Штучний інтелект агентного типу перетворює процес навчання після початкового етапу на безперервний цикл, адаптуючись до змінних умов і максимізуючи інтелектуальні можливості при заданому бюджеті. Відкриті бібліотеки NVIDIA NeMo спрощують процес навчання після початкового етапу, перетворюючи спеціалізований дослідницький код на повторювану інфраструктуру для масштабованого розвитку інтелекту.
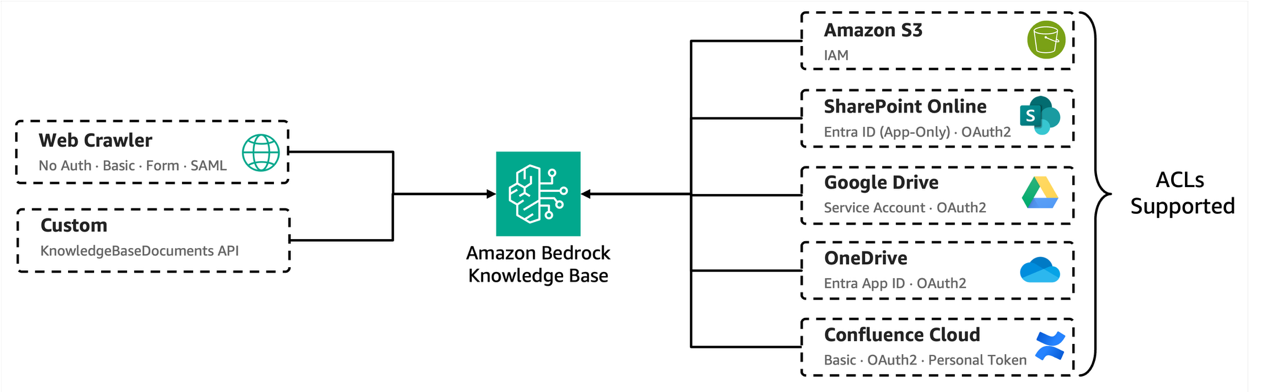
Amazon Bedrock пропонує керовану базу знань, що спрощує налаштування та покращує пошук завдяки вбудованим коннекторам і підтримці контролю доступу (ACL). Компанія Syngenta Group отримує вигоду від цього повністю керованого рішення для пошуку інформації, яке забезпечує масштабованість і безпечний контроль доступу до документів.

Дослідники з Массачусетського технологічного інституту розробили систему, яка ефективно перетворює двовимірні ескізи в програми для автоматизованого