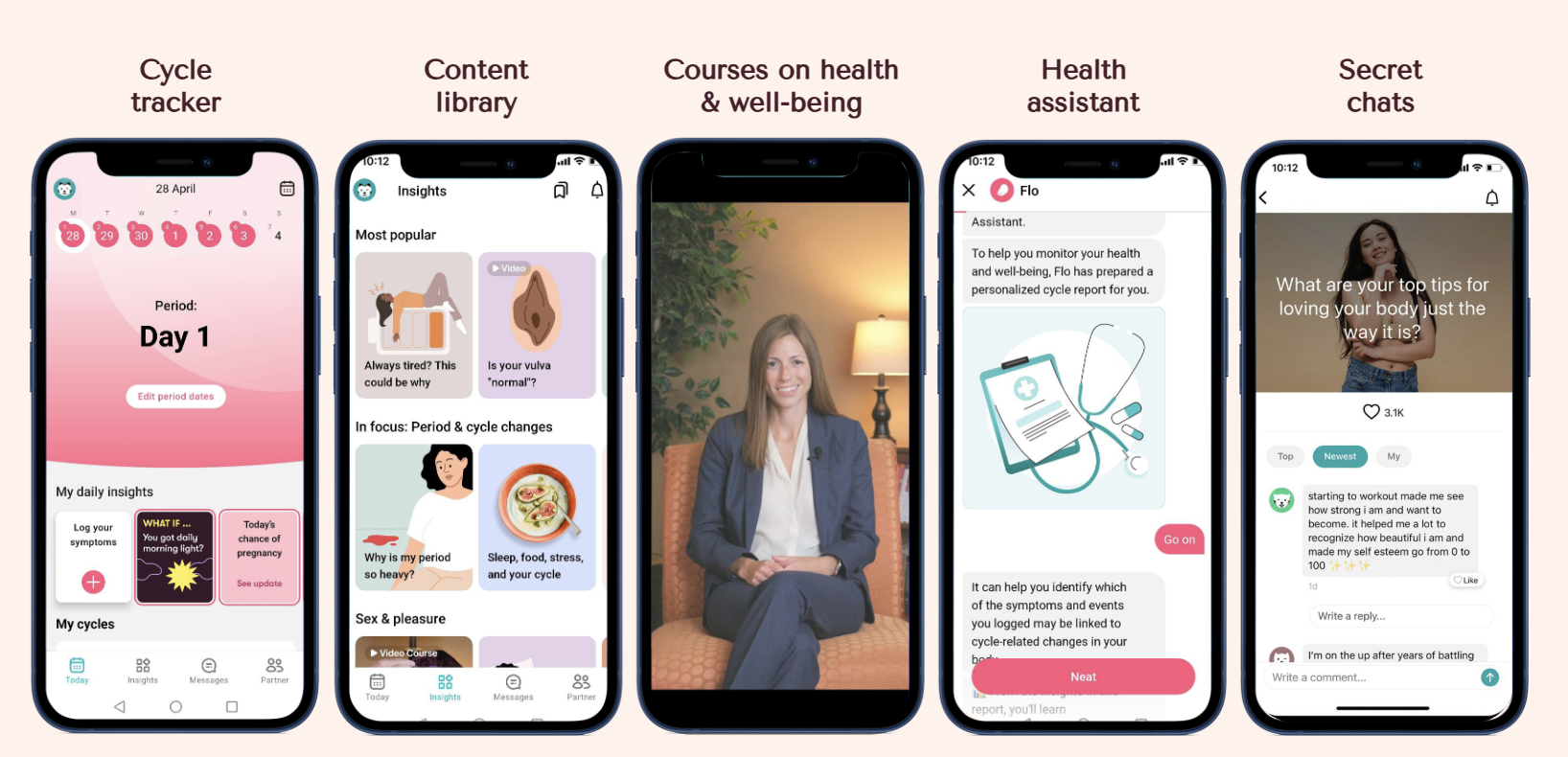
Команда разработчиков компании Flo Health использовала центр инноваций в области генеративного искусственного интеллекта AWS для создания системы проверки медицинского контента на основе ИИ, что позволило сократить время проверки на 60% и увеличить объем обрабатываемого контента в три раза. Проблемы масштабирования процесса проверки медицинских материалов были решены с помощью специализированны...
