирує в цьому напрямку. Питання етики та інклюзивності відходять на другий план у шаленстві штучного інтелекту.
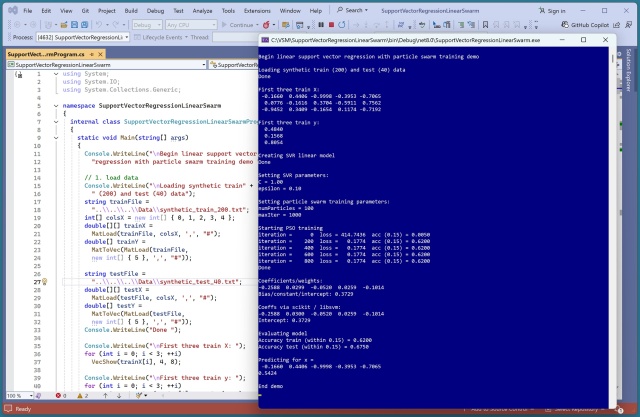
Навчання лінійної регресії опорних векторів (SVR) викликає труднощі через те, що функція втрат не піддається обчисленню. Використання оптимізації рою частинок (PSO) виявилося більш ефективним, ніж еволюційні алгоритми для навчання лінійних SVR-моделей.

Meta, власник Facebook та Instagram, використовуватиме інструменти штучного інтелекту для рекламних кампаній, загрожуючи традиційним рекламним агентствам. Цей крок націлений на маркетингові бюджети брендів в обхід агентств.

Машинне навчання ШІ аналізує електричні сигнали, що генеруються почерком, щоб виявити тремор Паркінсона за допомогою 3D-друкованої ручки з магнітними чорнилами. Рання діагностика допомагає отримати доступ до підтримки для 10 мільйонів людей у всьому світі, які живуть з хворобою Паркінсона.

Лео Ентоні Селі з Массачусетського технологічного інституту розглядає упередженість даних для навчання ШІ, висвітлюючи недоліки та пропонуючи рішення для більш точних моделей. Він наголошує на важливості навчання студентів ретельній оцінці даних, щоб запобігти упередженості в застосуванні ШІ.

Дослідницька група з Olivetti Group та MIT CSHub використовує штучний інтелект для пошуку стійких альтернатив цементу в бетоні, відкриваючи для себе кераміку та побічні продукти гірничодобувної промисловості як життєздатні варіанти. Їхній фреймворк машинного навчання сортує понад 1 мільйон зразків гірських порід, щоб виявити 19 типів матеріалів, які можуть зменшити витрати та викиди у виробниц...