проектування (CAD), покращуючи генерацію CAD за допомогою штучного інтелекту. Ця технологія може спростити процес створення прототипів, зменшити витрати та допомогти інженерам приймати кращі рішення щодо проєктування.
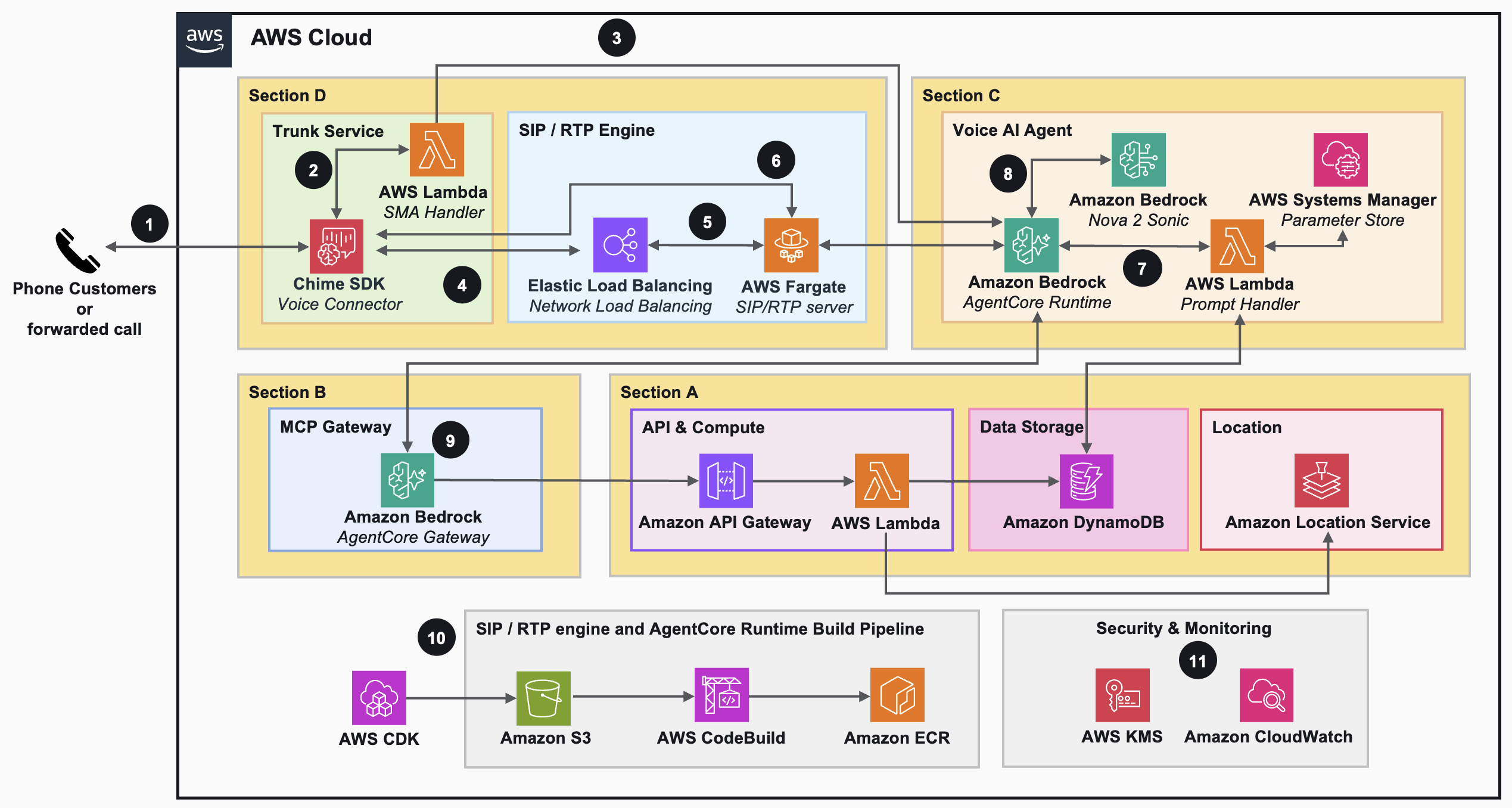
Ресторани втрачають близько 150 телефонних дзвінків на місяць, з яких 60% стосуються замовлень або бронювання столиків. Дізнайтеся, як Amazon Bedrock AgentCore та Nova 2 Sonic створюють систему голосового замовлення для зручної взаємодії по телефону.
Модель Grok 4.3 від xAI, яка тепер доступна на платформі Amazon Bedrock, пропонує можливості конфігурування логічних процесів для створення агентів з високою ефективністю використання інструментів та чітким виконанням інструкцій. Вона перевершує галузеві стандарти, що робить її ідеальною для корпоративних задач, таких як аналіз договорів та відповіді на запитання щодо фінансових документів.