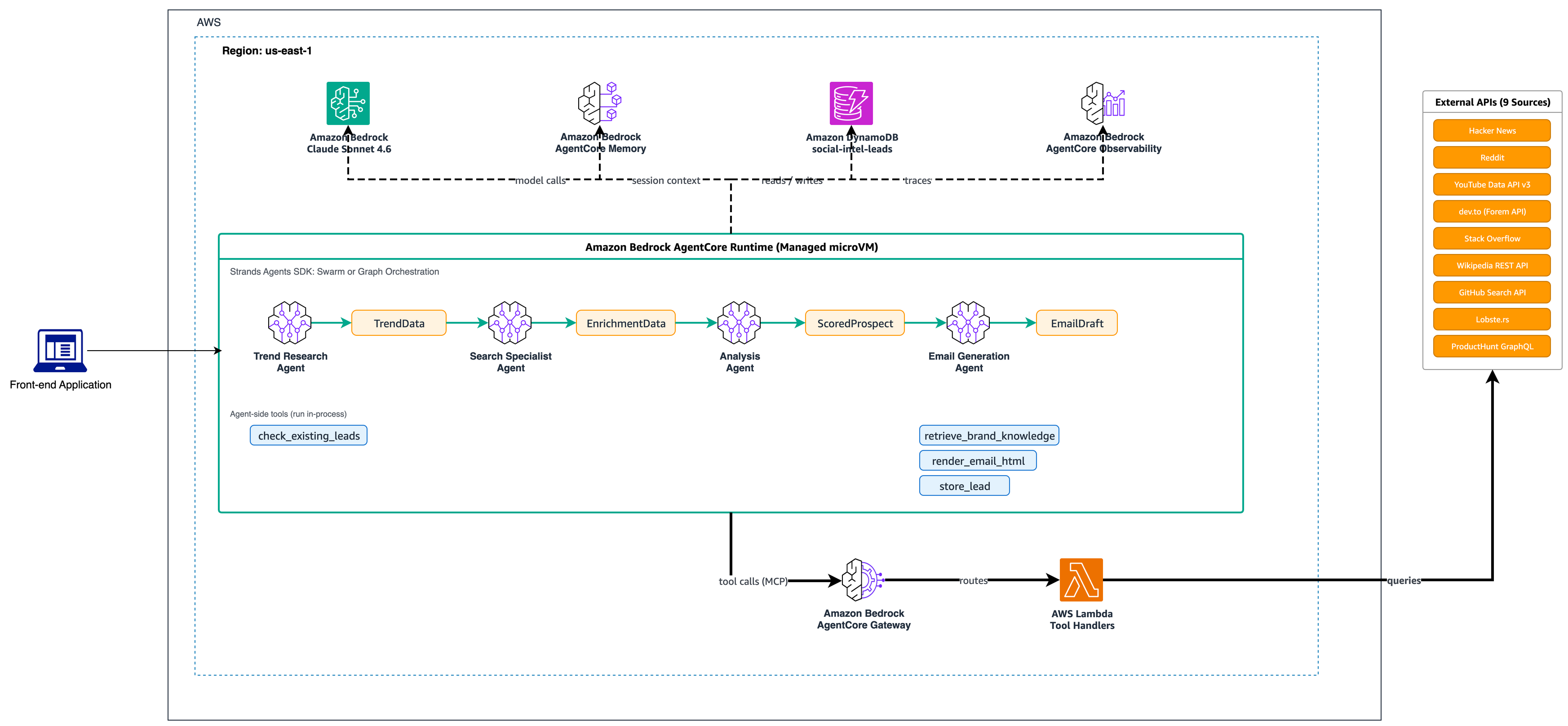
Thrad.ai использует технологии Strands Agents и Amazon Bedrock AgentCore для автоматизации сбора информации в социальных сетях с целью повышения эффективности таргетированной рекламы. Система многоагентной обработки данных позволяет выявлять потенциальных клиентов на различных платформах, что улучшает качество и эффективность email-рассылок.
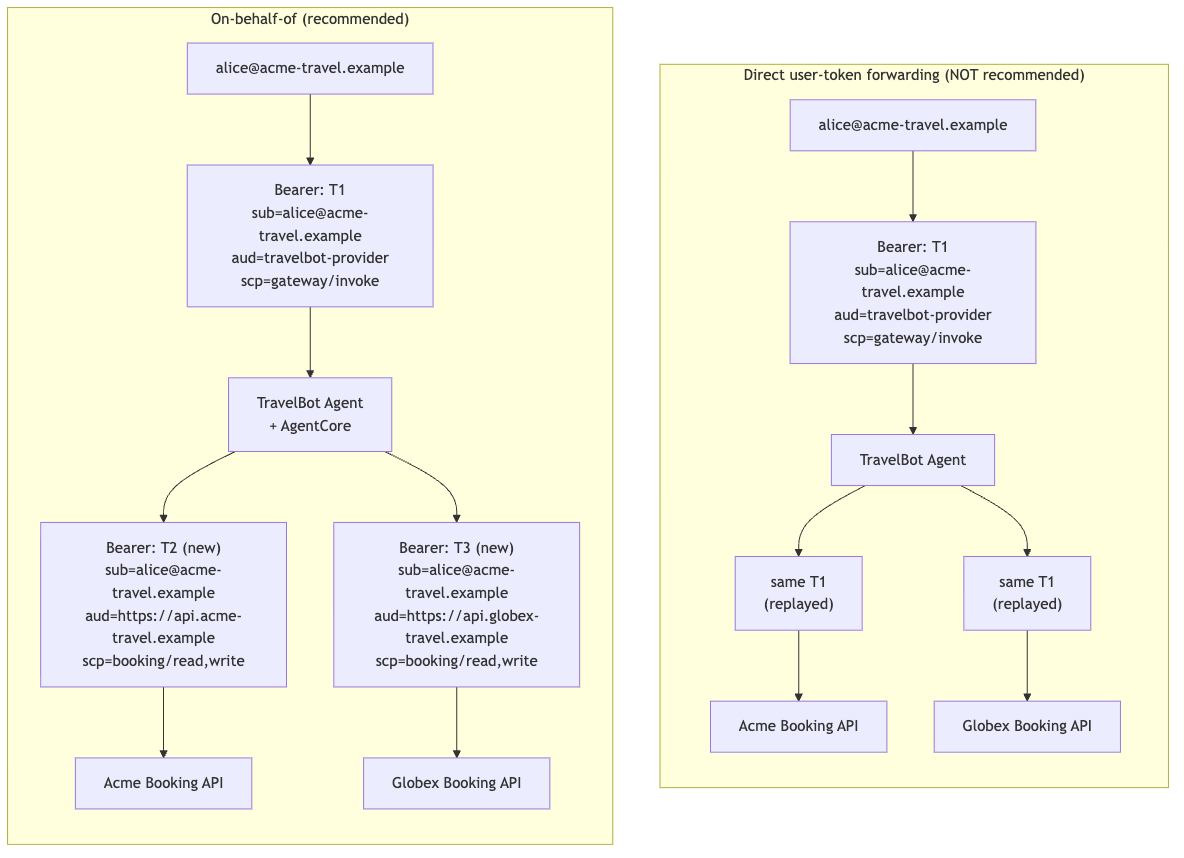
Amazon Bedrock AgentCore Identity поддерживает обмен токенами OAuth 2.0 для многопользовательских агентов, решая проблемы идентификации в системах с использованием агентов. Руководство по настройке описывает процесс настройки обмена токенами от имени пользователя в многопользовательском помощнике бронирования, обеспечивая безопасный и масштабируемый контроль доступа.

