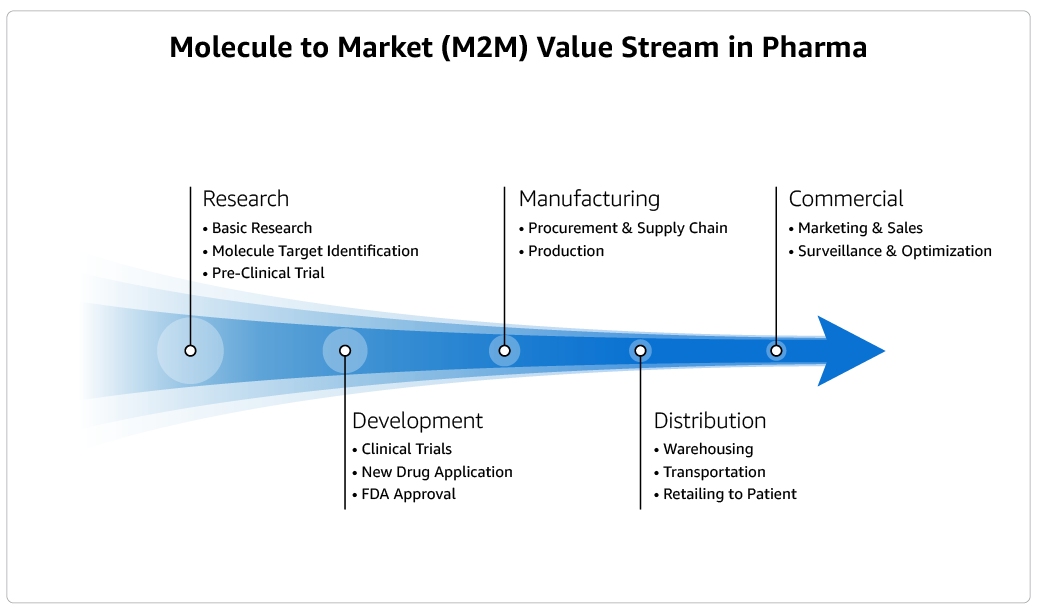
Біофармацевтичні компанії стикаються з проблемами при розробці нових ліків, але AWS допомагає оптимізувати процеси. Генетична валідація та генеративний ШІ революціонізують процес розробки ліків, покращуючи користувацький досвід та підвищуючи ефективність досліджень.
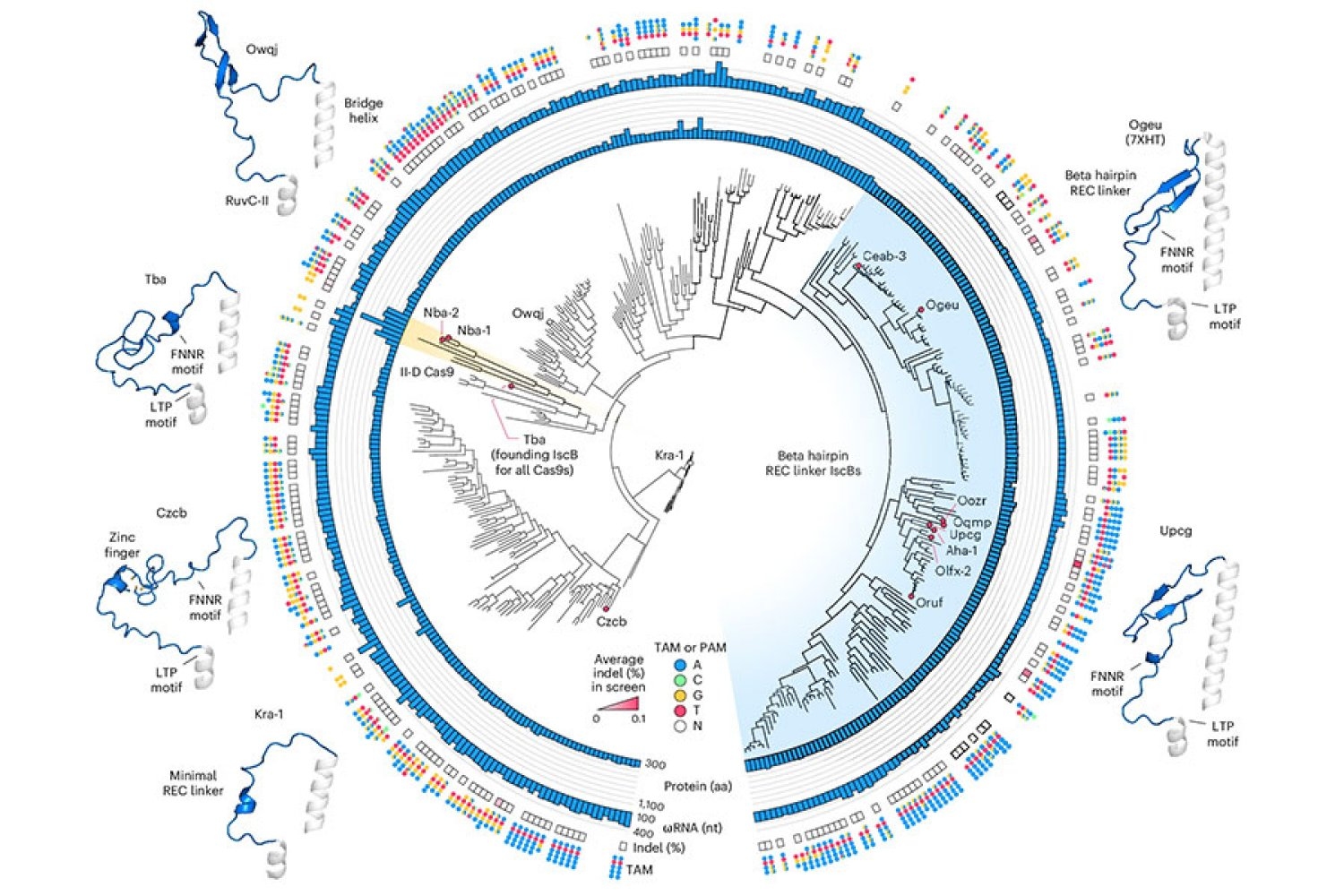
Вчені з Інституту досліджень мозку ім. Макговерна при Массачусетському технологічному інституті та Інституту Броуда переробили компактний РНК-керований фермент з бактерій на точний редактор людської ДНК під назвою NovaIscB. NovaIscB, розроблений командою Фенга Чжана, є перспективним для генної терапії завдяки своєму невеликому розміру та потенціалу для точних генетичних змін.