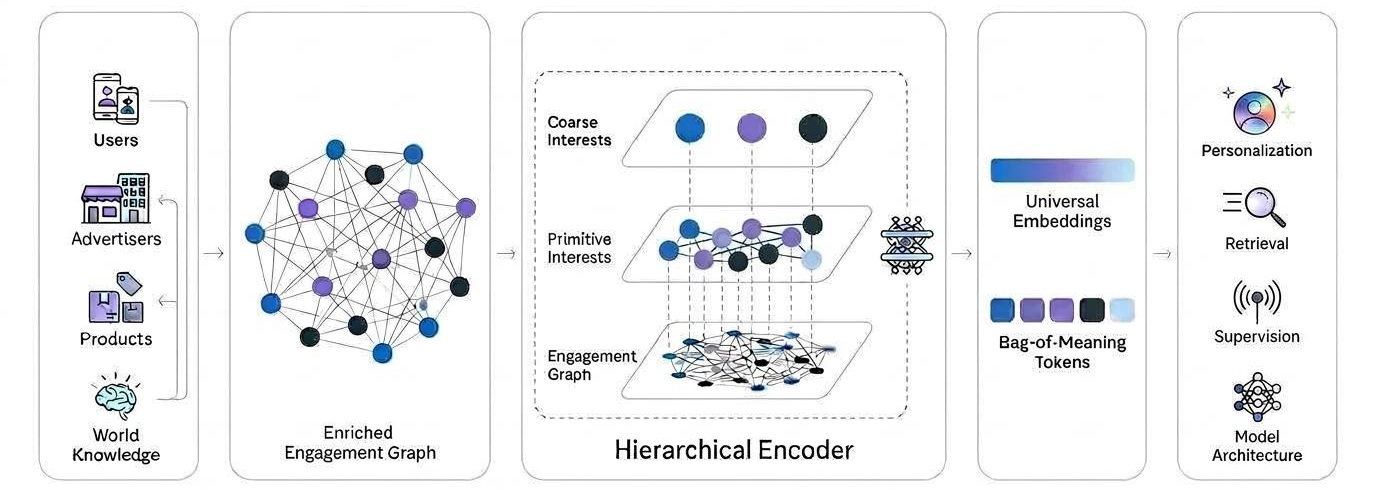
Система "Ієрархічне представлення інтересів" від Meta Ads пов'язує інтереси користувачів з пропозиціями рекламодавців, покращуючи оптимізацію на різних етапах воронки продажів за допомогою багатошарових моделей. Ця система поєднує знання про реальний світ із сигналами взаємодії для створення нових архітектур персоналізації та ранжування на всіх платформах Meta.

Лідери японської системи охорони здоров'я використовують технології NVIDIA для революції в галузі розробки ліків, а такі компанії, як Astellas і Daiichi Sankyo, є лідерами цього процесу. Інноваційні продукти, такі як ZAO та KOYA від SyntheticGestalt, трансформують медицину завдяки досягненням у сфері штучного інтелекту.
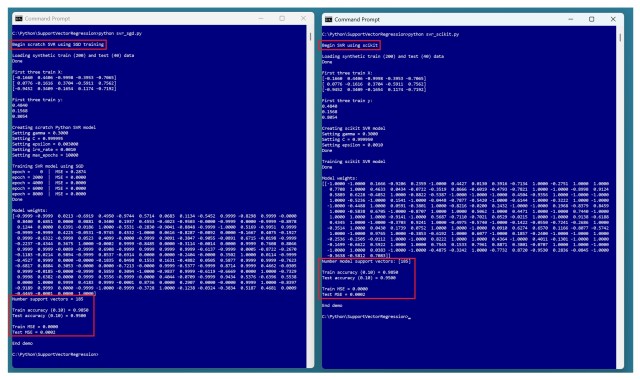
Демонстрація показує ефективний стохастичний метод градієнтного спуску (SSGD) для задач регресії опорних векторів (SVR). У більшості випадків, метод Kernel Ridge Regression перевершує SVR за результатами.

Дослідники з MIT представили інструмент під назвою "нейральна прозорість", який дозволяє зазирнути всередину роботи штучного інтелекту перед взаємодією з чат-ботом. Користувачі можуть візуалізувати характеристики ШІ, що сприяє проактивному проєктуванню для запобігання небажаній поведінці.
