
What is machine learning?
Machine learning is a scientific discipline dedicated to the development of algorithms and statistical models. Unlike traditional programming, machine learning doesn’t require you to create the model yourself. The data engineer collects and prepares data for machine learning and experiments with different machine learning algorithms to build a better model. Once the model is formed, all that remains is to use it to solve the problem and get the result.
Another significant difference between machine learning and traditional programming is the number of input parameters processed. To accurately forecast the weather in a specific location, you will need to enter thousands of parameters that affect the result. Building an algorithm that can intelligently use all these parameters is a difficult task for humans.Machine learning has no such limitations: with sufficient processor power and memory, any number of input parameters can be used at the user's discretion.
In the medical field, machine learning plays an important role in diagnosis, treatment personalization, and predictive analytics. Algorithms analyze extensive datasets, identifying subtle patterns that may escape human observation. For example, the Breast cancer computer-aided detection by QuData ensures early detection of cancer pathology, facilitates the necessary medical intervention, and provides specialists with an independent expert opinion.
Speech recognition through machine learning has redefined human-computer interaction. Advanced algorithms process spoken speech, converting it into text or executable commands. Voice assistants, language translation services, and voice-activated devices all use machine learning to accurately understand and respond to human speech.
Machine learning is driving future business change, providing companies with powerful tools to optimize processes and make more informed decisions. The effectiveness of this technology is evident in its ability to analyze vast amounts of data, identify trends, and generate predictions, becoming an invaluable asset for strategic decision-making.
How does machine learning work?
Machine learning is a complex process that starts with data collection. At the initial stage of a project, researchers carefully create a dataset, deciding whether to create it themselves, use publicly available sources, or purchase ready-made data. This is an important step, as the quality and volume of data directly affect the subsequent performance of the machine learning model.
Data collection is followed by data preparation. This step involves data conversion into a usable format, such as CSV files, ensuring that it aligns with the established goals. This includes clearing duplicate data, correcting errors, adding missing information, and scaling the data to a standard format.
Data collection is followed by data preparation. This step involves data conversion into a usable format, such as CSV files, ensuring that it aligns with the established goals. This includes clearing duplicate data, correcting errors, adding missing information, and scaling the data to a standard format.
Selecting a suitable machine learning algorithm becomes the next important step. Depending on the task at hand and the available computational resources, researchers can choose many different algorithms. There is no universal solution that is ideal for all cases. Before solving a problem, it's essential to determine the volume of data to be worked on, the type of data interaction, the expected information from the data, and finally, the intended applications of the chosen method.
The next step in model development involves model training: feeding data to the system and adjusting its internal parameters to improve predictions. However, it is necessary to avoid the phenomenon of overfitting, in which the model performs well with training data, but loses efficiency with new data. It is also essential to prevent underfitting, where the model is underperforming with both training and new data.
Evaluating model accuracy during training is another integral step. Here the system is tested on data that was not used during training. Typically, about 60% of the data is used for training the model (training data), 20% for checking predictions, adjusting and optimizing hyperparameters (validation data). This process is crucial to maximize the accuracy of the system's predictions when presented with new information. The remaining 20% of the data is used for testing (test data).
Finally, the model deployment means providing the algorithm with new data and using the system's output for decision-making or further analysis.
It is very important to regularly assess the model’s quality indicators with new data. And if they are too low, it may require refinement.
All these steps together ensure the creation of a flexible and efficient system that can adapt to new information and make accurate predictions.