Технологічний журналіст Карен Хао розкриває секретність OpenAI, незважаючи на публічний імідж прозорої неприбуткової організації. Безпрецедентне зростання компанії порівнюють з новою формою імперії.

Nestlé та інші британські компанії використовують штучний інтелект для скорочення харчових відходів, досягнувши скорочення на 87% всього за два тижні. Інструмент спрямований на перерозподіл надлишків продуктів і страв, що революціонізує управління відходами.

GuardianGamer, хмарна ігрова платформа, використовує сервіси AWS, щоб допомогти батькам контролювати онлайн-ігри дітей ненав'язливо. Вона надає інформацію про ігрову діяльність та соціальну взаємодію, створюючи безпечне та цікаве ігрове середовище для сімей.

Amazon Bedrock Data Automation впорядковує розробку, надаючи користувацьку інформацію з відео та аудіо, підвищуючи ефективність і позбавляючи від зайвої роботи. Air, програмний продукт, використовує Amazon Bedrock Data Automation для аналізу відео, керуючи контентом для таких світових брендів, як Google і P&G.
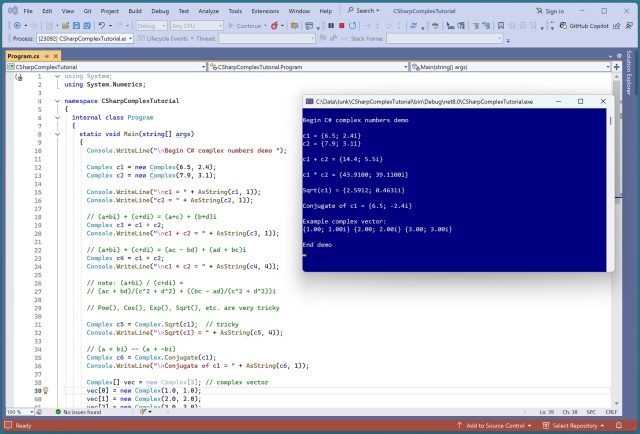
У мові C# є комплексний тип чисел для складних задач, таких як обчислення власних значень. Комплексні числа можуть бути як простими, так і складними, що робить такі операції, як добування квадратних коренів, складними.