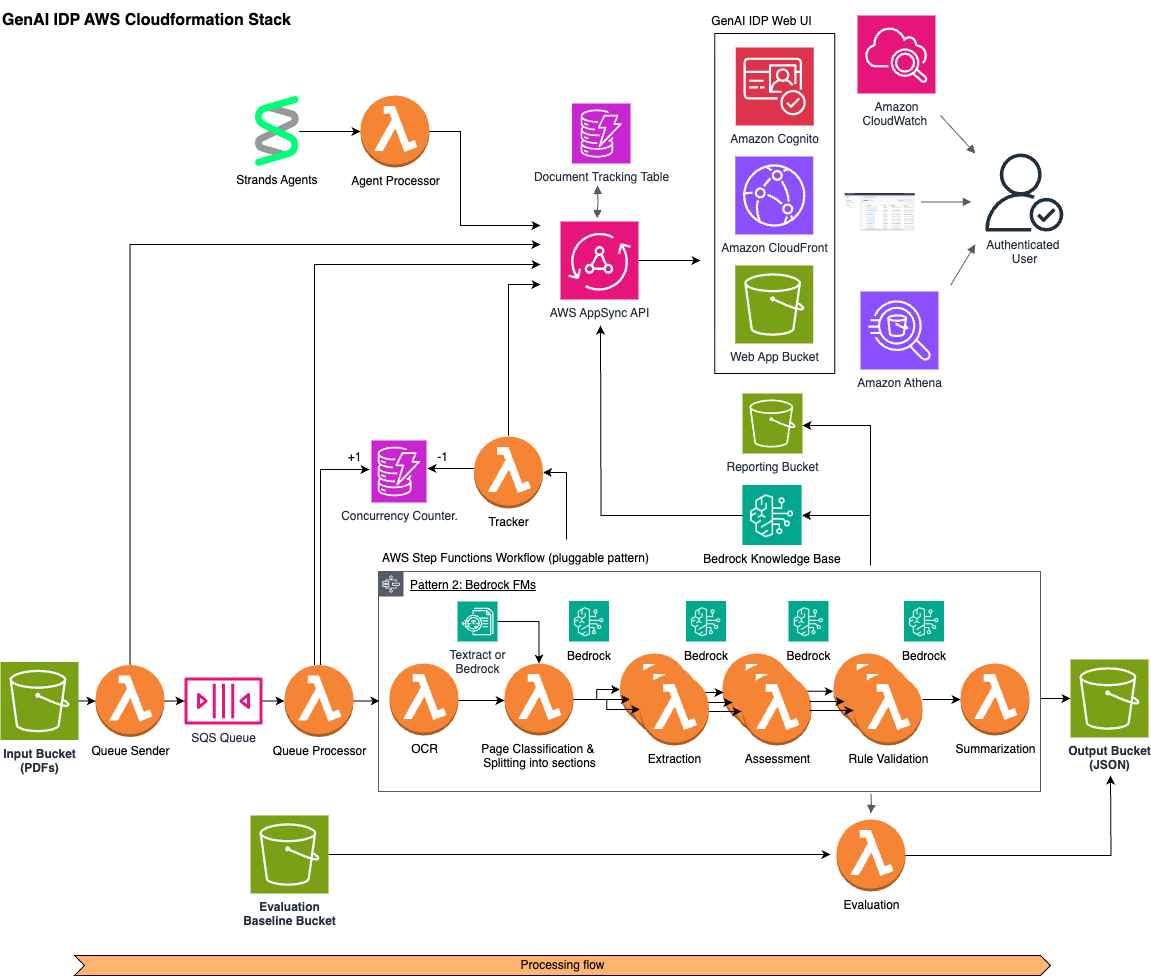
Компанія Built Technologies, постачальник програмного забезпечення для фінансування нерухомості, розробила систему обробки документів на основі штучного інтелекту та запустила її на платформі Amazon Bedrock, що призводить до значних змін у цій галузі. Ця система оптимізує складні процеси обробки документів, скорочуючи час обробки з днів до хвилин.
