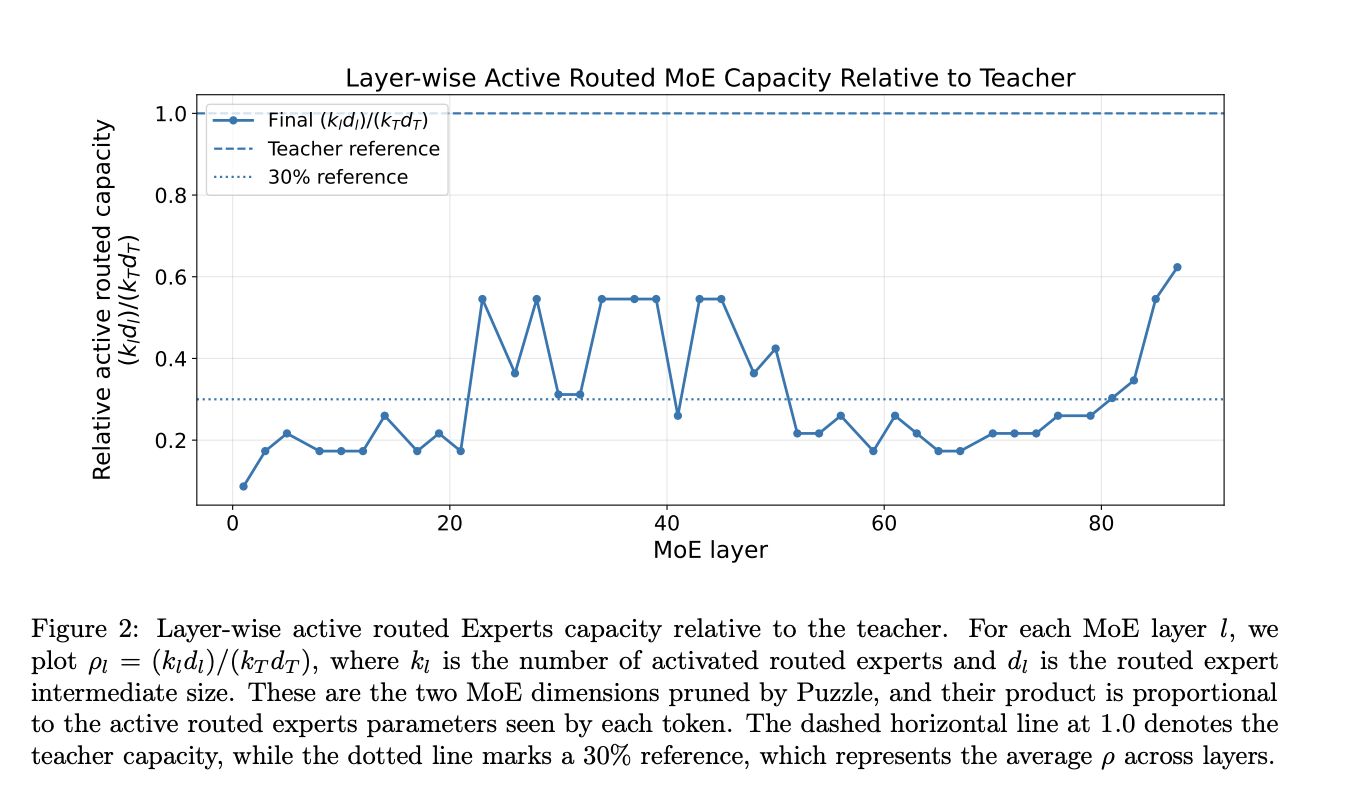
Модель NVIDIA AI team під назвою Nemotron-Labs-3-Puzzle-75B-A9B є оптимізованою версією Nemotron-3-Super, яка збільшує продуктивність до 2.14 рази на одному пристрої H100. Модель зберігає оригінальну структуру, досягаючи значного підвищення продуктивності завдяки селективному зменшенню обсягу пам'яті.
Інструменти MCP працюють неефективно через поганий дизайн, що призводить до надмірної об'ємності та плутанини в великих мовних моделях. Практична інженерія контексту є ключем до покращення роботи інструментів і балансування між об'ємністю та плутаниною.