Ученые из Массачусетского технологического института, в сотрудничестве с организацией Thorn, разработали метод аудита для обнаружения моделей искусственного интеллекта, предназначенных для создания вредоносного контента, такого как материалы сексуального насилия над детьми (CSAM), с 100% точностью. Эта инновационная технология может помочь платформам выявлять и удалять опасные модели, что являе...

Центр кибербезопасности Массачусетского технологического института, основанный в 2019 году, предоставляет студентам практическое обучение и проводит бесплатные оценки рисков кибератак для уязвимых сообществ. Атаки программ-вымогателей (ransomware) против муниципальных органов представляют собой растущую угрозу, и на сегодняшний день проведено более 40 таких оценок.
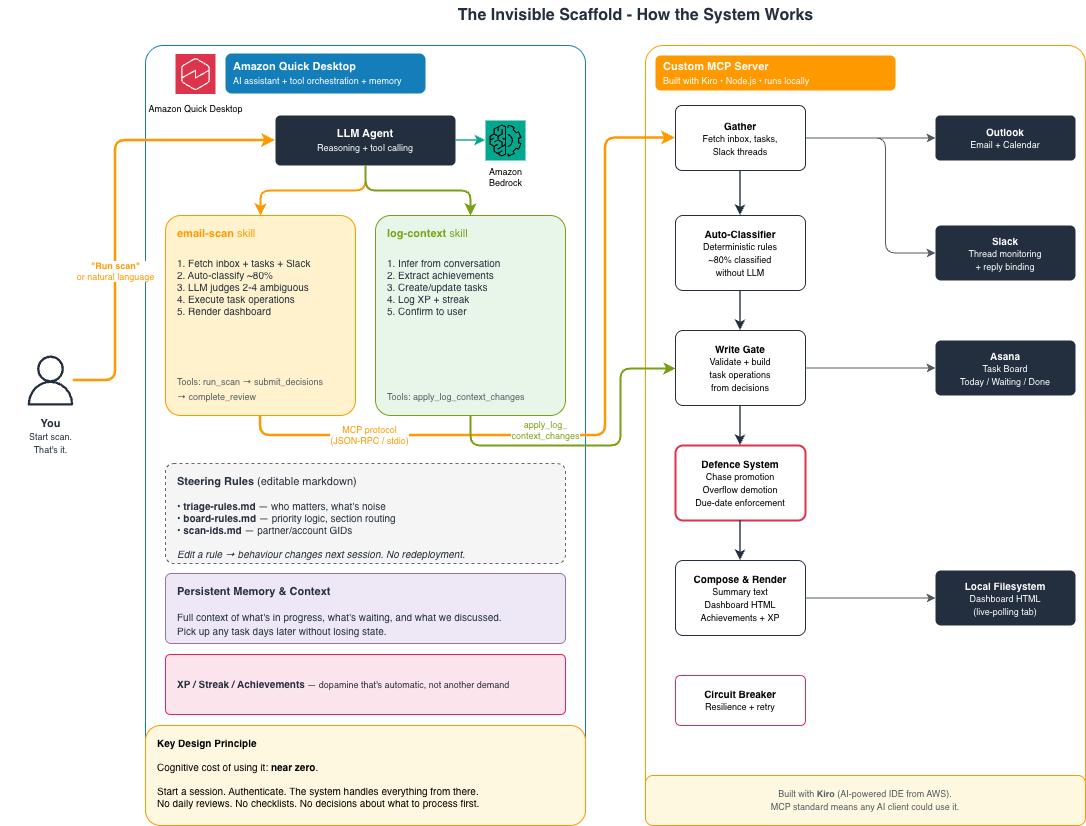
Архитектор программного обеспечения с нейроотличиями использует искусственный интеллект для создания инструмента, обеспечивающего доступность и компенсирующего недостатки в исполнительных функциях. Система рабочих процессов на основе искусственного интеллекта помогает поддерживать организационные системы для специалистов с нейроотличиями.
