How do neural networks learn motion? Interpretation of motion modeling using relative position change
Motion understanding has an important role in video-based cross-media analysis and multiple knowledge representation learning. A group of researchers led by Hehe Fan has studied the problems of recognizing and predicting physical motion using deep neural networks (DNNs), in particular convolutional neural networks and recurrent neural networks. The scientists developed and tested a deep learning approach based on relative position change encoded as a series of vectors, and found out that their method outperformed existing motion modeling frameworks.
In physics, motion is a relative change in position over time. To eliminate object and background factors, scientists focused on an ideal scenario in which a dot moves in a two-dimensional (2D) plane. Two tasks were used to evaluate the ability of DNN architectures to model motion: motion recognition and motion prediction. As a result, a vector network (VecNet) was developed to model relative position change. The key innovation of the scientists was to encode motion separately from position.
The group's research was published in the journal Intelligent Computing.
The study focuses on motion analysis. Motion recognition is aimed at recognizing different types of movements from a series of observations. This can be seen as one of the necessary conditions for action recognition, since action recognition can be divided into object recognition and motion recognition. For example, to recognize the action "open the door," DNNs must recognize the object "door" and the movement "open." Otherwise, the model would not distinguish "open the door" from "open the window" or "open the door" from "close the door." Motion prediction is aimed at predicting future changes in position after viewing a portion of the motion, i.e., the motion context, which can be considered one of the required conditions for video predictions.
VecNet takes short-range motion as a vector. VecNet can also move the dot to the corresponding position given by the vector representation. To gain insight into motion over time, long short-term memory (LSTM) was used to aggregate or predict vector representations over time. The resulting new VecNet+LSTM method can effectively support both recognition and prediction, proving that modeling relative position change is necessary for motion recognition and facilitates motion prediction.
Action recognition is related to motion recognition because it is related to motion. Since there is no unambiguous current DNN architecture for action recognition, the researchers have compared and studied a subset of models covering most of the domain.
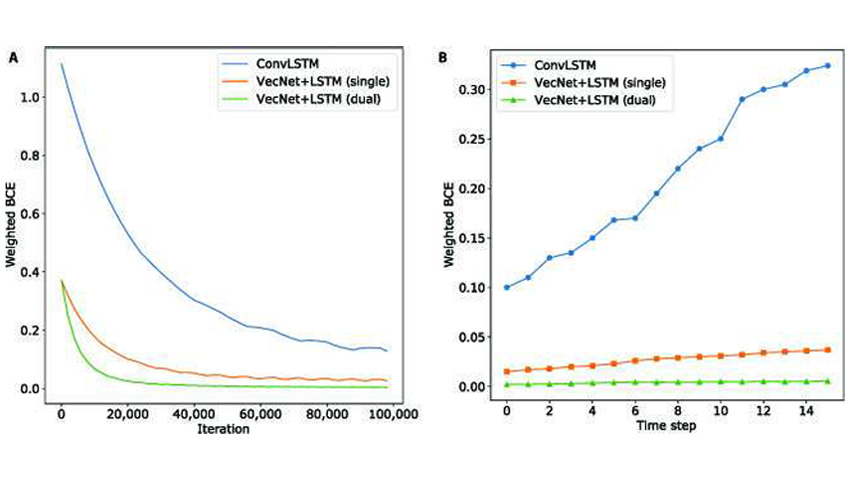
The VecNet + LSTM approach scored higher in motion recognition tests than six other popular DNN architectures from video studies on relative position change modeling. Some of them turned out to be simply weaker, and some were completely unsuitable for the motion modeling task.
For example, when compared to the ConvLSTM method, the new method was more accurate, required less training time, and did not lose precision as quickly when making additional predictions.
Experiments have demonstrated that the VecNet + LSTM method is effective for motion recognition and prediction. It confirms that the use of relative position change significantly improves motion modeling. With appearance or image processing methods, the offered motion modeling method can be used for general video understanding that can be studied in the future.