Сервіс GeForce NOW розширюється завдяки новому серверу RTX 5080 у Торонто, що покращує продуктивність хмарних ігор. Оновлення "Neverness to Everness" пропонує нову механіку гри, персонажів, костюми та революційний мотоцикл.
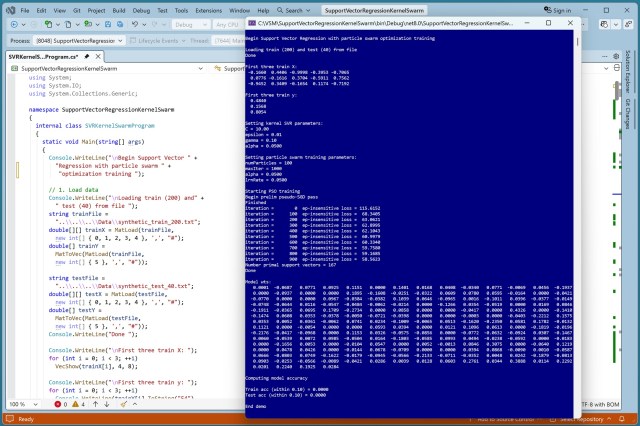
Спроба навчання моделі Support Vector Regression (SVR) з використанням алгоритму Particle Swarm Optimization (PSO) дала лише 35% точності, порівняно з 95%, досягнутими при використанні стандартних методів. Теоретичні переваги PSO не проявляються в практичних застосуваннях для навчання моделей SVR.
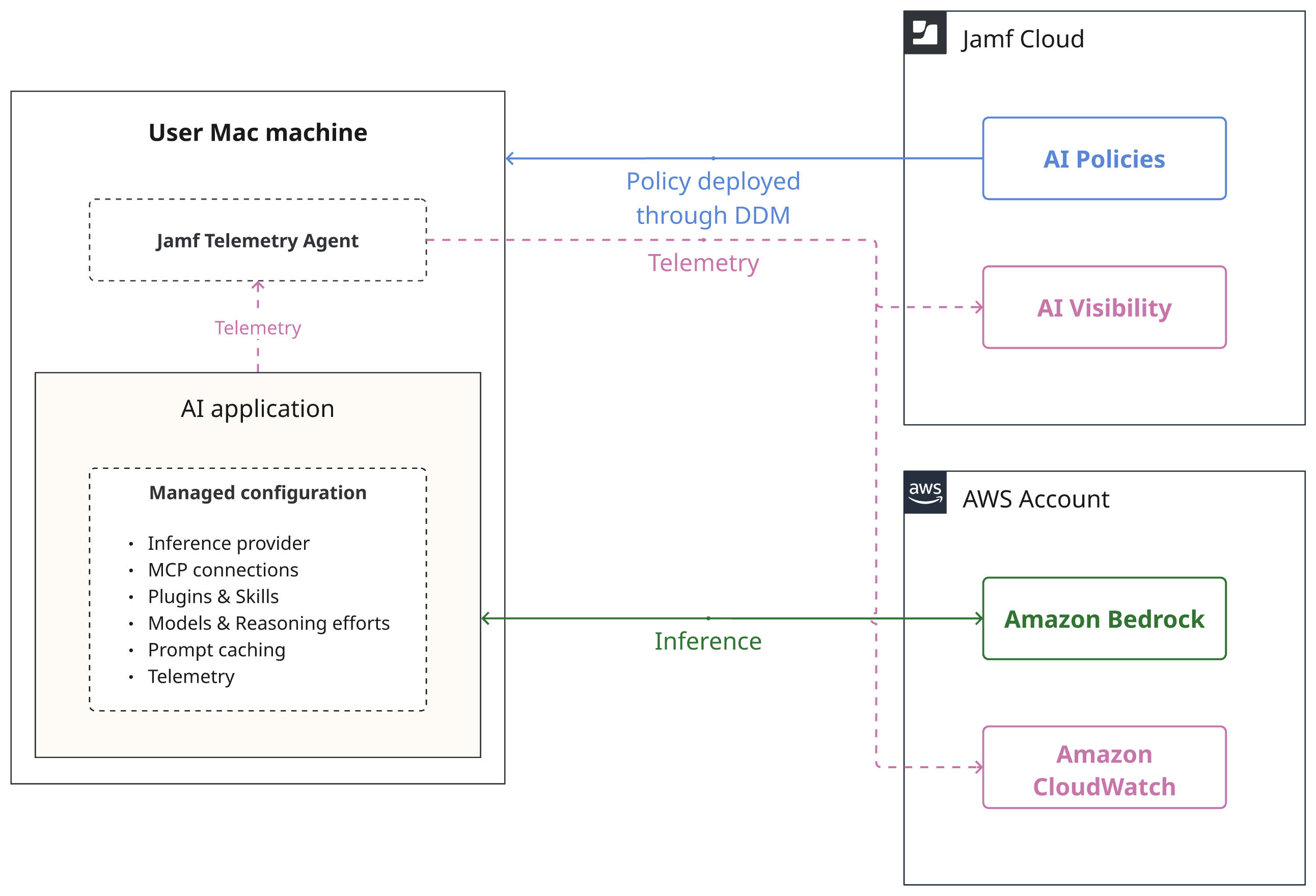
Система управління штучним інтелектом від Jamf спрощує керування додатками на базі ШІ, такими як Claude Code, на пристроях Mac з підтримкою Amazon Bedrock, забезпечуючи безпечне та ефективне розгортання. Користувачі можуть легко отримувати доступ до схвалених програм без ручного налаштування, що підвищує продуктивність і покращує систему управління в усій організації.
