
NVIDIA’s breakthrough in synthetic data generation and AI alignment
NVIDIA has introduced the Nemotron-4 340B model family, a suite of powerful open-access models designed to improve synthetic data generation and the training of large language models (LLMs). This release includes three distinct models: Nemotron-4 340B Base, Nemotron-4 340B Instruct, and Nemotron-4 340B Reward. These models promise to significantly enhance AI capabilities across a wide range of industries, including healthcare, finance, manufacturing, and retail.
The core innovation of Nemotron-4 340B lies in its ability to generate high-quality synthetic data, a crucial component for training effective LLMs. High-quality training data is often expensive and difficult to obtain, but with Nemotron-4 340B, developers can create robust datasets at scale. The foundational model Nemotron-4 340B Base was trained on a vast corpus of 9 trillion tokens and can be further fine-tuned with proprietary data. The Nemotron-4 340B Instruct model generates diverse synthetic data that mimics real-world scenarios, while the Nemotron-4 340B Reward model ensures the quality of this data by evaluating responses based on helpfulness, correctness, coherence, complexity, and verbosity.
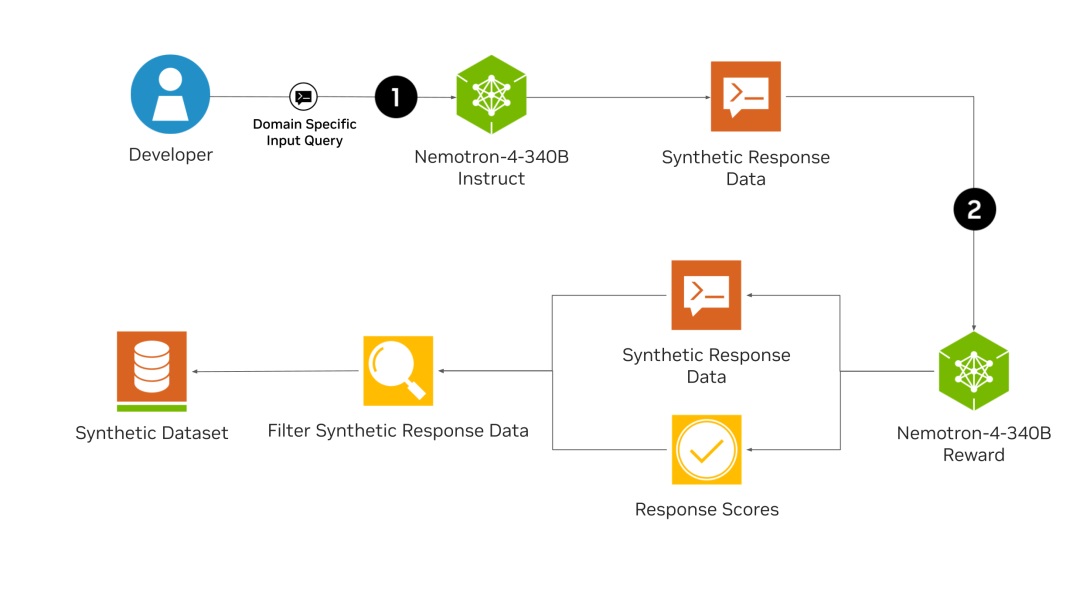
A standout feature of the Nemotron-4 340B is its sophisticated alignment process, which uses both direct preference optimization (DPO) and reward-aware preference optimization (RPO) to fine-tune the models. DPO optimizes the model's responses by maximizing the reward gap between preferred and non-preferred answers, while RPO refines this further by considering the reward differences between responses. This dual approach ensures that the models not only produce high-quality outputs but also maintain balance across various evaluation metrics.
NVIDIA has employed a staged supervised fine-tuning (SFT) process to enhance the model's capabilities. The first stage, Code SFT, focuses on improving coding and reasoning abilities using synthetic coding data generated through Genetic Instruct – a method that simulates evolutionary processes to create high-quality samples. The subsequent General SFT stage involves training on a diverse dataset to ensure the model performs well across a wide range of tasks, while also retaining its coding proficiency.
The Nemotron-4 340B models benefit from an iterative weak-to-strong alignment process, which continuously improves the models through successive cycles of data generation and fine-tuning. Starting with an initial aligned model, each iteration produces higher-quality data and more refined models, creating a self-reinforcing cycle of improvement. This iterative process leverages both strong base models and high-quality datasets to enhance the overall performance of the instruct models.
The practical applications of the Nemotron-4 340B models are vast. By generating synthetic data and refining model alignment, these tools can significantly improve the accuracy and reliability of AI systems in various domains. Developers can easily access these models through NVIDIA NGC, Hugging Face, and the upcoming ai.nvidia.com platform.