
Уряд Великої Британії виділяє 1 млрд фунтів стерлінгів на розробку квантових комп'ютерів для різних галузей, прагнучи запобігти відтоку фахівців до США в гонці за лідерство в галузі штучного інтелекту. Ліз Кендалл наголошує на важливості утримання квантових фахівців, щоб не поступитися позиціями конкурентам.
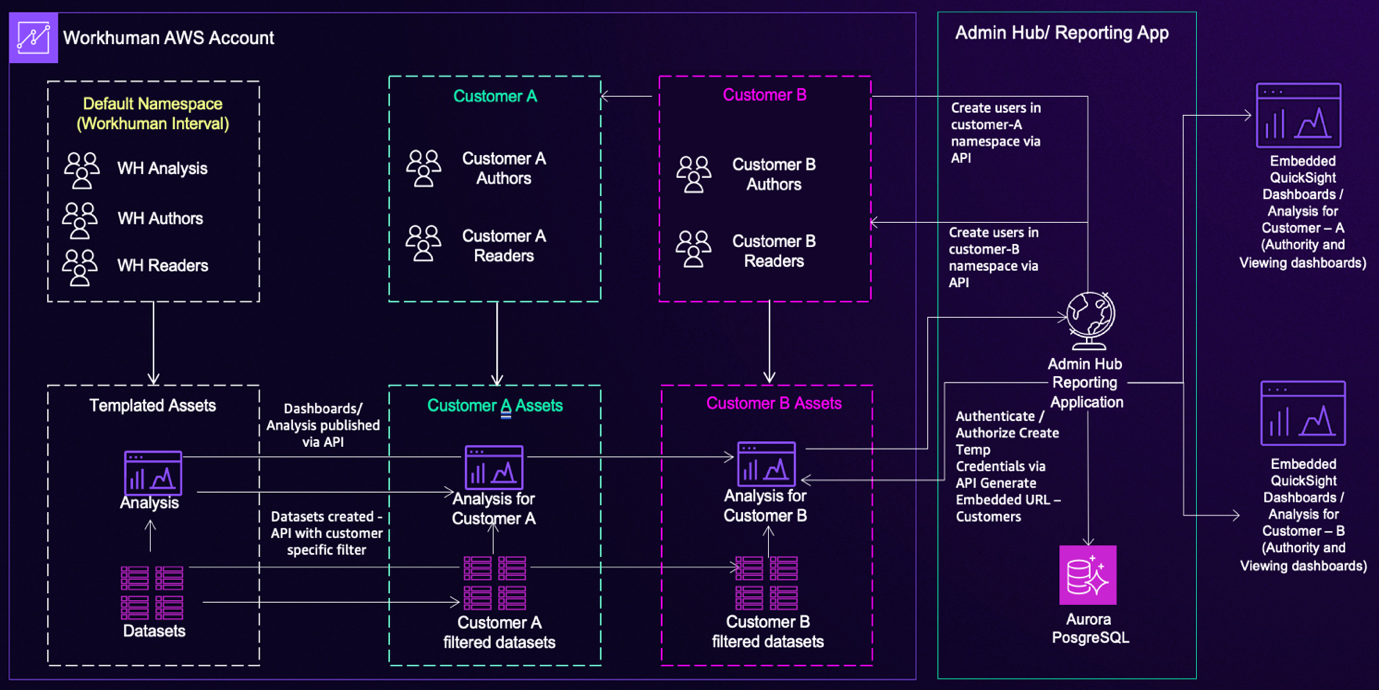
Компанія Workhuman трансформувала процес надання аналітичних даних за допомогою Amazon QuickSight, надавши можливість створювати індивідуальні звіти 7 мільйонам користувачів по всьому світу. Надавши клієнтам можливість самостійно створювати візуалізації, Workhuman підвищила операційну ефективність та рівень задоволеності клієнтів.

Піонер у галузі штучного інтелекту Деміс Хассабіс пройшов шлях від дитинства-шахового вундеркінда до претендента на Нобелівську премію. У 2016 році система AlphaGo від DeepMind перемогла провідного гравця в го Лі Се-дола в історичному поєдинку, продемонструвавши потенціал штучного інтелекту в цій стародавній грі.

Google запускає суперечливу функцію штучного інтелекту «Що радять люди», яка надає медичні поради від аматорів з усього світу, попри критику з боку громадськості. Компанія наголошує на потенціалі штучного інтелекту в поліпшенні стану здоров’я населення у всьому світі завдяки порадам, зібраним за допомогою краудсорсингу.

Компанії AWS та NVIDIA оголосили на конференції NVIDIA GTC 2026 про розширення співпраці у сфері впровадження рішень штучного інтелекту, зокрема про розміщення 1 мільйона графічних процесорів NVIDIA у регіонах AWS. Нові інстанси Amazon EC2 з графічними процесорами NVIDIA RTX PRO 4500 Blackwell Server Edition забезпечують підвищену продуктивність для різних робочих навантажень.

