
Дослідники з MIT та Microsoft розробили систему Murakkab, інтелектуальну платформу, яка автоматизує проєктування та оптимізацію складних робочих процесів, зменшуючи споживання енергії та витрати, водночас підвищуючи продуктивність. Цей новий метод дозволяє розробникам описувати завдання простою мовою, а система динамічно обирає найкращі моделі, інструменти та конфігурації обладнання на основі п...
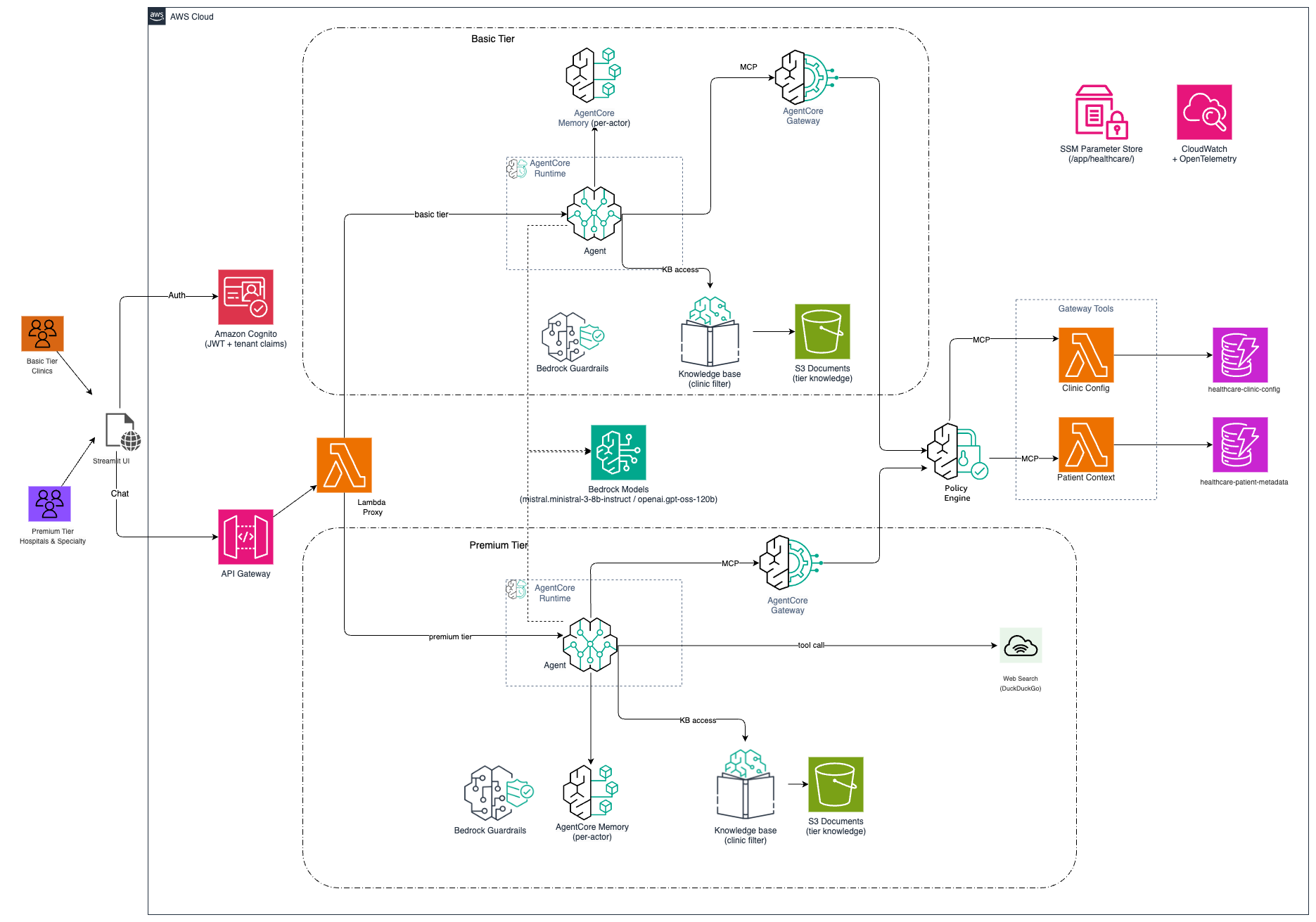
Реалізація багатокористувацьких (multi-tenant) додатків на основі штучного інтелекту вимагає повного ізолювання, диференціації рівнів обслуговування та відстеження витрат. Дізнайтеся, як Amazon Bedrock AgentCore забезпечує масштабовані рішення для AI-агентів у сфері охорони здоров'я, які обслуговують численні клініки та лікарні. Така архітектура дозволяє надавати різноманітні послуги користувач...
