Компанія Databricks випустила Omnigent — «мета-фреймворк» з відкритим кодом для агентів штучного інтелекту під ліцензією Apache 2.0, що забезпечує безперебійну співпрацю та управління. Omnigent стандартизує інтерфейси, дозволяючи інженерам легко замінювати та координувати роботу декількох агентів, розширюючи можливості компонування та обміну даними.
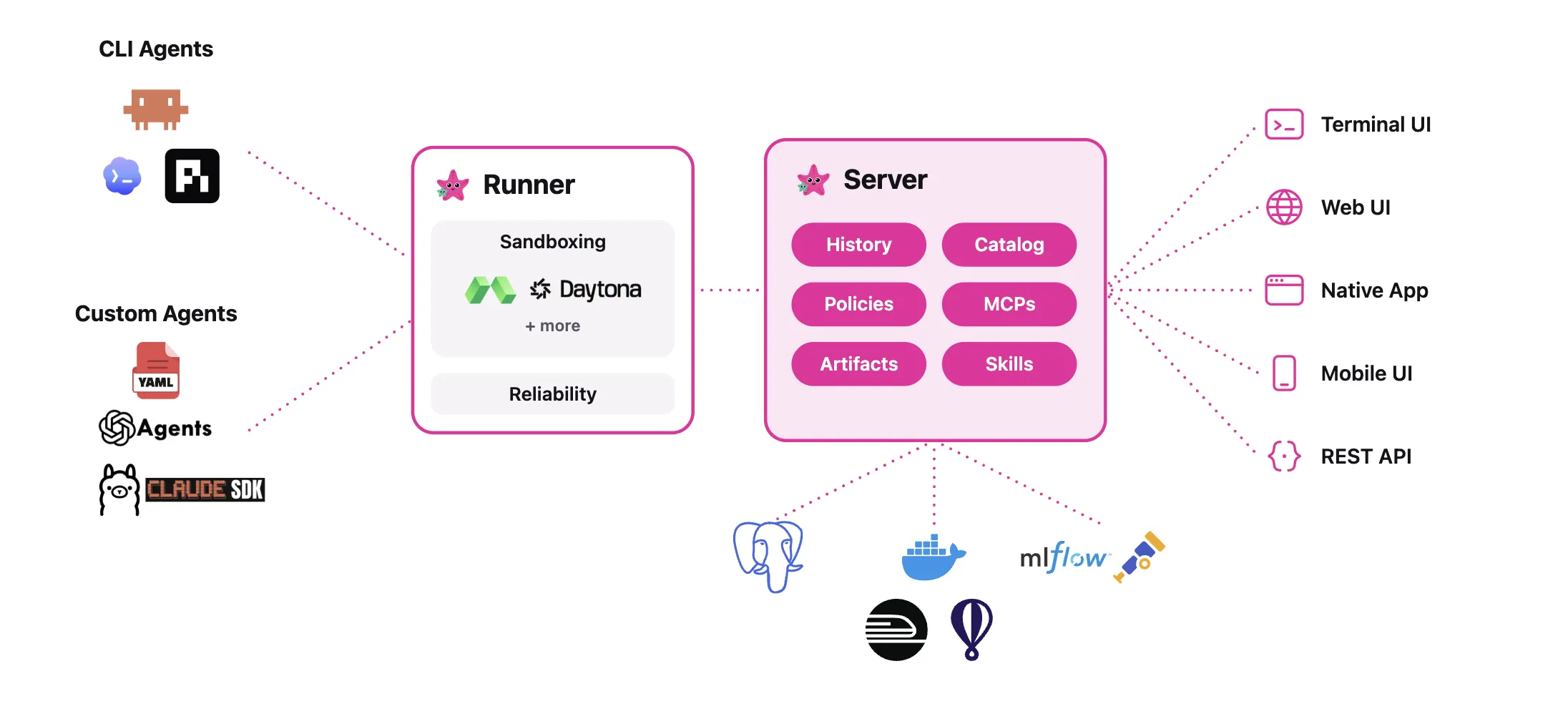
Компанія Rocket Close, що входить до складу Rocket Companies і базується в Детройті, спільно з AWS розробила Supercharger — рішення на базі штучного інтелекту, покликане оптимізувати робочі процеси в сфері оформлення