Підлітки подали позов проти компанії xAI Ілона Маска за використання їхніх фотографій у сексуалізованих зображеннях, створених штучним інтелектом, без їхньої згоди, що стало причиною першого в своєму роді судового процесу. Адвокат звинувачує xAI в отриманні прибутку від матеріалів, що містять сцени сексуального насильства над дітьми, незважаючи на усвідомлення небезпеки.
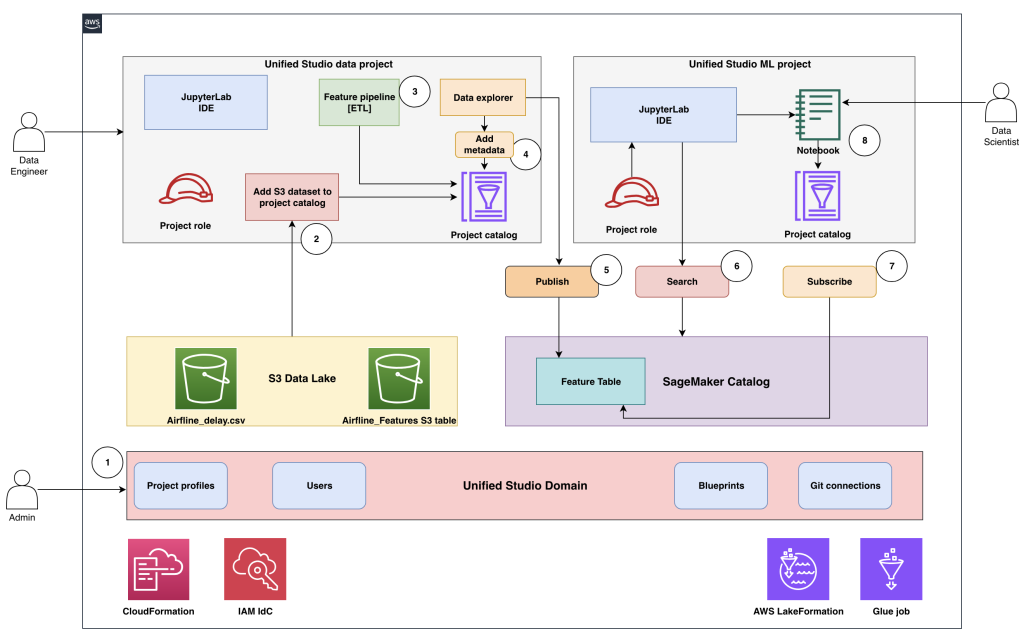
Amazon SageMaker пропонує SageMaker Unified Studio та SageMaker Catalog для вирішення завдань, пов’язаних зі створенням та управлінням моделями машинного навчання у великих масштабах. Завдяки впровадженню автономного сховища моделей організації можуть забезпечити послідовне управління моделями, прискорити експерименти з машинним навчанням та зменшити операційні витрати.
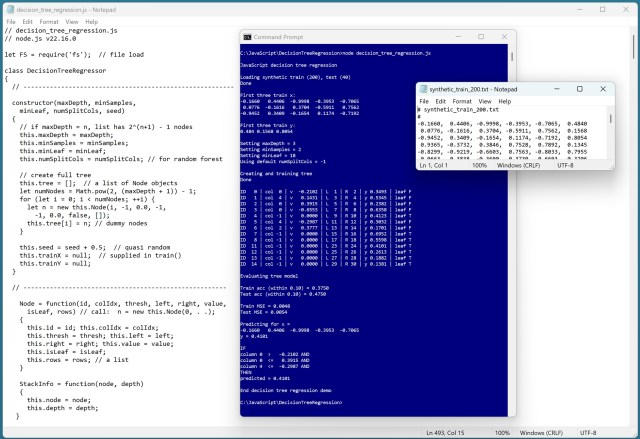
Регресія на основі дерева рішень дозволяє прогнозувати числові значення за допомогою правил «якщо-то». Демонстрація реалізації на JavaScript показує високу точність прогнозування синтетичних даних.
У другій частині серії публікацій Центру інновацій у галузі генеративної штучного інтелекту AWS висвітлюються ключові риси, необхідні організаціям для досягнення успіху у впровадженні агентного ШІ. Керівники повинні чітко визначити ролі, обов’язки та показники ефективності, щоб гарантувати безпосередній зв’язок агентного ШІ з бізнес-результатами.

Фарбод Мехр створює штучну співачку Наву, пісні якої знаходять відгук у серцях іранців на тлі заворушень 2026 року. Тексти пісень Нави натхненні творчістю поета Арефа Газвіні та дарують надію в умовах політичних заворушень та іноземних атак.

Війна з використанням штучного інтелекту дозволяє застосовувати високоточне озброєння, таке як ізраїльська «операція «Туман», що призводить до летальних наслідків, що підкреслює нагальну необхідність введення відповідного регулювання. З розвитком технологій штучного інтелекту у військовій сфері триває небезпечна тенденція до насильства, яке виправдовується сліпотою.

Прихильники пропонують перейти на чотириденний робочий тиждень, щоб поліпшити баланс між роботою та особистим життям і підвищити продуктивність за рахунок скорочення часу на наради та оптимізації робочих процесів. Незважаючи на потенційні переваги, ця модель поки що не набула широкого поширення.

Звільнення в компанії Atlassian викликали дискусію щодо робочих місць у сфері штучного інтелекту. Інструмент штучного інтелекту Claude від компанії Anthropic значно підвищує продуктивність розробників.

Доктор Нафіса Баба-Ахмед закликає університети переглянути підходи до навчання студентів на тлі занепокоєння щодо штучного інтелекту. Штучний інтелект лише сприяє поширенню вже існуючих академічних «скорочень», а не створює їх.

Генеральний директор Palantir прогнозує, що штучний інтелект вплине на виборчий ландшафт, особливо на жінок-виборців. Це попередження чи рекламний хід?