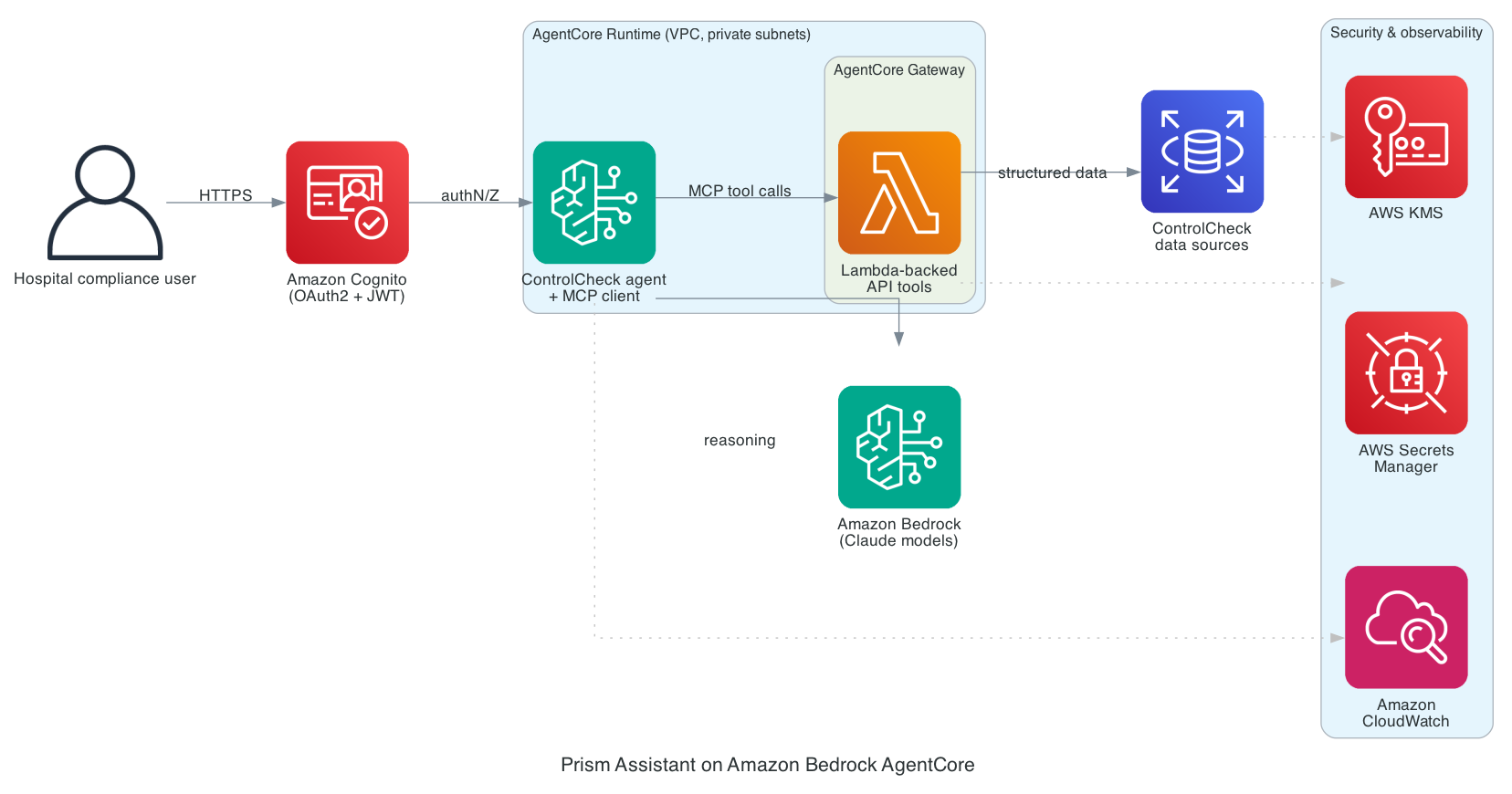
Решение на основе искусственного интеллекта компании Bluesight, под названием Prism, упрощает соблюдение требований программы ценообразования лекарственных препаратов 340B для больниц за счет анализа данных из различных систем, что позволяет сэкономить тысячи часов работы. Это унифицированное решение на базе агентного ИИ, представленное в мае 2026 года, решает сложные задачи соответствия требов...
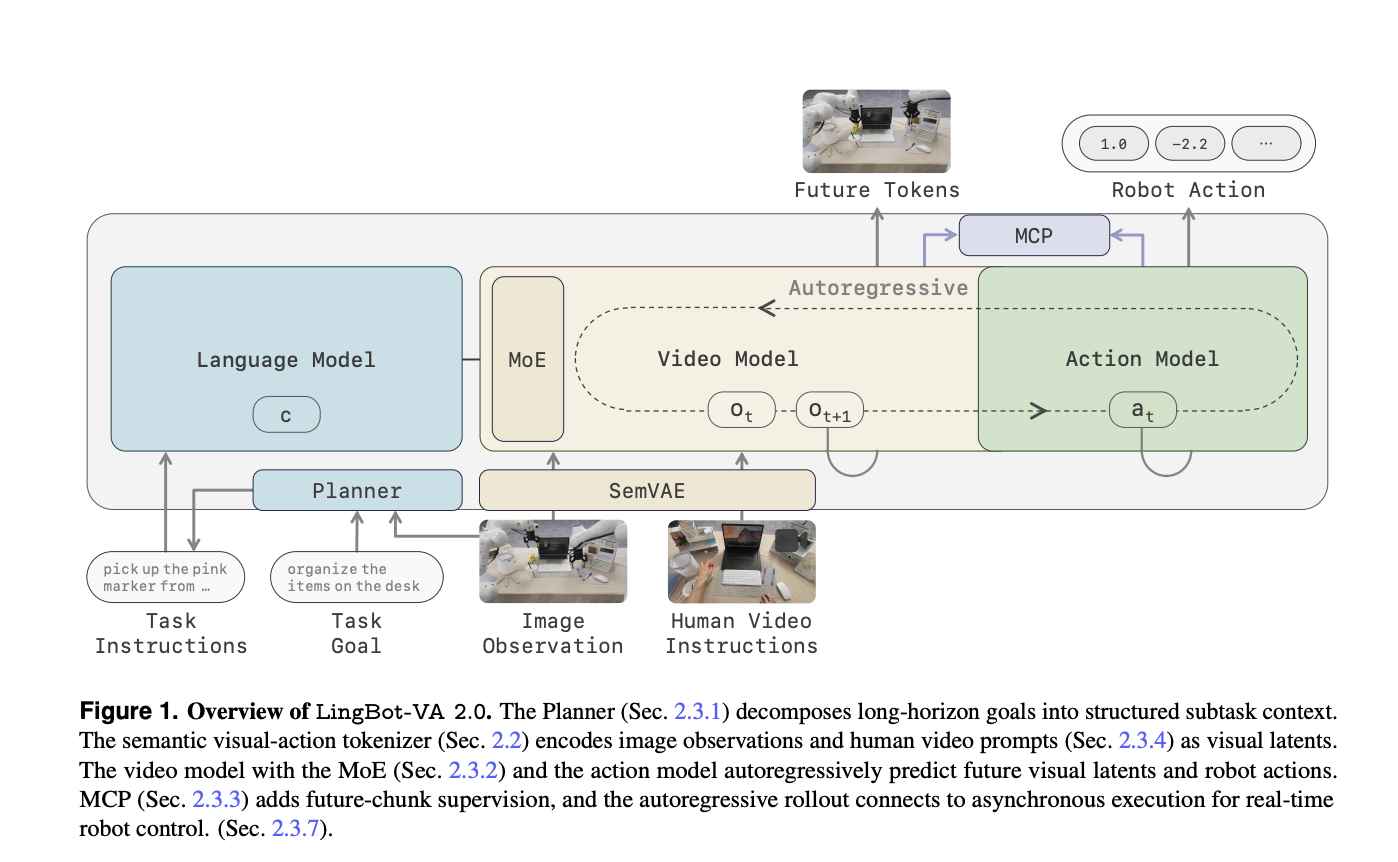
LingBot-VA 2.0 от Robbyant – это первая специализированная модель машинного обучения для управления роботами. Она