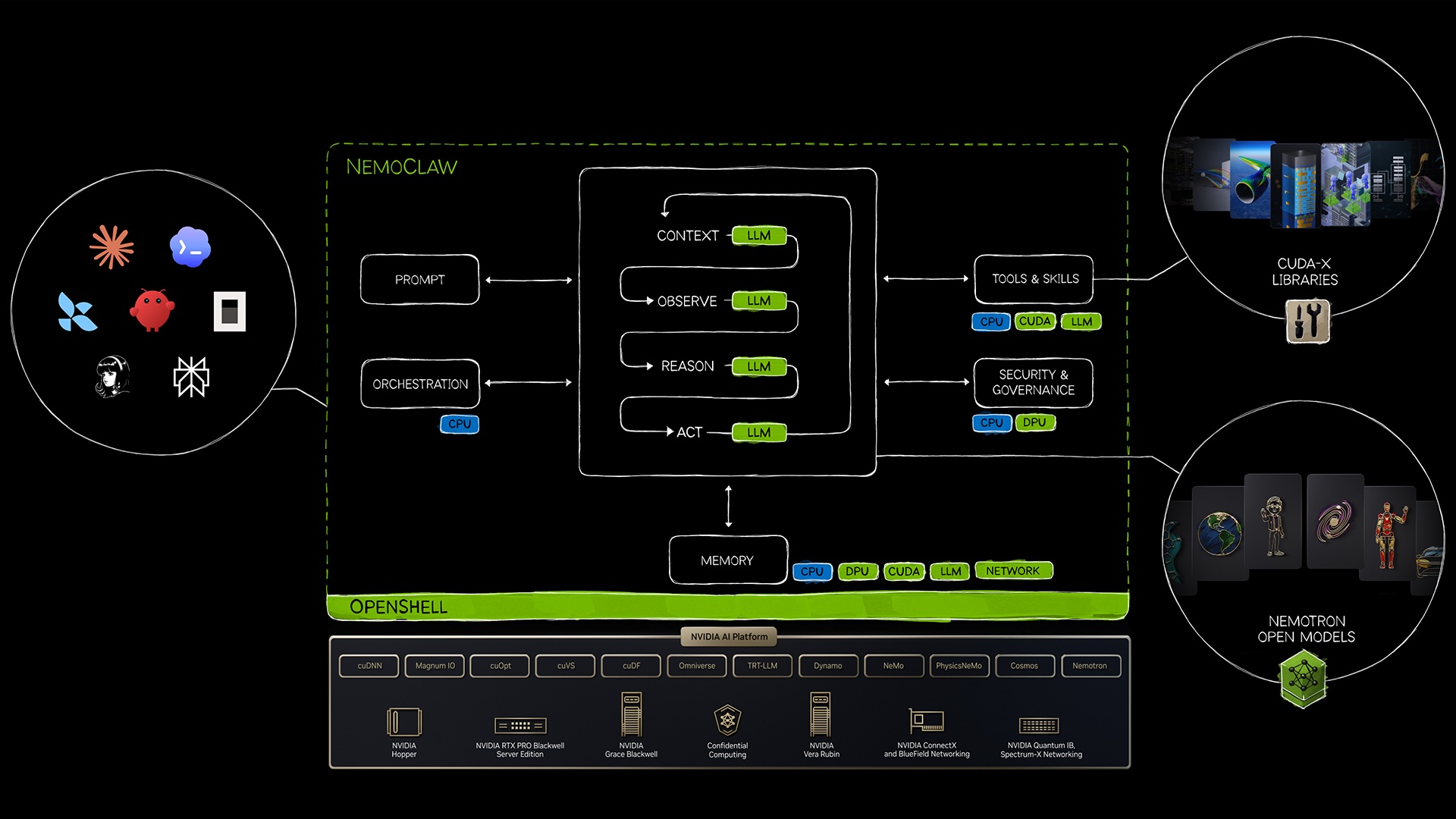
Спеціалізовані AI-агенти, такі як ті, що представлені в наборі інструментів NVIDIA Agent Toolkit, трансформують різні галузі промисловості, забезпечуючи можливості для створення кастомізованих та ефективних робочих процесів з використанням відкритих моделей і надійної підтримки виконання. Ці агенти революціонізують дослідження в медицині, розслідування у сфері безпеки та координацію ланцюгів по...

