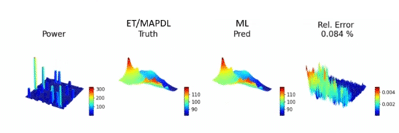
Ansys використовує технології NVIDIA для вирішення складних завдань у проектуванні 3D-ІС на конференції з автоматизації проектування. Використовуючи NVIDIA Omniverse і Modulus, інженери Ansys можуть оптимізувати продуктивність і надійність чіпів за допомогою сурогатних моделей на основі ШІ для швидшого моделювання.
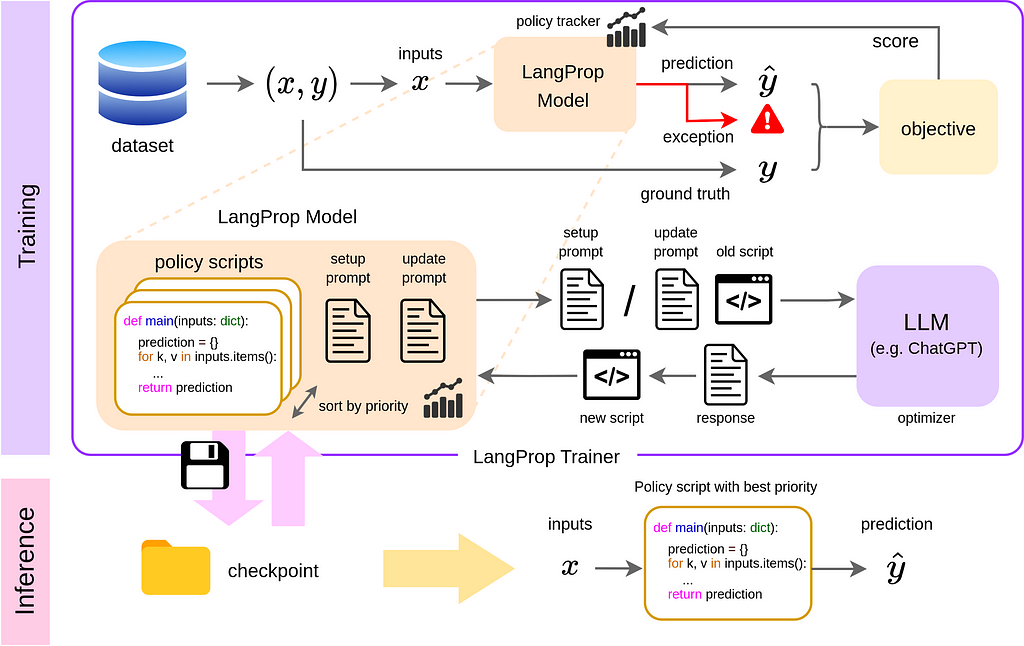
ChatGPT забезпечує дослідження автономного водіння у Wayve, використовуючи фреймворк LangProp для оптимізації коду без тонкого налаштування нейронних мереж. LangProp, представлений на семінарі ICLR, демонструє потенціал LLM для покращення водіння за допомогою генерації та вдосконалення коду.

Великі мовні моделі (ВММ) уможливлюють спілкування, подібне до людського, але можуть також поширювати дезінформацію та шкідливий контент. Захисні екрани мають вирішальне значення для зменшення ризиків у застосуванні LLM, забезпечуючи безпечні та бажані результати.

Чат-бот GeoGPT, що фінансується Китаєм, викликає занепокоєння серед геологів через потенційну цензуру та упередженість, розроблений за підтримки IUGS. Орієнтований на дослідників глобального півдня, він використовує величезні обсяги даних для поглиблення розуміння наук про Землю.
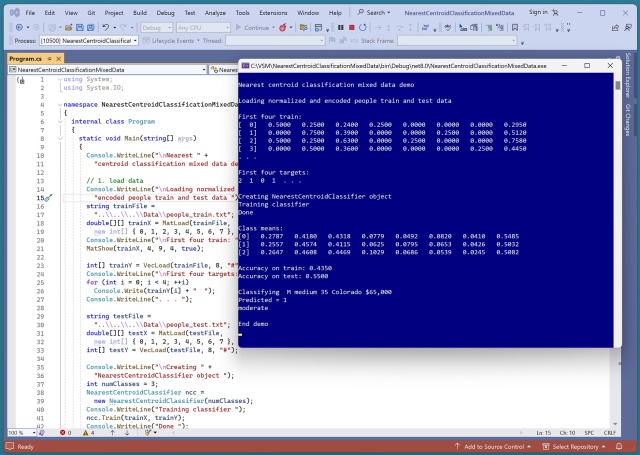
Класифікація найближчого центроїда виявилася неефективною для складних прогнозів, показавши лише 55% точності на тестових даних. Він найкраще підходить для порівняння з більш потужними методами класифікації, такими як нейронні мережі.

