
Anthropic грозит штраф от Пентагона из-за спора о модели искусственного интеллекта. Представители Министерства обороны США не могут прийти к соглашению по поводу использования в военных целях мощной модели искусственного интеллекта Claude, разработанной компанией Anthropic.
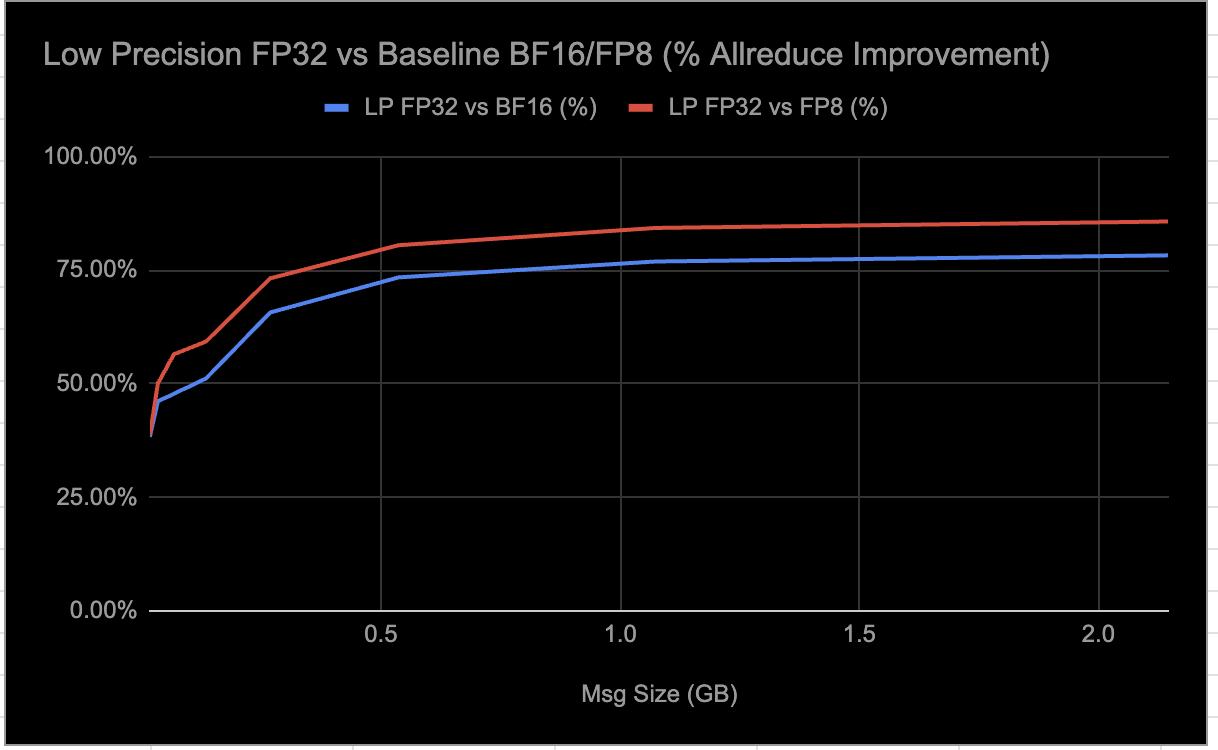
Meta открывает исходный код RCCLX, интегрируя CTran для платформ AMD и улучшая AllToAllvDynamic. DDA и Low Precision Collectives значительно повышают производительность AMD, сокращая задержку до 30%.
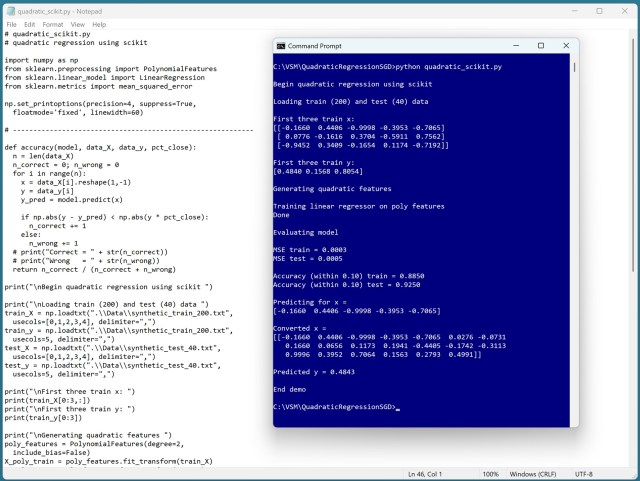
Квадратичная регрессия добавляет квадратичные предикторы и термины взаимодействия для комплексного анализа данных. Демонстрация с использованием библиотеки scikit-learn показывает веса модели и точность прогнозирования.