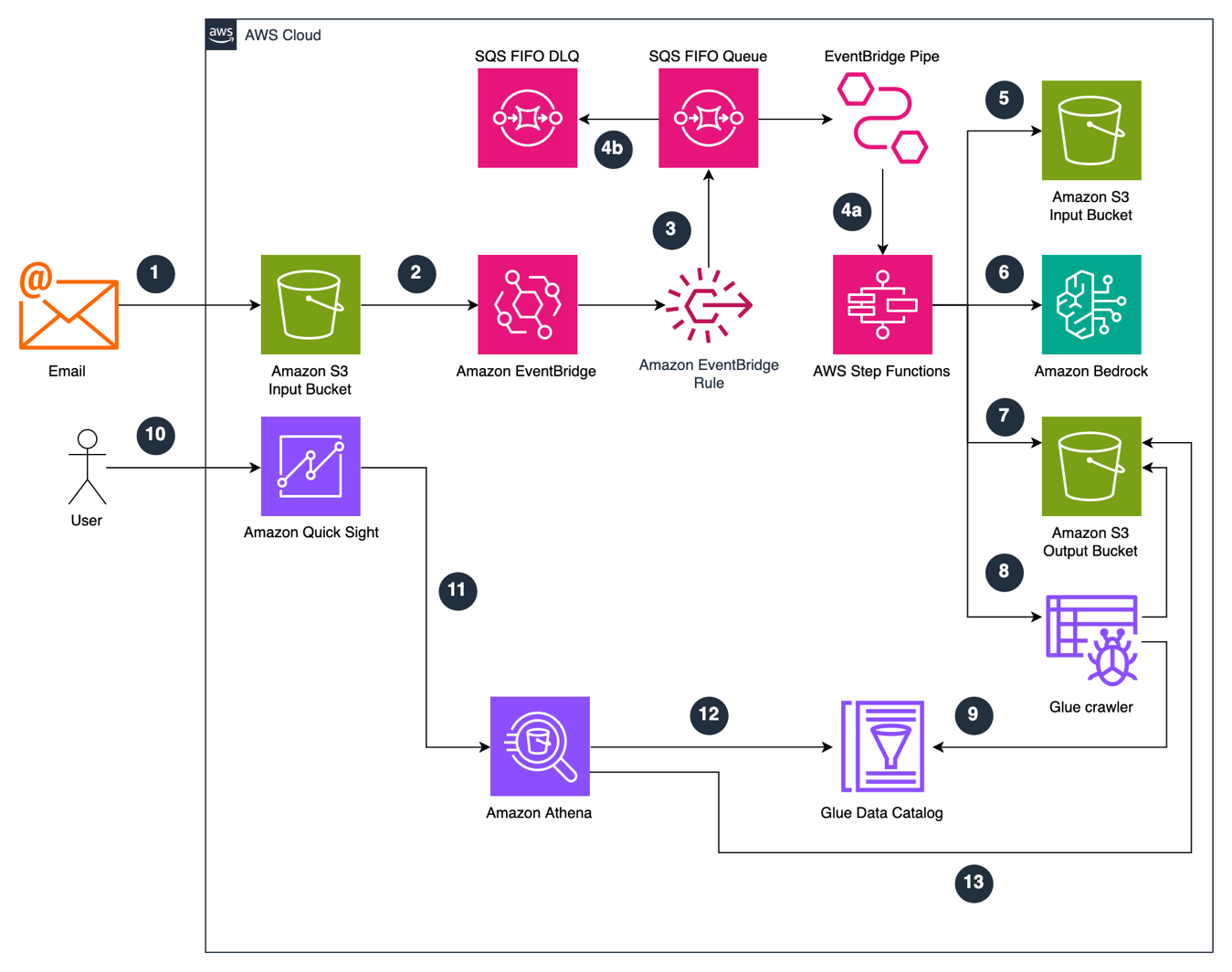
Система управління електронною поштою на основі штучного інтелекту трансформує комунікації в державному секторі, автоматизуючи класифікацію та маршрутизацію повідомлень відповідно до терміновості та відповідності департаментам. Рішення генеративного ШІ, що працює на платформі Amazon Bedrock, оптимізує обробку електронної пошти, покращує швидкість реагування та підвищує якість обслуговування гро...