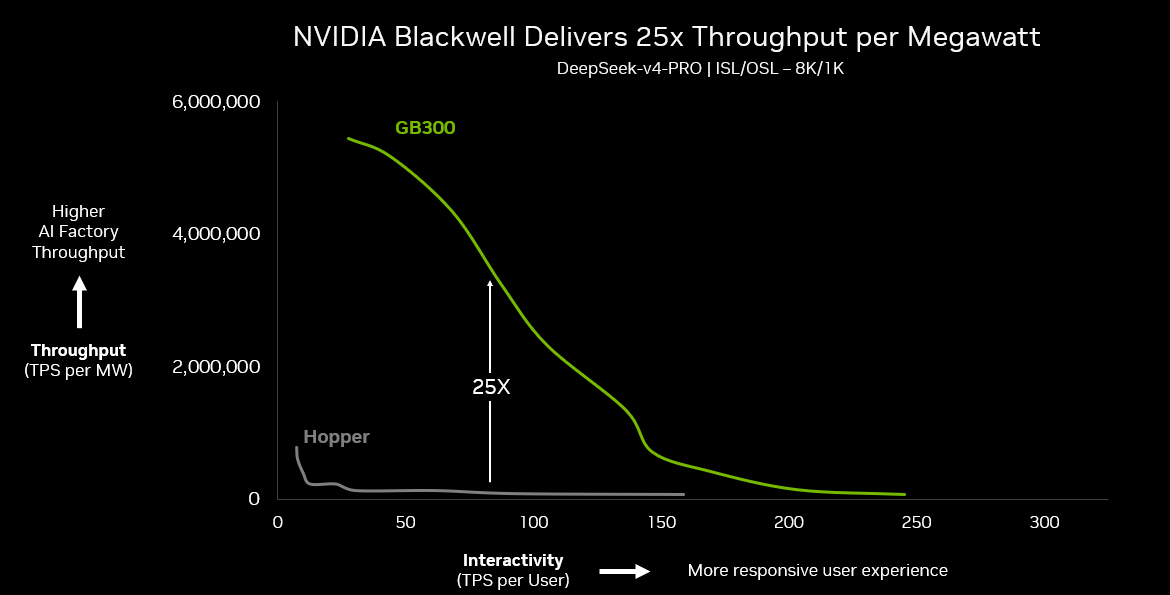
Виробники систем штучного інтелекту орієнтуються на продуктивність у ватах для забезпечення прибутковості. Платформа Blackwell від NVIDIA забезпечує вдвічі кращу ефективність порівняно з попередніми моделями, встановлюючи новий стандарт для передових рішень ШІ.

Devavrat Shah з Массачусетського технологічного інституту заснував компанію Ikigai Labs для розробки систем штучного інтелекту, які використовуються для прийняття рішень у реальному часі на основі табличних даних, що приносить користь великим підприємствам, зокрема виробникам товарів народного споживання. Система аналізує корпоративні дані для оптимізації прогнозування, планування та операцій, ...