использует архитектуру DiT и проходит предварительное обучение, что позволяет преодолеть ограничения, присущие моделям, работающим с видеоданными.
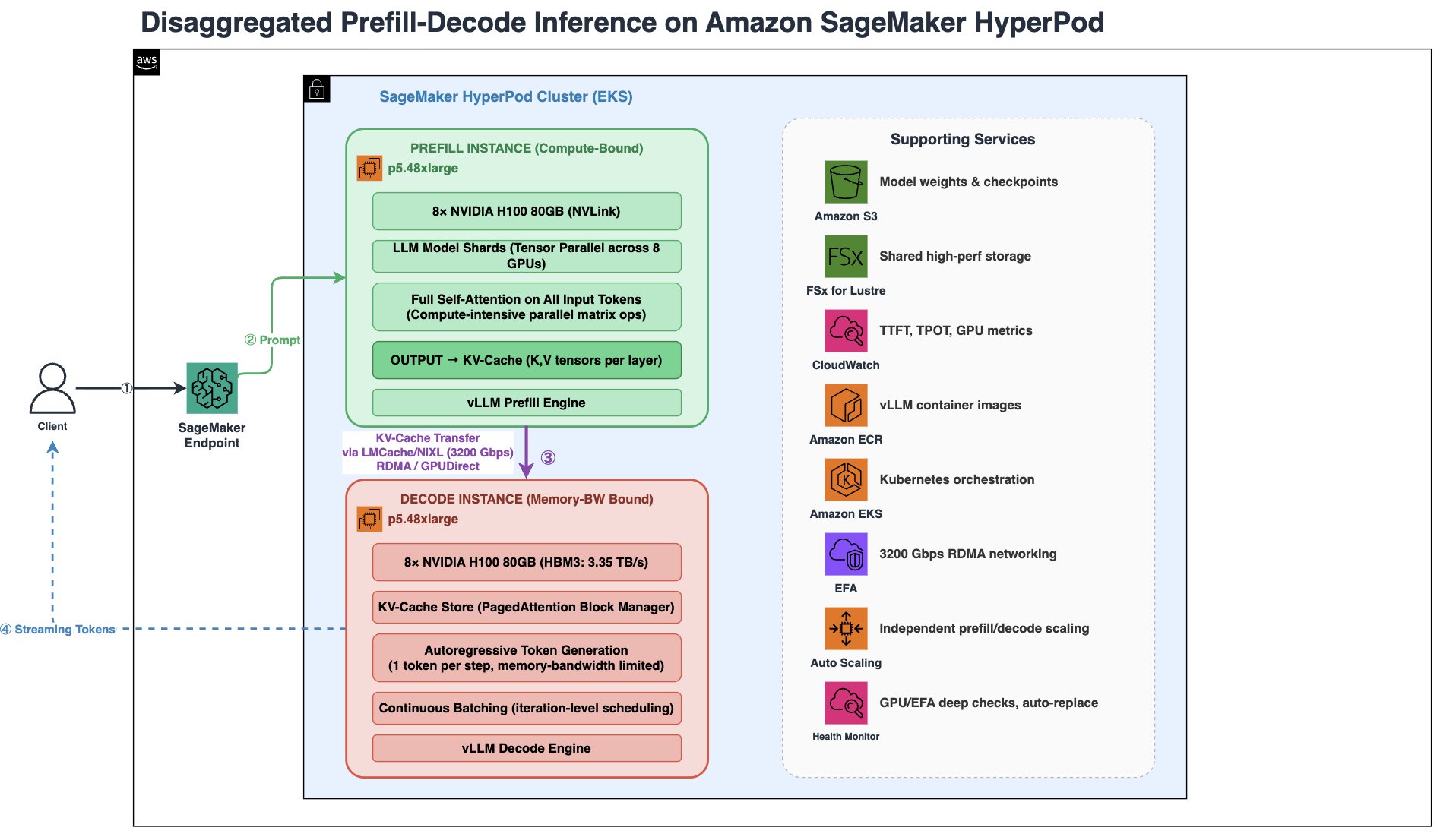
Технология Disaggregated Prefill and Decode (DPD) в Amazon SageMaker HyperPod оптимизирует работу больших языковых моделей (LLM) за счет разделения этапов вычислений и операций с памятью, используя специализированные вычислительные блоки, соединенные через EFA с поддержкой RDMA. DPD повышает эффективность при работе с задачами, требующими высокой степени параллелизма и длинными запросами, устра...