Types of Machine Learning
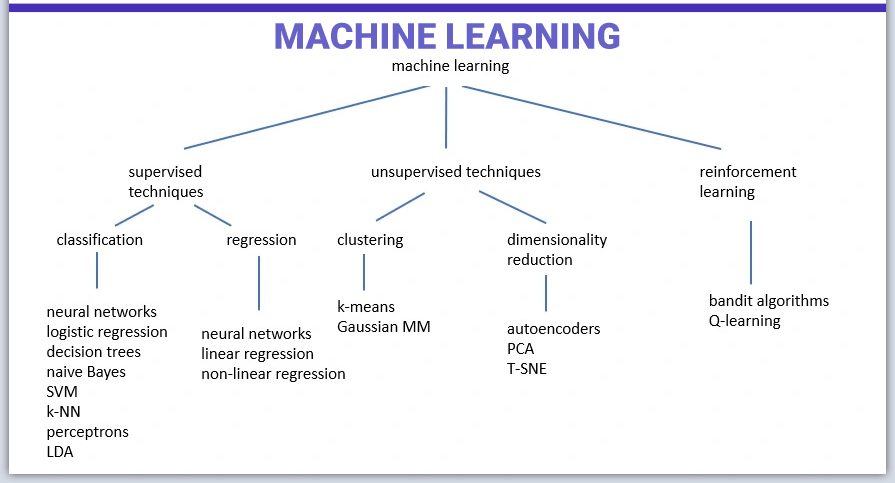
Machine learning can be divided into three main types: supervised learning, unsupervised learning and reinforcement learning. Each of these types has a specific purpose and uses different forms of data.
Supervised learning
This is a machine learning method based on the use of data that has assigned classes or labels. In this process, the engineer controls the training by providing the algorithm with large amounts of labeled data. By analyzing this data, the model identifies patterns and structures, enabling it to accurately determine the classes of objects on new data. However, achieving high accuracy requires a significant amount of labeled data, which can be a time-consuming step in the training process.
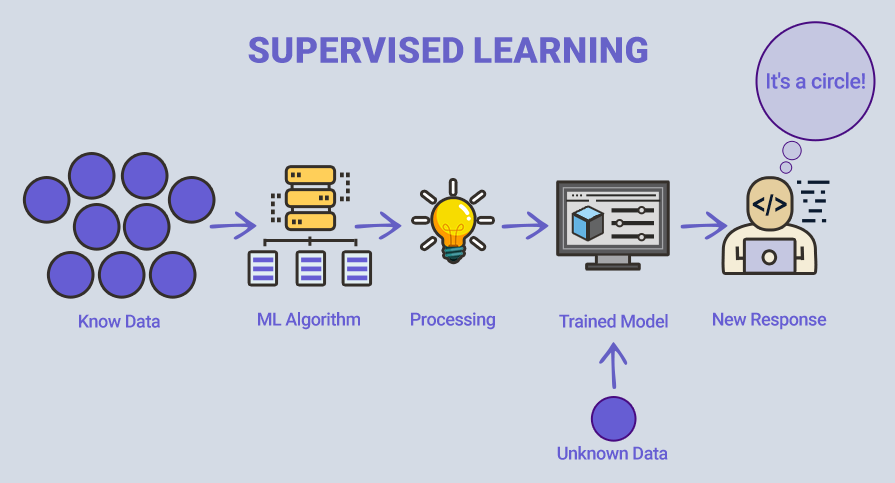
In the case shown in the illustration, the model is trying to figure out whether the data is a circle or another shape. Once the model is well-trained, it will determine that the data represent a circle and provide the desired answer.
Supervised learning can solve two types of tasks: classification and regression analysis.
Classification algorithms in machine learning are suitable for problems involving predicting whether objects belong to predefined categories or classes. They are well-suited for tasks such as:
- Pattern recognition
- Spam filtering
- Medical diagnostics
- Financial monitoring
However, classification algorithms may not be optimal for problems that require numerical value prediction (regression). They may also not work effectively in cases where classes are heterogeneous or overlapping, and when there is a lot of noise in the data. In such cases, it is better to use regression models or other types of algorithms that are more suitable for the specific conditions of the problem.
Regression analysis in supervised learning is a technique used to analyze relationships between the dependent variable (target) and one or several independent variables (features). It allows you to predict the values of the dependent variable based on the values of independent variables, identify patterns, and build models that can be used to predict values based on input data.