Навчіться легко інтегрувати pyFlink, Kafka та PostgreSQL за допомогою Docker. Долайте виклики та створюйте конвеєр обробки даних в реальному часі для даних з датчиків IoT.
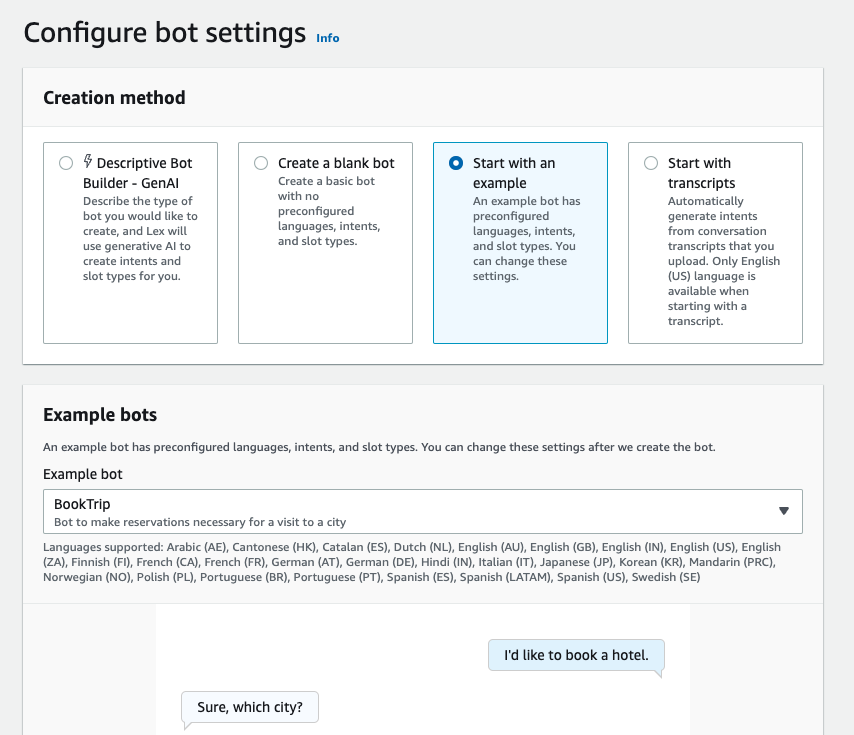
Amazon Lex QnAIntent на базі Amazon Bedrock дає змогу вести розмови в режимі реального часу з розумінням природної мови. Можливості точного пошуку за допомогою Amazon Kendra та OpenSearch Service задовольняють регуляторні потреби корпоративних клієнтів.

Звукозаписні компанії подали позови проти AI-генераторів пісень Suno та Udio за порушення авторських прав, вимагаючи по $150 000 за твір. Позови, подані великими лейблами, такими як Sony, Universal і Warner Records, щодо використання музики артистів.

Ефективність продажів часто вимірюється неправильно, що призводить до неточних оцінок. Якість лідів є вирішальним фактором для точної оцінки ефективності роботи торгових агентів.