прав власності та підвищити ефективність процедур кредитування й купівлі житла. Supercharger централізує знання, автоматизує завдання, що вимагають значних дослідницьких зусиль, а...
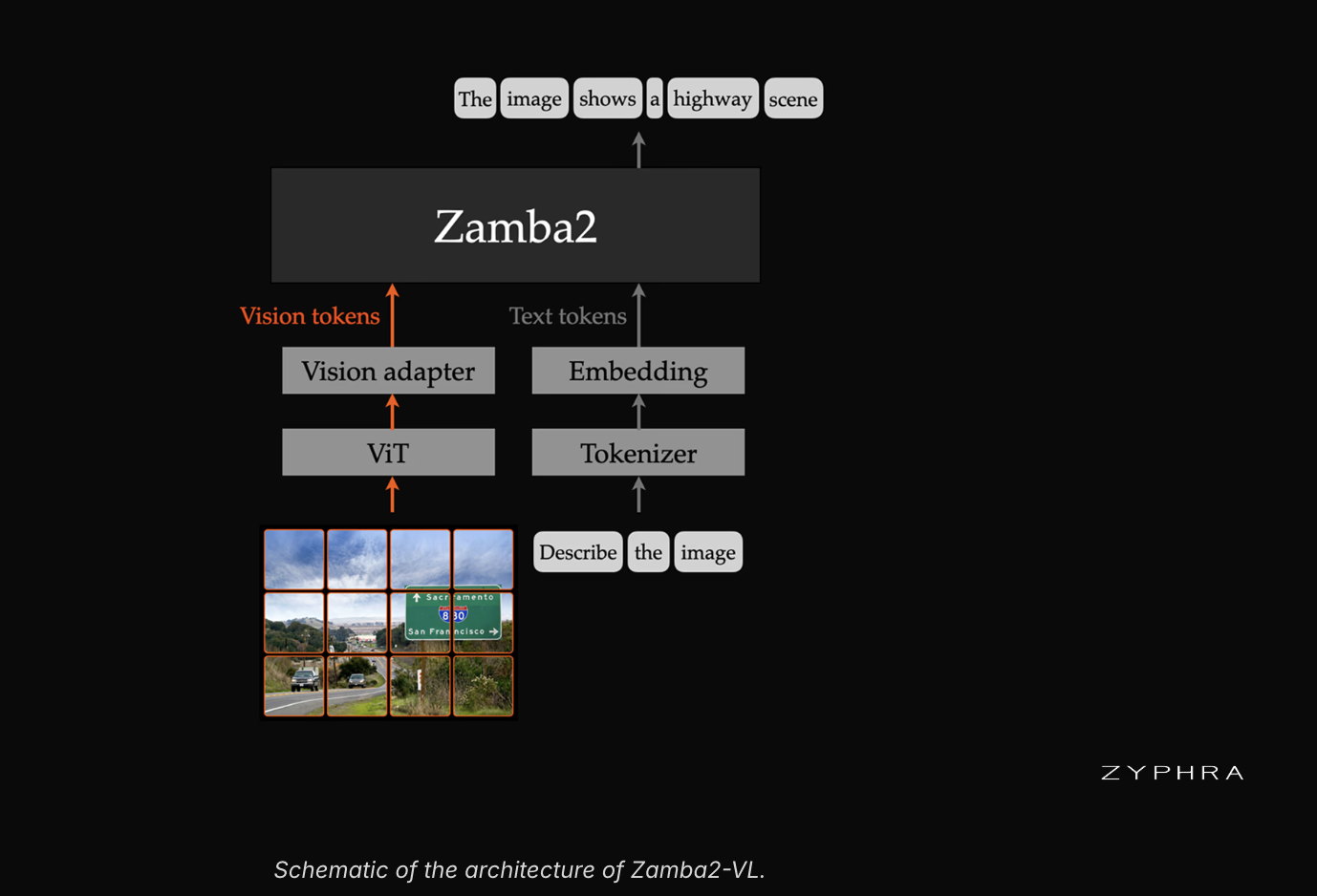
Компанія Zyphra представляє Zamba2-VL — нову серію моделей для обробки зображень та мови, що відрізняється унікальною гібридною архітектурою, яка забезпечує вищу точність та меншу затримку. Базова архітектура Zamba2 поєднує шари простору станів Mamba2 та спільні блоки трансформерів, демонструючи високу продуктивність у різних тестах.
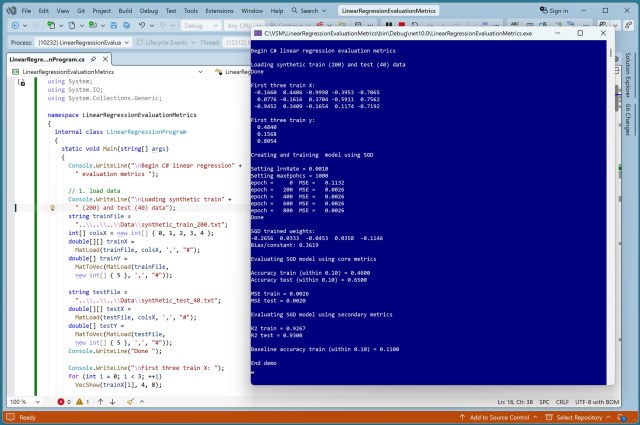