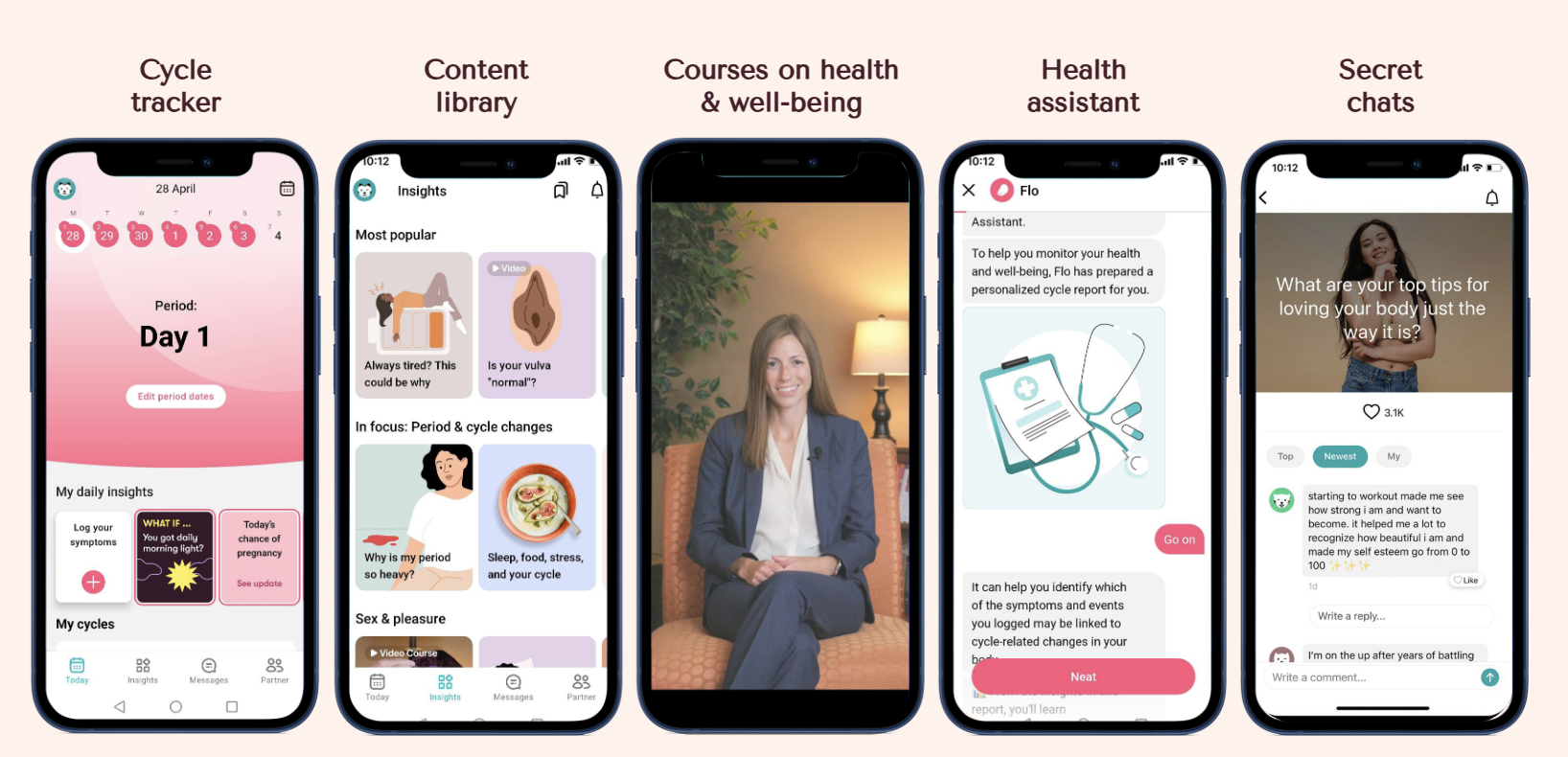
Команда інженерів компанії Flo Health використала центр інновацій AWS Generative AI для створення системи перегляду медичного контенту на основі штучного інтелекту, що дозволило скоротити час перевірки на 60% і збільшити обсяг опрацьованого контенту у три рази. Проблеми масштабування процесу перевірки медичної інформації були вирішені за допомогою спеціалізованих AI-модулів та технології Retrie...

Штучний інтелект змінює розробку апаратного забезпечення; проєкт JARVIS від MIT досліджує роль ШІ в прискоренні проєктування реактивних двигунів. Студенти використовують ШІ для створення двигунів, що демонструє важливість інженерної експертизи порівняно з використанням ШІ.