Мінсоцполітики та команда GovTech створили Fill. sg за 2 тижні на хакатоні LAUNCH! Hackathon, щоб спростити написання звітів за допомогою штучного інтелекту. Використовуючи довгоконтекстні моделі та зручний інтерфейс, Fill.sg має на меті спростити створення звітів для державних службовців.
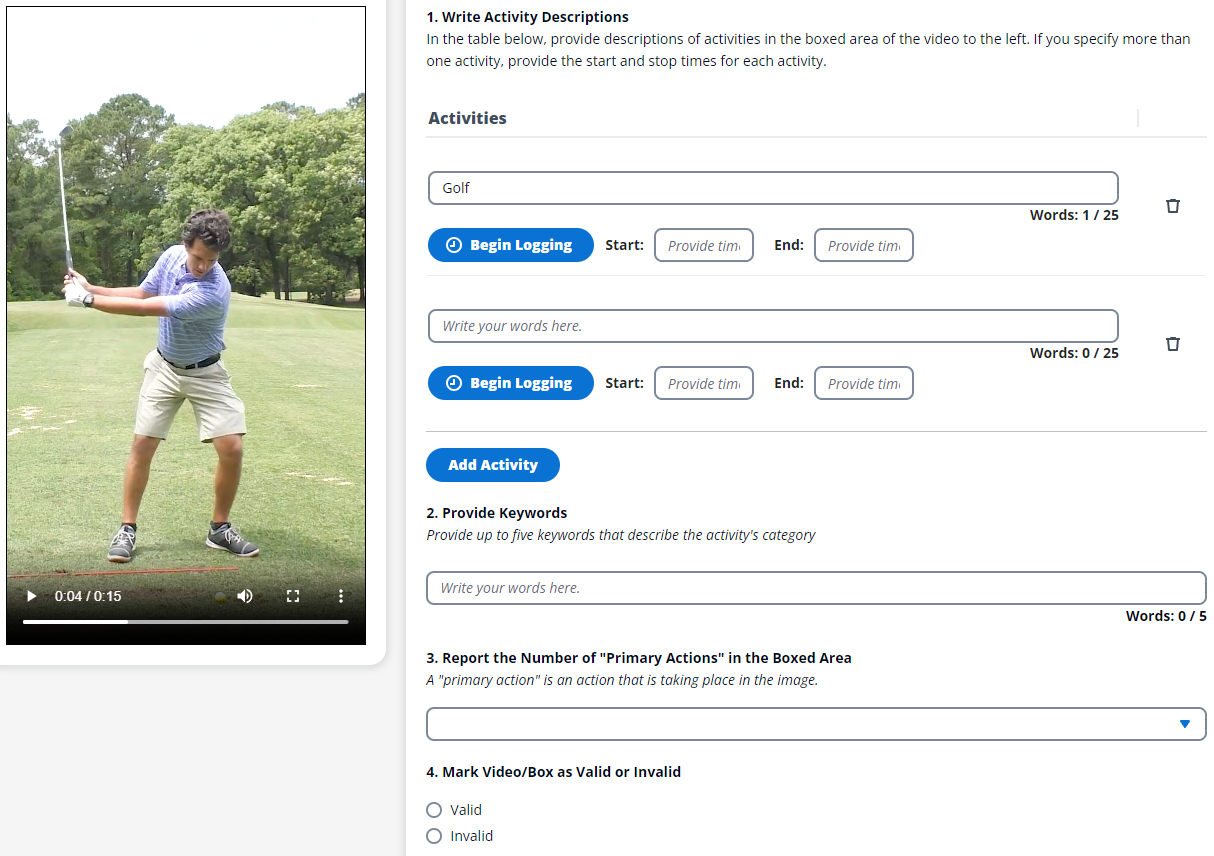
Krikey AI використовує Amazon SageMaker Ground Truth для ефективного маркування величезних обсягів даних для своєї інноваційної платформи 3D-анімації, демократизуючи створення ШІ-анімації. Це партнерство дозволяє Krikey AI швидко отримувати високоякісні мітки, пристосовані до їхніх потреб, що прискорює розробку їхньої моделі перетворення тексту в анімацію.

Нещодавні мультимодальні мережі-трансформери, такі як CLIP і LLaVA, порівнюють з мозком з точки зору уваги. Трансформатори зору виконують попередню візуальну обробку подібно до мозку, але мають проблеми зі складними завданнями. Двонаправлена активність мозку забезпечує свідому увагу зверху вниз і автоматичний зворотній зв'язок, покращуючи сприйняття і пізнання.

Стартап Hume, що базується на Манхеттені, розробив перший у світі голосовий ШІ з емоційним інтелектом, що викликає занепокоєння щодо потенційних зловживань та упередженості у сфері ШІ, який зчитує почуття. Випробування меж цієї технології передбачає вираження таких емоцій, як любов, за допомогою тексту, що підкреслює потенційну небезпеку емоційного ШІ.

Навчіться створювати власні набори даних та завантажувачі даних у PyTorch для різних моделей. Зрозумієте різницю між наборами даних і завантажувачами даних, а також як застосовувати трансформації для попередньої обробки зображень.
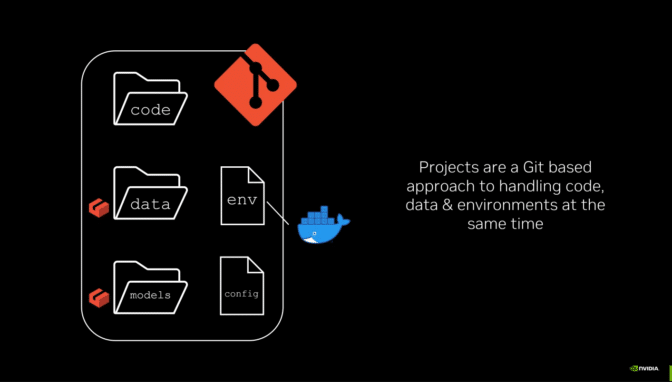
NVIDIA AI Workbench спрощує розробку генеративного ШІ з додатками RAG, дозволяючи створювати індивідуальні моделі та безперешкодно співпрацювати. Цей безкоштовний інструмент спрощує налаштування та забезпечує легку спільну роботу на різних платформах для дослідників даних і розробників.