Ключове слово «dynamic» у C# спрощує додавання додаткових показників оцінки до регресійних моделей, підвищуючи гнучкість та ефективність. У демонстрації представлено різноманітні методи оцінки, такі як RMSE, R² та точність базової лінії, що дозволяє більш якісно оцінювати моделі.
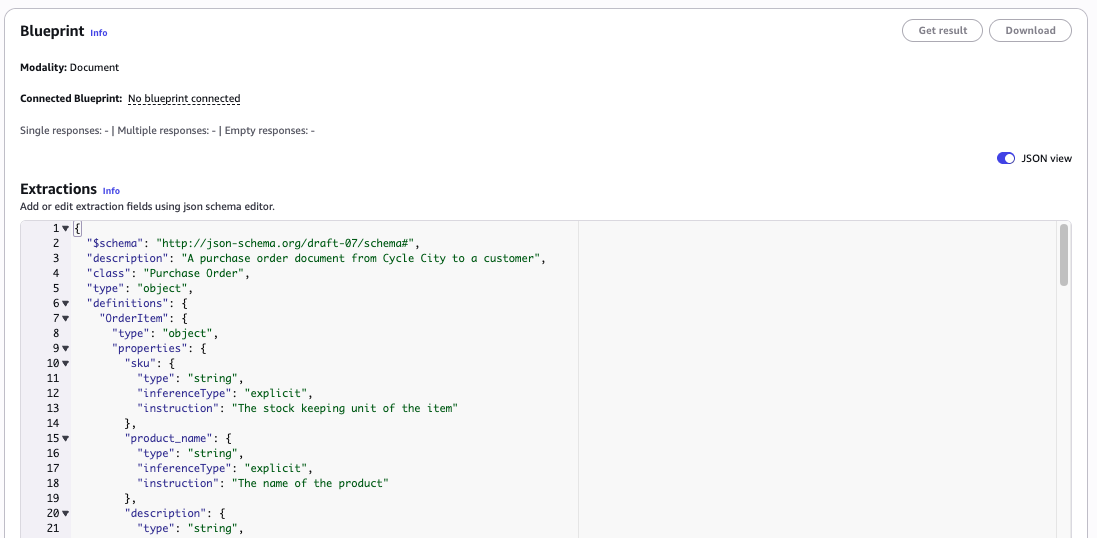
Amazon Bedrock Data Automation (BDA) спрощує вилучення структурованих даних із різноманітних документів за допомогою настроюваних шаблонів. Оптимізація інструкцій у шаблонах підвищує точність без необхідності окремого налаштування моделі, що кардинально змінює підхід до вилучення полів із документів.