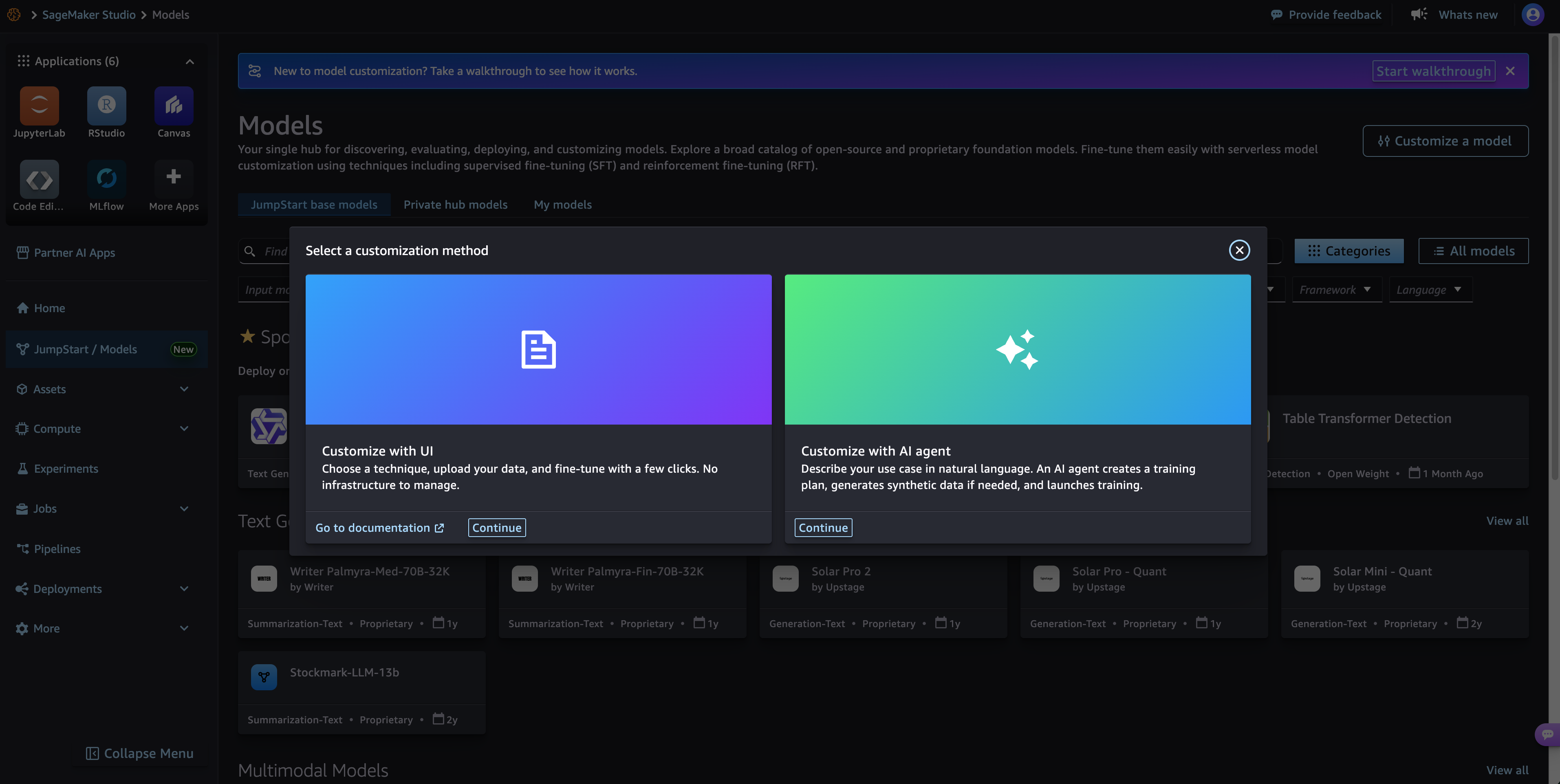
Настройка моделей позволяет превратить универсальные модели искусственного интеллекта в специализированные корпоративные решения путем дообучения на данных, относящихся к конкретной области. Платформа Amazon SageMaker AI предлагает возможность серверной настройки для моделей NVIDIA Nemotron 3, обеспечивая высокую производительность и экономию затрат для организаций.