Several typical tasks for which regression analysis is applied include:
- Forecasting
- Economic analysis
- Marketing research
- Medical statistics
- Scientific research
- Engineering applications
Unsupervised learning
Unsupervised learning uses unknown and unlabeled data, which means that it has not been pre-categorized. Without any previously known information, the input data is fed to the machine learning algorithm to train the model. The main goal of unsupervised machine learning is to discover structure and patterns in the data, without explicit guidance in the form of target responses.
Examples of unsupervised machine learning methods include:
- Clustering: Grouping data based on similarity so that objects within one group (cluster) are more similar to each other than to objects from other groups.
- Dimensionality reduction: decreasing the number of features in the data while preserving the main characteristics of the dataset. Examples include principal component analysis (PCA) or t-distribution of stochastic neighbor embedding (t-SNE).
- Representation learning: Creating an automatic data representation that allows the model to extract significant features without explicit programming. Neural networks, such as autoencoders, can be used in this context.
- Outlier (anomaly) detection: Identifying unusual or anomalous patterns in data that differ from general trends.
- Association rules: Identifying connections and relationships between variables in a dataset, for instance, in analyzing purchasing behavior.
Unsupervised machine learning is beneficial in cases where we don't have well-defined labels or target variables and want to explore the structure of the data, identify hidden patterns, or conduct preliminary data analysis.
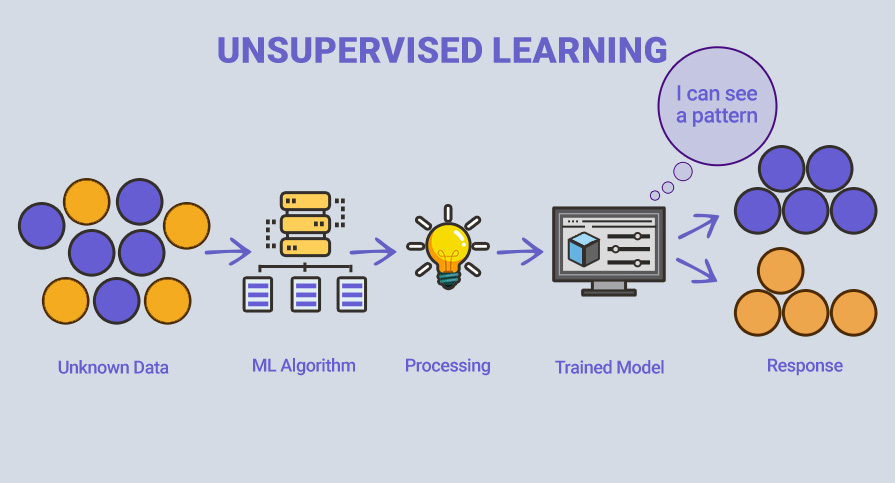
In the case presented in the illustration, the unknown data consists of shapes that resemble each other. The trained model attempts to group them together, ensuring that similar things are placed within similar groups.
Reinforcement learning
Reinforcement machine learning involves an agent, an environment, and actions, where the agent interacts with the environment to make decisions. Learning consists of choosing actions to maximize the expected reward, especially when following a reasonable strategy. In artificial intelligence, this process involves receiving a reward or penalty for each action in order to maximize the total score. This can be compared to a beginner playing a game and gradually improving performance through analyzing the relationship of actions, display and score.
Advantages and Disadvantages of Machine Learning
Machine learning provides unique benefits such as the ability to process large volumes of data, automate routine tasks, and improve prediction accuracy.
Machine learning can be used to identify data patterns that often elude human perception. It becomes possible to process a variety of data formats in dynamic, voluminous and complex data environments.
However, among its disadvantages are its dependency on the quality and quantity of the data, the cost and difficulty associated with data preparation, the high expense and resource-intensiveness of implementation without sufficient data volume, as well as the challenge of interpreting results and addressing uncertainty without the involvement of qualified experts.
This balance of advantages and disadvantages makes machine learning a valuable tool, but one that requires careful management.
Maria Lipa, QuData developer