Експерти з форуму "Штучний інтелект і суспільство" Массачусетського технологічного інституту обговорили вплив штучного інтелекту на ринок праці та громадське обговорення. Економіст Девід Автор поставив під сумнів твердження, що штучний інтелект лише призведе до скорочення робочих місць, наголошуючи на важливості людського досвіду та знань.

Дослідники з Массачусетського технологічного інституту розробили мікросхему з низьким енергоспоживанням для безпілотних літальних апаратів (БПЛА), яка дозволяє ефективно створювати тривимірні карти в режимі реального часу. Ця мікросхема споживає лише 6 міліват потужності і може бути використана у легких шоломах доповненої реальності для різних застосувань.
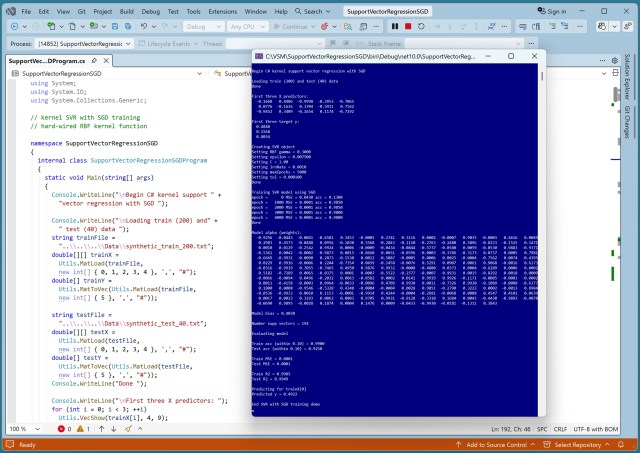
Метод регресії машинного навчання використовується для прогнозування числових значень; метод опорних векторів (SVM) з ядром є поширеною технікою. Автор реалізував SVM з використанням стохастичного градієнтного спуску (SGD) на C#, досягнувши високої точності та видаливши несуттєві дані для покращення продуктивності.

Розвиток штучного інтелекту залежить не лише від обчислювальної потужності, але й від енергії. Компанія Eco Wave Power використовує енергію океанських хвиль для виробництва чистої електроенергії, трансформуючи енергетичну інфраструктуру для потреб ШІ.

Перетворення аерофотознімків на базу знань, яку можна легко шукати, для таких галузей, як страхування та нерухомість. Багатомодальні вбудовані моделі компанії Vexcel та платформа Amazon Nova покращують семантичний пошук геопросторової інформації.

Нові серверні системи NVIDIA з використанням штучного інтелекту працюють із температурою охолоджуючої рідини 45°C, що робить їх більш енергоефективними. Інфраструктура з рідинним охолодженням може дозволити дата-центрам заощадити мільйони та зменшити споживання води на до 100%.