AdaBoost. Регресія R² прогнозує окремі числові значення шляхом послідовного вдосконалення регресійних дерев. Демо-програма демонструє точність 82,50 % на навчальних даних і 52,50 % на тестових даних.

Фонд Герца присудив стипендії студентам Массачусетського технологічного інституту (MIT) — Анніці Маршнер, Альвіну К. Менгу, Закарі С. Сігелю та Метью Ванті — надавши їм п’ятирічну фінансову підтримку для проведення новаторських досліджень. Стипендіати отримують автономію та доступ до мережі, що налічує понад 1 300 стипендіатів, що сприяє спільним проривам у галузі науки та технологій.

Літня розпродаж GeForce NOW пропонує знижку до 70 доларів на 12-місячну підписку, що забезпечує миттєвий доступ до високопродуктивних хмарних ігор на будь-якому пристрої. Приємною новиною є те, що до GeForce NOW додається гра Guild Wars 3, що покращить враження від MMORPG для гравців.

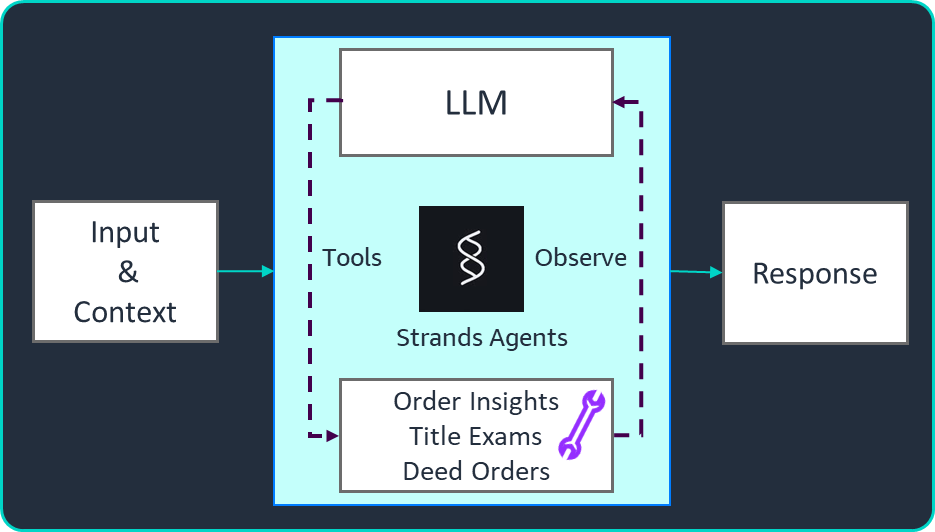
Agent-EvalKit пропонує комплексну інфраструктуру для оцінки агентів штучного інтелекту, що дозволяє відстежувати використання інструментів та достовірність даних. Цей інструмент інтегрується з популярними помічниками з програмування ШІ та надає детальні рекомендації щодо вдосконалення на основі аналізу коду. Для ефективної оцінки необхідно вимірювати якість агента за різними параметрами, причо...

Цзяо Цзіньхуа призначено керівником кафедри міських досліджень та планування Массачусетського технологічного інституту (MIT), яка відома своєю роллю у формуванні глобальних систем мобільності та налагодженні зв’язків між науковими дослідженнями та державною політикою. Співпраця Цзяо з провідними транспортними агентствами по всьому світу та заснування ним Ініціативи з мобільності MIT підкреслюю...
Стаття Л. Л. Терстоуна 1927 року, присвячена моделям випадкової корисності, заклала основи для розуміння людських уподобань. Нещодавні дослідження фахівців Массачусетського технологічного інституту (MIT) відкривають нові перспективи та можливості вдосконалення цих моделей.

Команда Google AI спільно з дослідниками DeepMind презентувала DiffusionGemma — модель для генерації тексту. Вона використовує метод дифузії тексту, що забезпечує в 4 рази швидшу паралельну генерацію на графічних процесорах. Ця модель з 26 мільярдами параметрів (MoE) підтримує понад 140 мов із контекстним вікном у 256 тисяч токенів.
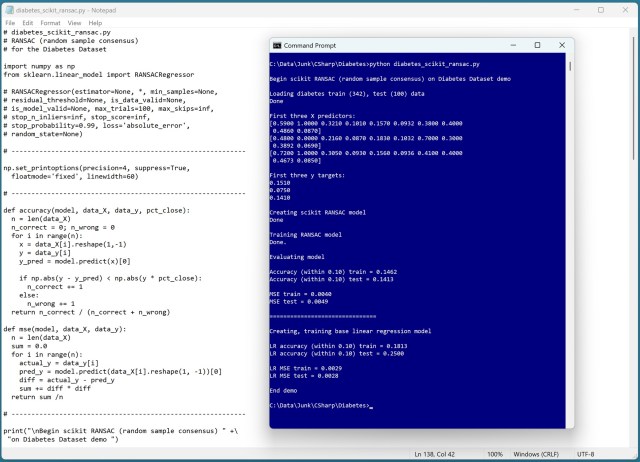
Регресія RANSAC виявляє винятки в навчальних даних для отримання кращих результатів лінійної регресії. Демонстрація на наборі даних про діабет показує, що RANSAC демонструє гірші результати порівняно зі звичайною лінійною регресією.

Компанія Ferveret, заснована Резою Азізіаном і Маттео Буччі з Массачусетського технологічного інституту (MIT), революціонізує систему охолодження центрів обробки даних завдяки своїй безводяній енергоефективній системі. Їхнє рішення Adaptive Phase Cooling підвищує енергоефективність обчислювальних потужностей на 15% і дозволяє центрам обробки даних отримувати на 35% більше токенів від моделей ш...

Роботаксі стають реальністю завдяки безпілотним поїздкам у містах по всьому світу, зокрема завдяки співпраці таких компаній, як Uber та Autobrains у Мюнхені, Foxconn на Тайвані та VinFast у Південно-Східній Азії. Операційна система Halos від NVIDIA кардинально змінює рівень безпеки роботаксі завдяки сертифікованій базі ОС та стандартизованим інтерфейсам для транспортних засобів на базі штучног...