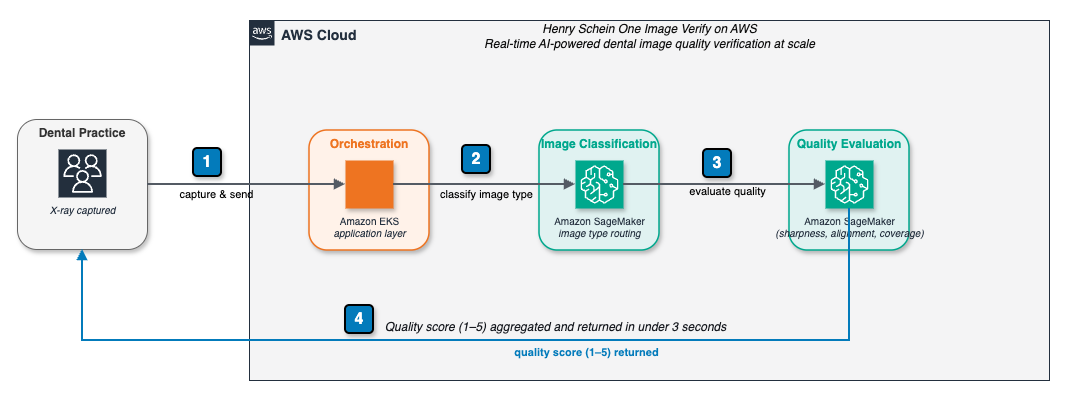
Система Image Verify от Henry Schein One использует искусственный интеллект для оценки качества рентгеновских снимков в стоматологии в режиме реального времени, что позволяет снизить количество отказов по страховым выплатам и повысить эффективность рабочих процессов. Эта система, разработанная на базе Amazon SageMaker AI, обработала более 11 миллионов рентгеновских снимков и продолжает масштаби...
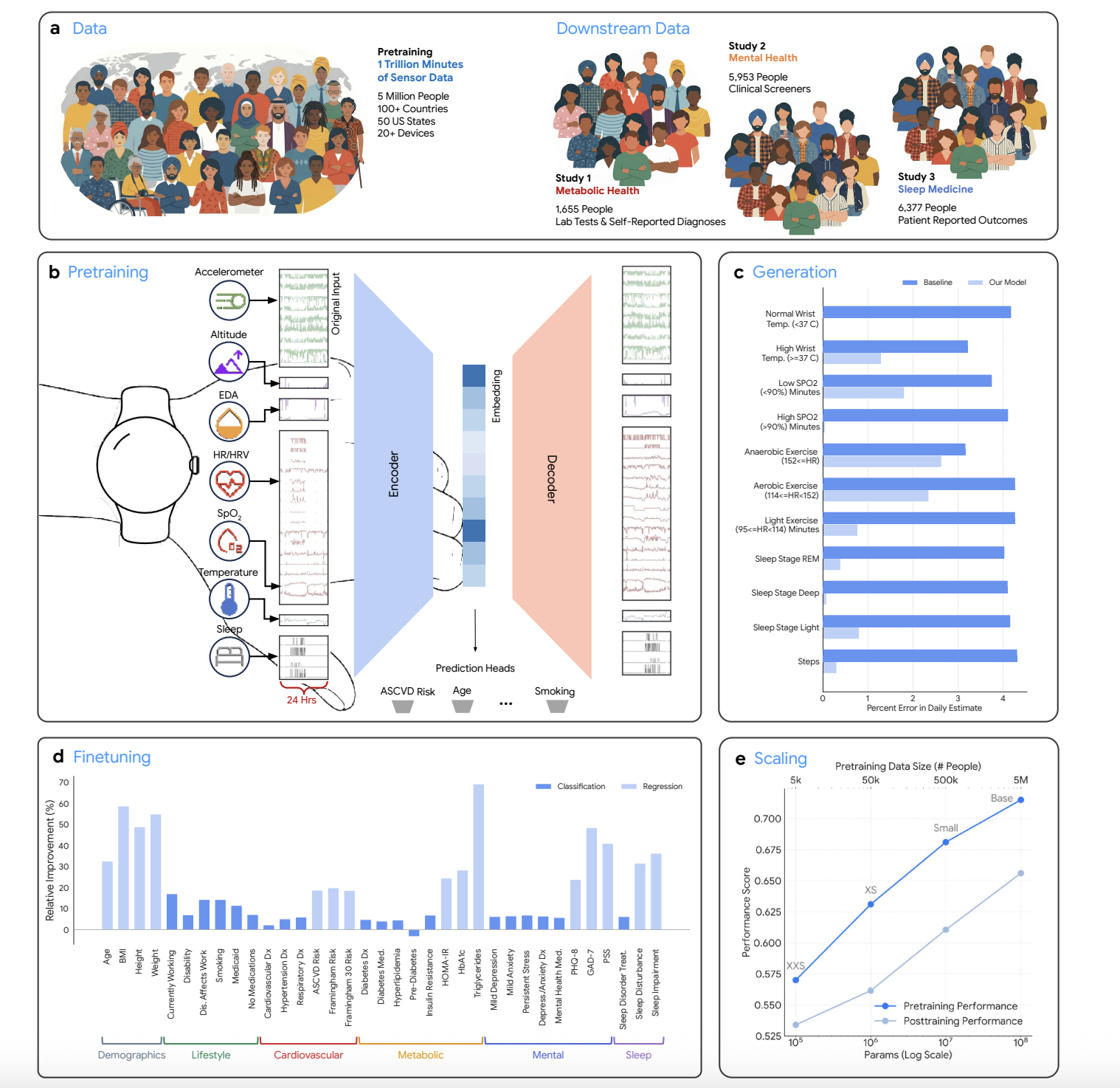
Компания Google Research представила SensorFM, базовую модель, предварительно обученную на данных от датчиков, собранных от 5 миллионов человек в течение триллиона минут. Она превосходит более компактные версии в 35 задачах, связанных со здоровьем, и демонстрирует перспективные результаты в области анализа данных о здоровье с использованием носимых устройств.