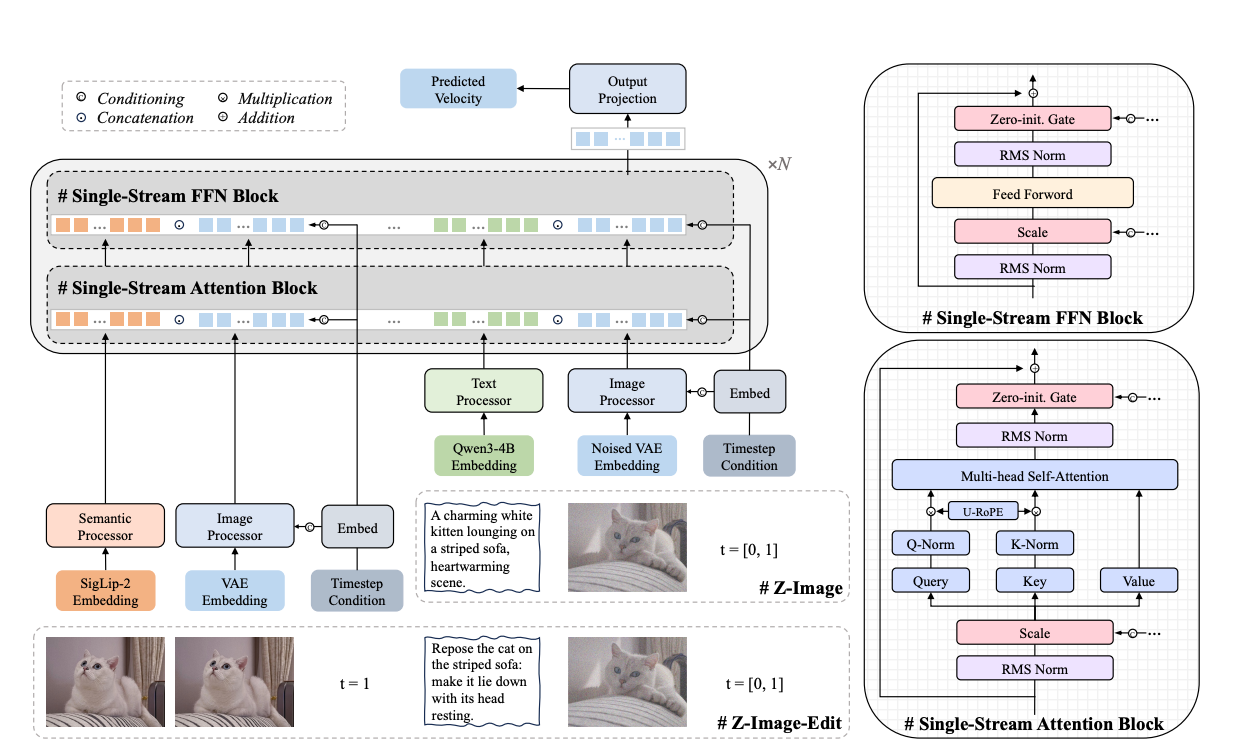
Автоматизуйте створення великих обсягів контенту за допомогою робочих процесів ComfyUI на платформі Amazon SageMaker для задач штучного інтелекту. Прискорюйте рекламні кампанії, збільшуйте конверсії та захищайте репутацію бренду завдяки мультимедійним матеріалам, створеним за допомогою штучного інтелекту.
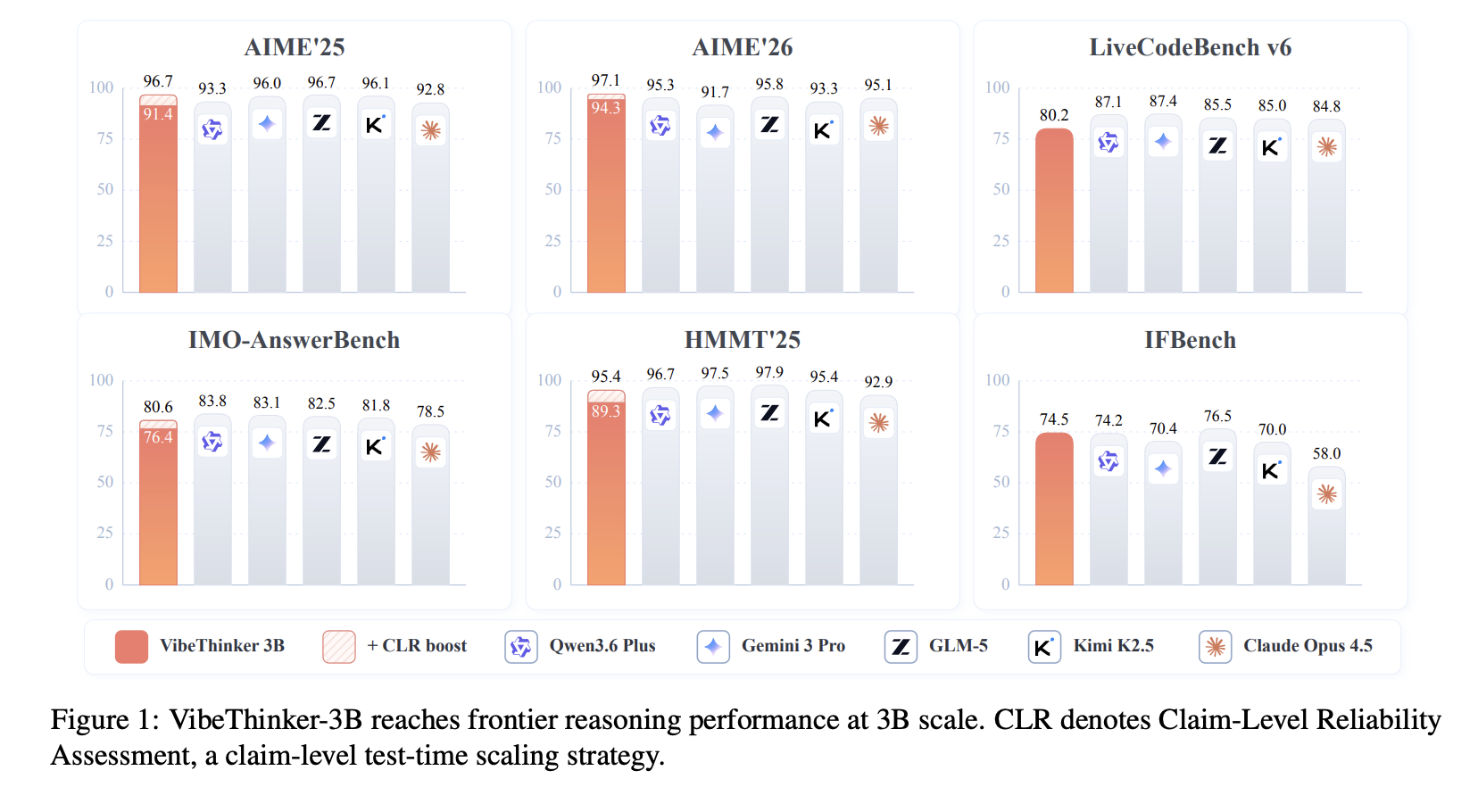
Модель VibeThinker-3B, розроблена компанією Sina Weibo Inc і що має 3 мільярди параметрів, перевершує більші моделі в таких завданнях, як математика та програмування. Завдяки акценту на ефективності та спеціалізованому мисленні, вона забезпечує високу продуктивність у завданнях, які можна перевірити, а також у вирішенні непередбачених задач з програмування.