Массачусетський технологічний інститут (MIT) запустив Ініціативу нового виробництва (Initiative for New Manufacturing), щоб революціонізувати американське промислове виробництво за допомогою передових технологій та партнерств. Ініціатива спрямована на створення високоякісних, орієнтованих на людину виробничих робочих місць і вже заручилася підтримкою таких лідерів галузі, як Amgen, GE Vernova ...

Професор Массачусетського технологічного інституту Деваврат Шах наголошує на важливості фундаментальних математичних навичок для ефективного використання інструментів штучного інтелекту. Мікромагістерська програма зі статистики та науки про дані дає можливість студентам з усього світу зрозуміти концепції штучного інтелекту та впливати на реальний світ.

Професор Маттео Валеріані наголошує на необхідності відкритого доступу до магістерських програм з історичних досліджень, які керуються етикою, а не прибутком. Цілі приватних компаній часто суперечать цінностям історичної науки, таким як прозорість і доступність.

Стівен Рю, генеральний директор Optus, підкреслює роль штучного інтелекту в поліпшенні обслуговування клієнтів. Люди залишаються центральною ланкою у прийнятті рішень в компанії.

Батлеру Сноу загрожують санкції за цитування неправдивої судової практики на захист ув'язненого, який отримав 20 ножових поранень у в'язниці Вільяма Е. Дональдсона. Френкі Джонсон розповідає, що отримав кілька ножових поранень протягом короткого періоду часу, підкреслюючи серйозні проблеми з безпекою.

Урядовий план дозволяє масовій культуріТворці, включаючи Елтона Джона, борються проти підриву закону про авторське право.

Камери розпізнавання облич в реальному часі можуть стати «звичайною справою» в Англії та Уельсі, незважаючи на антиутопічні побоювання. У Кройдонському Норт-Енді можуть бути встановлені перші у Великій Британії стаціонарні камери, які використовуватимуть біометричні дані для оповіщення та потенційних арештів.
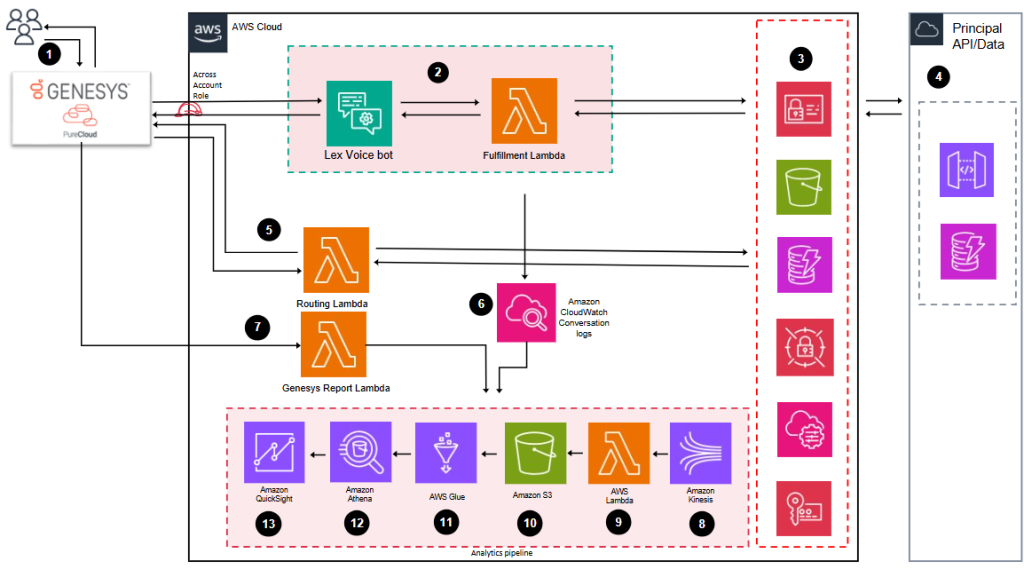
Principal Financial Group® покращила якість обслуговування клієнтів, впровадивши хмарний підхід за допомогою Amazon Lex та Genesys Cloud. Інтеграція дозволила персоналізувати взаємодію з клієнтами та покращити загальний клієнтський досвід завдяки розумінню природної мови та інтелектуальній маршрутизації.