Динамическая квантизация от компании Unsloth позволяет снизить потребление памяти при сохранении точности модели, что обеспечивает экономию средств и более быструю развертывание на инфраструктуре AWS. Эта методика выходит за рамки простой унифицированной компрессии, анализируя и распределяя биты в зависимости от чувствительности каждого слоя для достижения оптимальной производительности.

Исследователи из Массачусетского технологического института разработали систему "FloatForm", состоящую из роботизированных лодок, которые самостоятельно собираются в конструкции на воде, предлагая возможности для создания адаптивной инфраструктуры. Проект предполагает будущее, в котором автономные лодки будут создавать мосты, платформы и другие сооружения по требованию, расширяя общественные пр...
Представляем Nemotron Labs: оптимальное решение для обеспечения высокой производительности серверов.
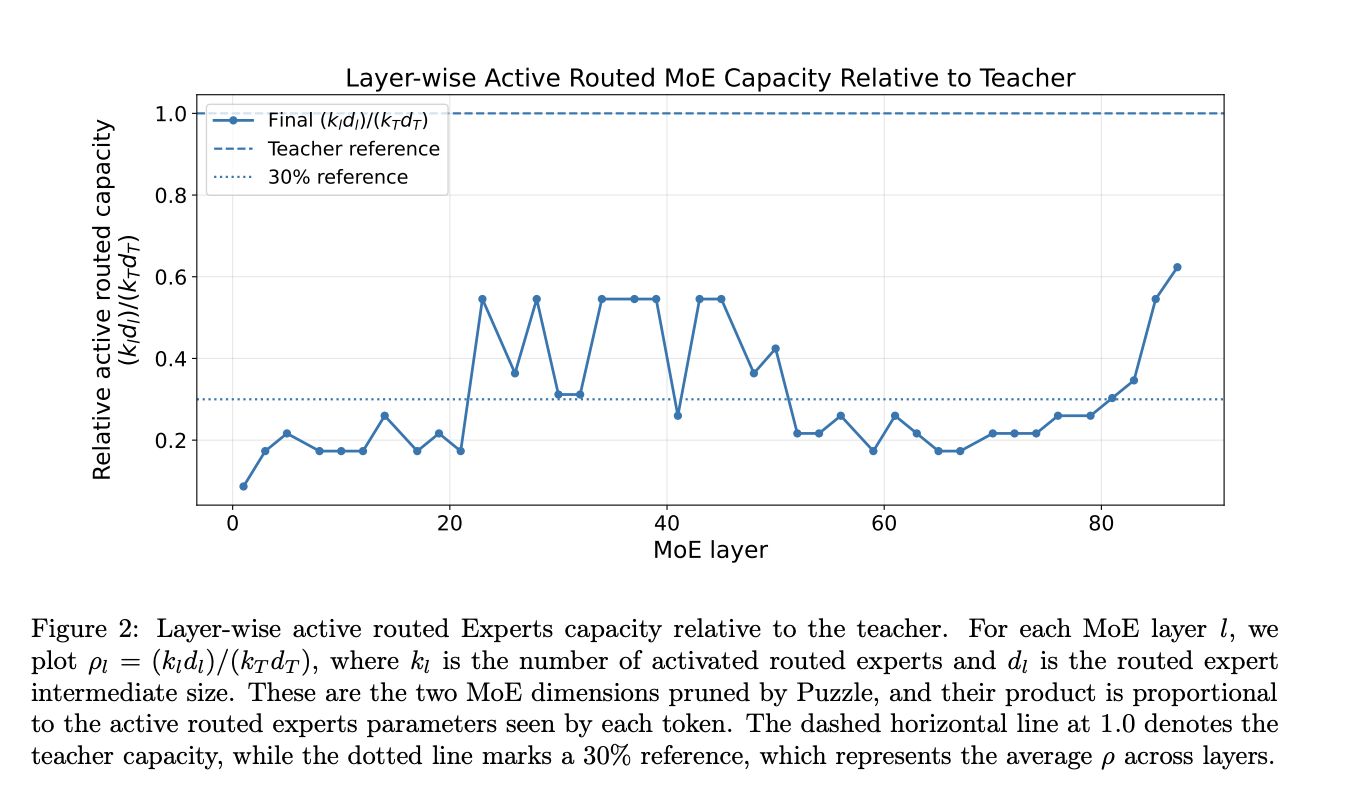
Модель NVIDIA AI team под названием Nemotron-Labs-3-Puzzle-75B-A9B представляет собой оптимизированную версию Nemotron-3-Super, которая увеличивает производительность в 2.14 раза на одной видеокарте H100. Модель сохраняет оригинальную структуру и обеспечивает значительное повышение производительности благодаря выборочному уменьшению вычислительной нагрузки.