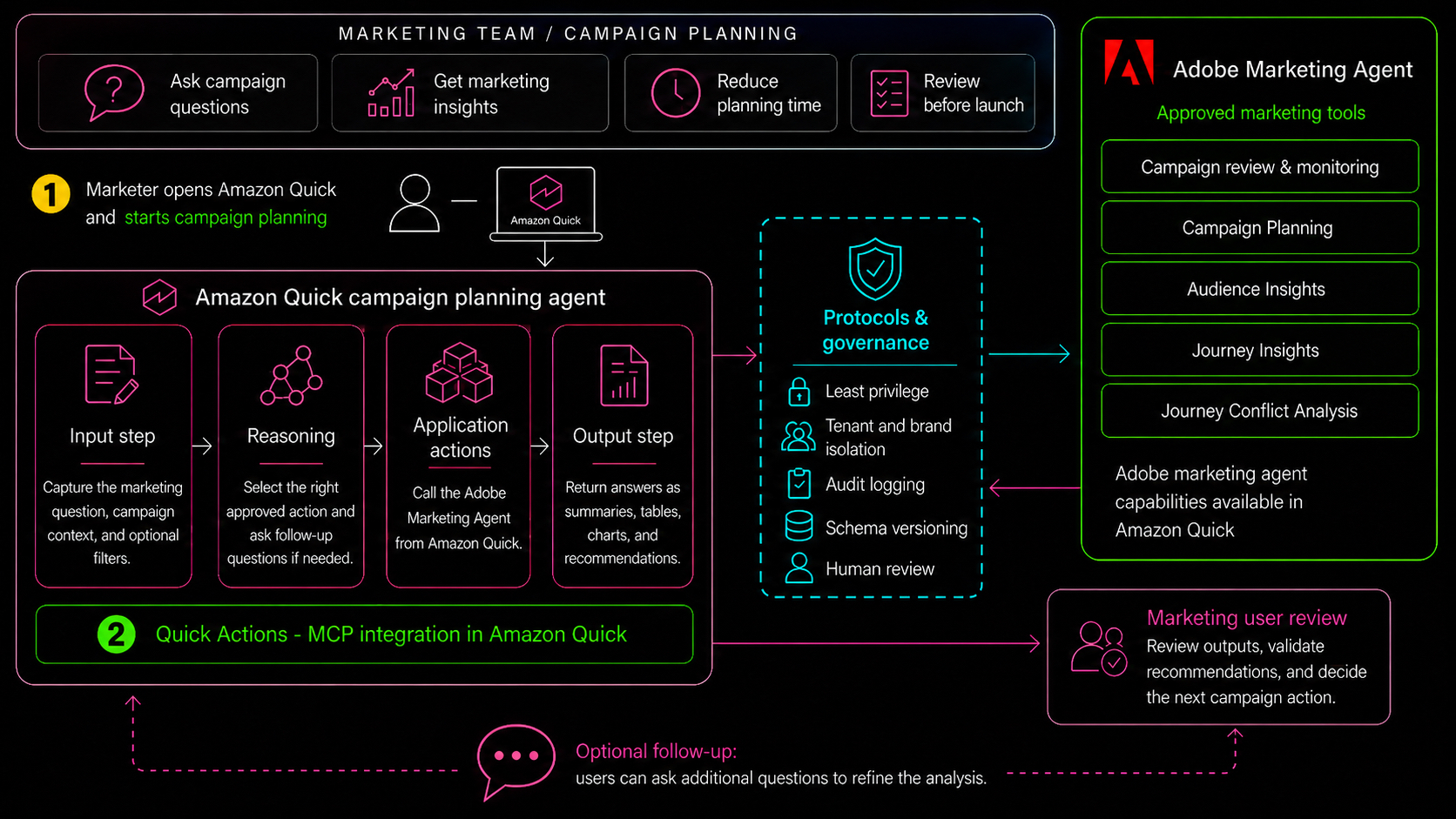
Amazon Quick та Adobe Marketing Agent спрощують аналіз результатів рекламних кампаній для маркетологів. Інтеграція дозволяє здійснювати пошук за допомогою природної мови та надає цінні дані для планування кампаній та розуміння аудиторії. Функції Adobe Marketing Agent охоплюють перегляд кампаній, планування, аналіз аудиторії, вивчення шляхів взаємодії з користувачами та аналіз конфліктів, що пок...
Дослідники з Массачусетського технологічного інституту розробили модель машинного навчання, яка дозволяє точно прогнозувати поведінку металів, що сприяє розвитку нових матеріалів. Цей підхід можна адаптувати для інших матеріалів, відкриваючи можливості для створення нових екологічно чистих сталей та матеріалів для авіакосмічної промисловості.
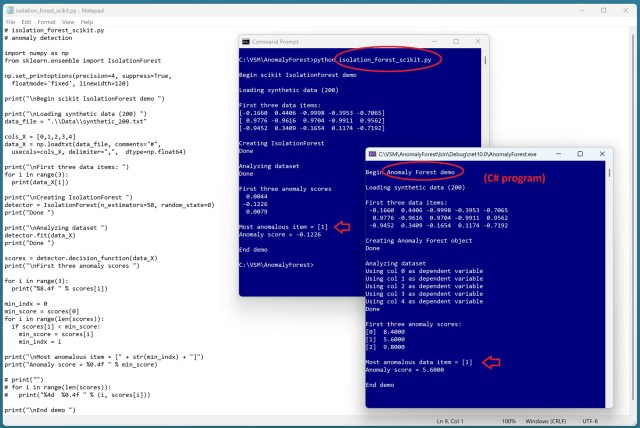
Модуль IsolationForest у бібліотеці scikit-learn виявляє аномалії за допомогою дерев рішень. Алгоритм "Ліс аномалій", реалізований на C#, підтвердив свою точність при роботі з синтетичними даними.