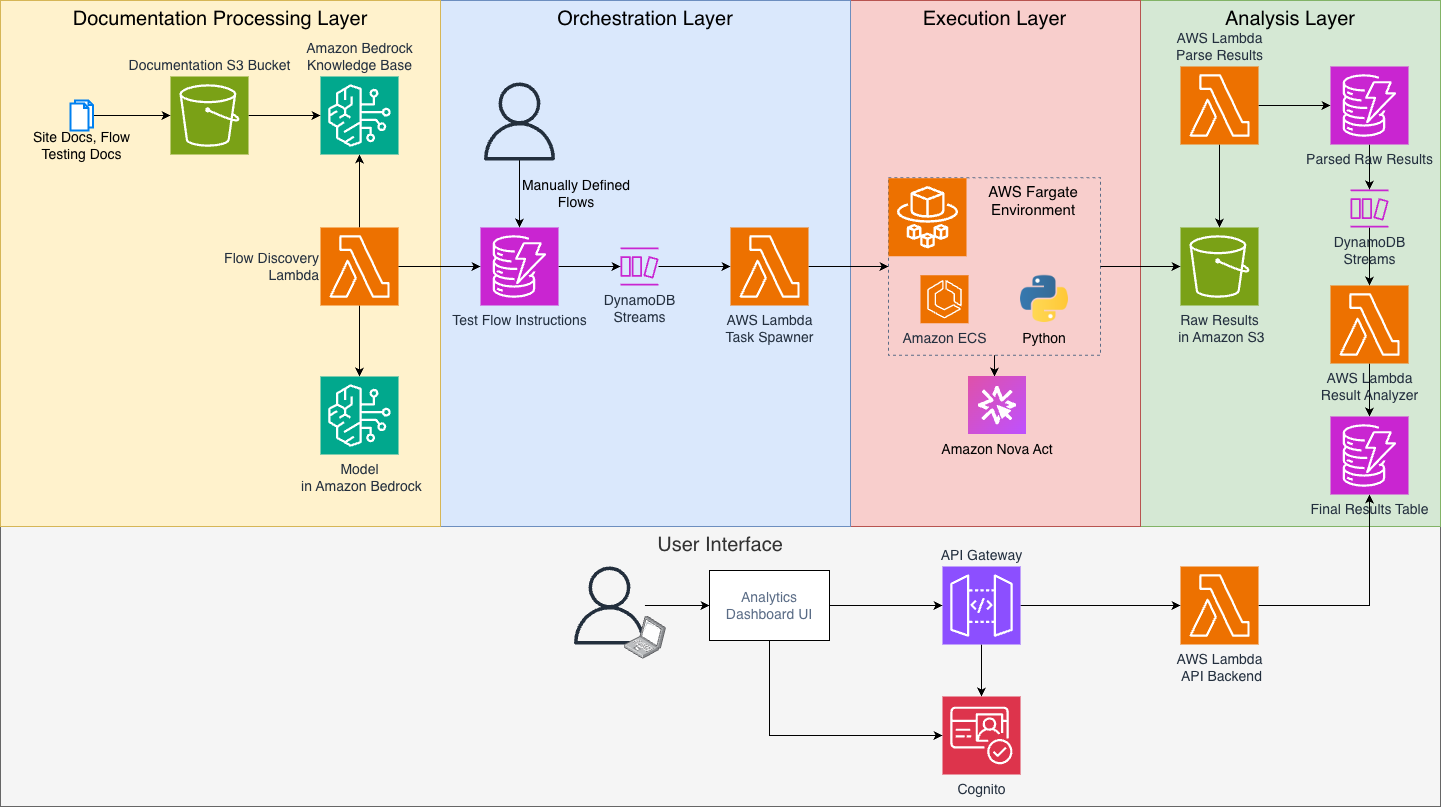
Тестування зручності використання (UX) стикається з труднощами у покращенні взаємодії користувачів із цифровими платформами. Amazon Nova Act пропонує потужне рішення, використовуючи генеративний штучний інтелект для автоматизації тестування UX завдяки можливостям інтелектуальної навігації, що надає цінні відомості для розробки веб-сайтів та забезпечення їх інтуїтивності.