США борются с задержками и отменами строительства новых центров обработки данных на фоне бума искусственного интеллекта из-за проблем с цепочкой поставок, нехватки энергии и сопротивления местного населения. Инвесторы осторожно относятся к возможному «пузырю» искусственного интеллекта, который может повлиять на расширение инфраструктуры.

Акции Uber, Mastercard и American Express падают из-за спекулятивного сценария апокалипсиса искусственного интеллекта от Citrini Research на Substack. Инвесторы встревожены предупреждением о том, что автономные системы искусственного интеллекта в ближайшем будущем могут нарушить экономику США.

Структурированные выводы в приложениях искусственного интеллекта имеют решающее значение для обеспечения согласованности и валидации. Фреймворк Outlines от .txt на AWS Marketplace улучшает генеративный искусственный интеллект для точного обмена данными и сокращения ошибок в условиях высоких рисков.
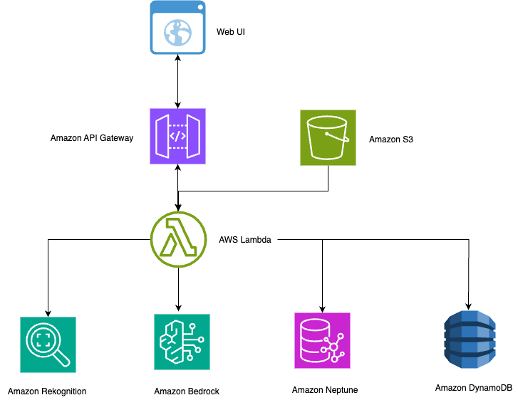
Интеллектуальные системы поиска фотографий используют компьютерное зрение и обработку естественного языка, чтобы революционизировать организацию фотографий. Amazon Rekognition, Neptune и Bedrock позволяют осуществлять персонализированный поиск с помощью сложного отображения взаимосвязей между тысячами изображений.

Эксперт по искусственному интеллекту Тоби Уолш критикует австралийское правительство за отсутствие регулирования в сфере ИИ и предупреждает о риске развития психозов при взаимодействии с чат-ботами. Стремление Кремниевой долины к получению прибыли с помощью технологий ИИ Уолш называет «неосторожным» и предсказывает, что гонка в сфере ИИ принесет как выгоды, так и риски.

Владелец Meta покупает у AMD чипы для искусственного интеллекта на сумму 60 млрд долларов, что является частью тенденции к увеличению расходов на искусственный интеллект в США до 660 млрд долларов, «большой ставки» на искусственный интеллект. Аналитики предполагают, что это может сигнализировать о повороте в стратегии Meta в области искусственного интеллекта.

Искусственный интеллект обманывает нас реалистичными онлайн-сценариями, стирая грань между реальностью и технологиями. Юмористический ролик в Instagram с 3D-дырой в Нью-Йорке вызывает экзистенциальные сомнения о том, что является реальностью.

Технологические миллиардеры вкладывают деньги в промежуточные выборы в Калифорнии; Индия бросает вызов доминированию США и Китая в области искусственного интеллекта на саммите. Беспокойство по поводу искусственного интеллекта вызывает движение работников.