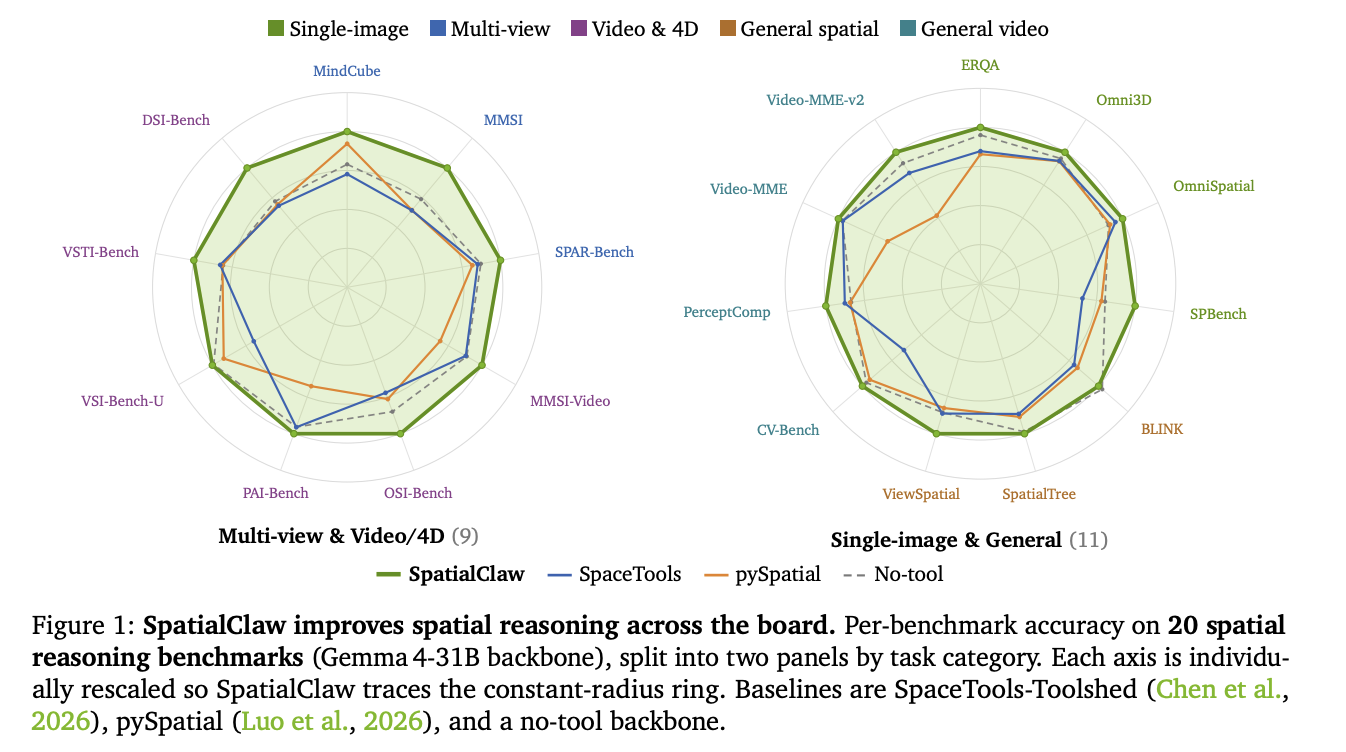
Технологія SpatialClaw, розроблена дослідницькою групою NVIDIA, покращує просторове мислення в моделях, що поєднують обробку зображень та текстової інформації. Вона перевершує систему SpaceTools на 11,2 бали і досягає точності 59,9% у 20 різних тестах.