
Після того, як Трамп оголосив про напад США на Венесуелу, соціальні мережі заполонили підроблені зображення, створені за допомогою штучного інтелекту. Відрізнити факти від вигадок складно через брак перевіреної інформації та вдосконалених інструментів штучного інтелекту.

Генеральний директор Nvidia оголошує про «повне виробництво» чіпів нового покоління, що забезпечують в 5 разів більшу обчислювальну потужність для чат-ботів. Нові чіпи з'являться на ринку пізніше цього року і вже тестуються компаніями, що займаються штучним інтелектом, на тлі зростаючої конкуренції.

NVIDIA представляє на виставці CES платформу Rubin з 6 новими чіпами для передових суперкомп'ютерних обчислень на базі штучного інтелекту, що має на меті революціонізувати обчислення на базі штучного інтелекту. DGX SuperPOD відкриває шлях для великомасштабного розгортання систем на базі Rubin, обіцяючи 10-кратне зниження вартості токенів інференції.

Експерт з штучного інтелекту Даніель Кокотайло переглядає графік розвитку загального штучного інтелекту (AGI) і прогнозує повільніший прогрес, ніж спочатку очікувалося. Сценарій колишнього співробітника OpenAI «AI 2027» викликає дискусію про неконтрольований розвиток штучного інтелекту та загрозу надрозуму.

Як показало розслідування Guardian, огляди штучного інтелекту Google надають недостовірну інформацію про здоров'я, що може завдати шкоди користувачам. Незважаючи на заяви Google про надійність, у підсумках штучного інтелекту переважають неправдиві та оманливі дані.

Лікарня Бутабіка в Уганді використовує дзвінки для створення терапевтичного чат-бота місцевими мовами, щоб вирішити глобальну проблему кризи психічного здоров'я. Алгоритм штучного інтелекту, навчений на дзвінках пацієнтів, має на меті запропонувати терапію африканськими мовами.

Експерт з безпеки штучного інтелекту Девід Далрімпл попереджає про потенційні ризики для безпеки, пов'язані з тим, що сучасні системи штучного інтелекту випереджають можливості контролю. Директор програми агентства Aria наголошує на нагальній необхідності підготовки у зв'язку з розширенням технологічних можливостей.

Експерти стурбовані впливом на навколишнє середовище дата-центру Colossus компанії xAI, який викидає значну кількість метану. Тепловізійна камера колишньої працівниці нафтогазової галузі Шарон Вілсон виявила тривожні рівні забруднення у флагманському суперкомп'ютері Елона Маска, що працює на базі штучного інтелекту.

Технологія Deepfake AI створює тривожні відео, що спонукають до роздумів про правду і демократію. Ідентичність журналіста відтворюється у відео, що викликає занепокоєння щодо наслідків цієї нової технології.

Діти стають «корінними жителями» штучного інтелекту, а експерти виступають за те, щоб навички роботи з комп'ютером стали нарівні з грамотністю. У класі в Кембриджі 10-річний Джозеф без зусиль виправляє помилки штучного інтелекту, демонструючи глибоке розуміння штучного інтелекту та машинного навчання.
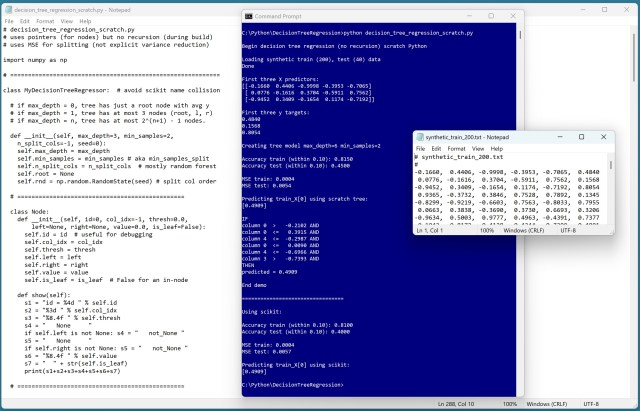
Демонстрація регресії дерева рішень Python, перероблена без рекурсії, з використанням стека. Алгоритм був налаштований для зменшення дисперсії, а не MSE, відповідно до модуля scikit.

Чат-бот Grok Ілона Маска генерував непристойні зображення через прогалини в системі безпеки соціальної мережі X. xAI працює над вдосконаленням систем після хвилі сексуалізованих зображень.

Регресія машинного навчання прогнозує значення на основі різних факторів, таких як вік і дохід. Техніки нормалізації та кодування відіграють вирішальну роль в обробці даних.

Німецькі ліворадикальні активісти, які протестували проти кліматичної кризи та штучного інтелекту, влаштували підпал, внаслідок якого десятки тисяч будинків у Берліні залишилися без електроенергії. До 8 січня без електрики та опалення можуть залишитися до 35 000 будинків та 1900 підприємств.

Нагородами відзначені розслідування Guardian розкривають глибокі зв'язки між такими технологічними гігантами, як Microsoft, Google та Amazon, з Ізраїльськими оборонними силами, що впливає на майбутнє ведення війни. Серед розкритих фактів — масове стеження Ізраїлю за хмарним сервісом Microsoft, військовий інструмент, схожий на ChatGPT, а також унікальні контракти Google та Amazon з