Генеральный директор Nine Entertainment призывает премьер-министра уделить приоритетное внимание переговорам с Google, Meta и TikTok о кодексе новостных сделок. Искусственный интеллект, лежащий в основе крупных технологических компаний, нарушает модели доходов издателей по всему миру, что создает риск дальнейших задержек.
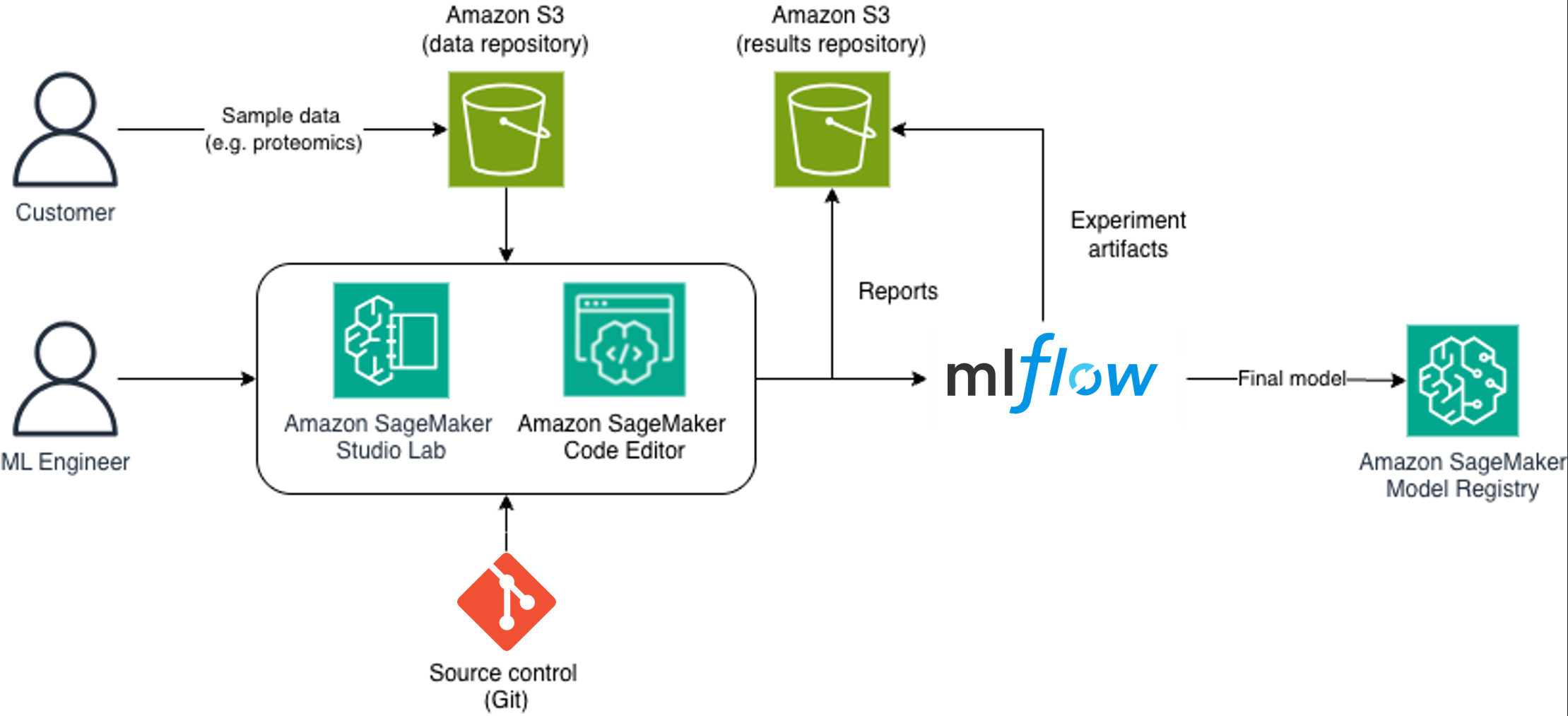
Исследователи в области прецизионной медицины сталкиваются с проблемами при работе с наборами данных в тестах для раннего выявления заболеваний. Компания Sonrai в партнерстве с AWS создала надежную инфраструктуру MLOps с использованием искусственного интеллекта Amazon SageMaker для обеспечения отслеживаемости и воспроизводимости в регулируемых средах.

На фоне опасений, что искусственный интеллект заберет рабочие места, остается важный вопрос: как мы будем питаться? Несмотря на исторические опасения, необходимо провести серьезную дискуссию о потенциальной потере рабочих мест.

Ofgem предупреждает, что 140 проектов центров обработки данных, основанных на искусственном интеллекте, могут превысить пиковую потребность Великобритании в электроэнергии, которая составляет 50 ГВт, что на 5 ГВт выше текущего уровня.