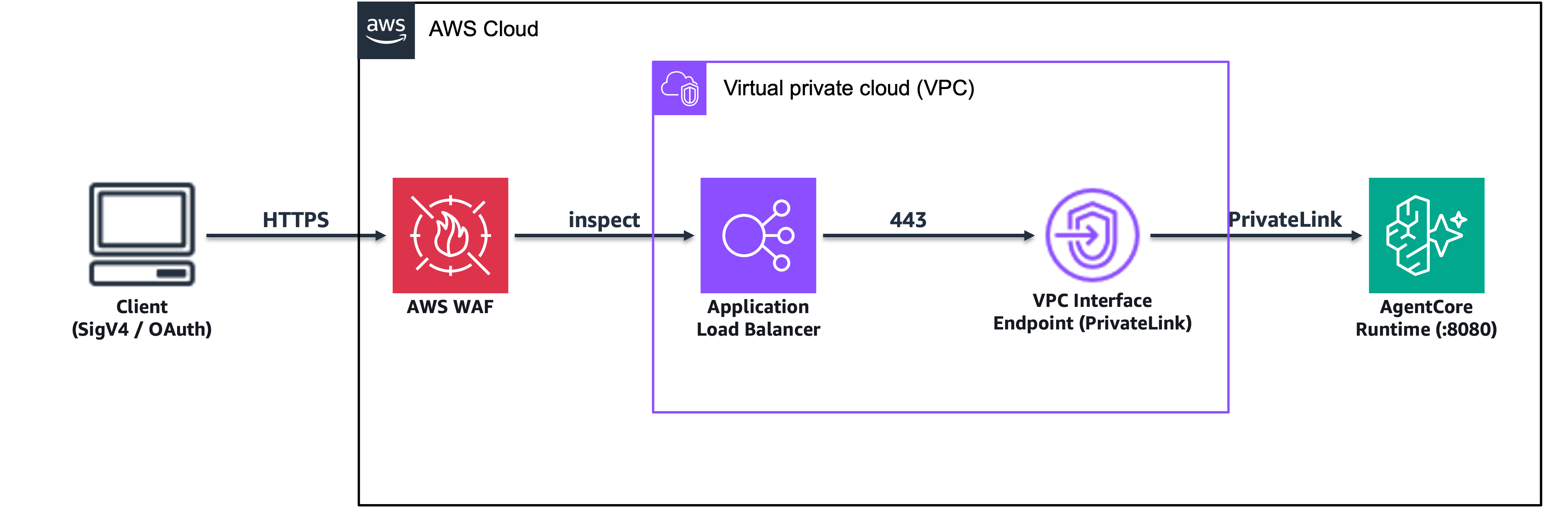
Розгортайте генеративні AI-агенти з використанням Amazon Bedrock AgentCore як виробничі API-інтерфейси, інтегруючи AWS WAF для забезпечення безпеки веб-додатків. Дві архітектурні моделі вирішують проблеми, пов'язані з перевірками працездатності ALB та аутентифікацією, забезпечуючи безперебійний потік трафіку до AgentCore.
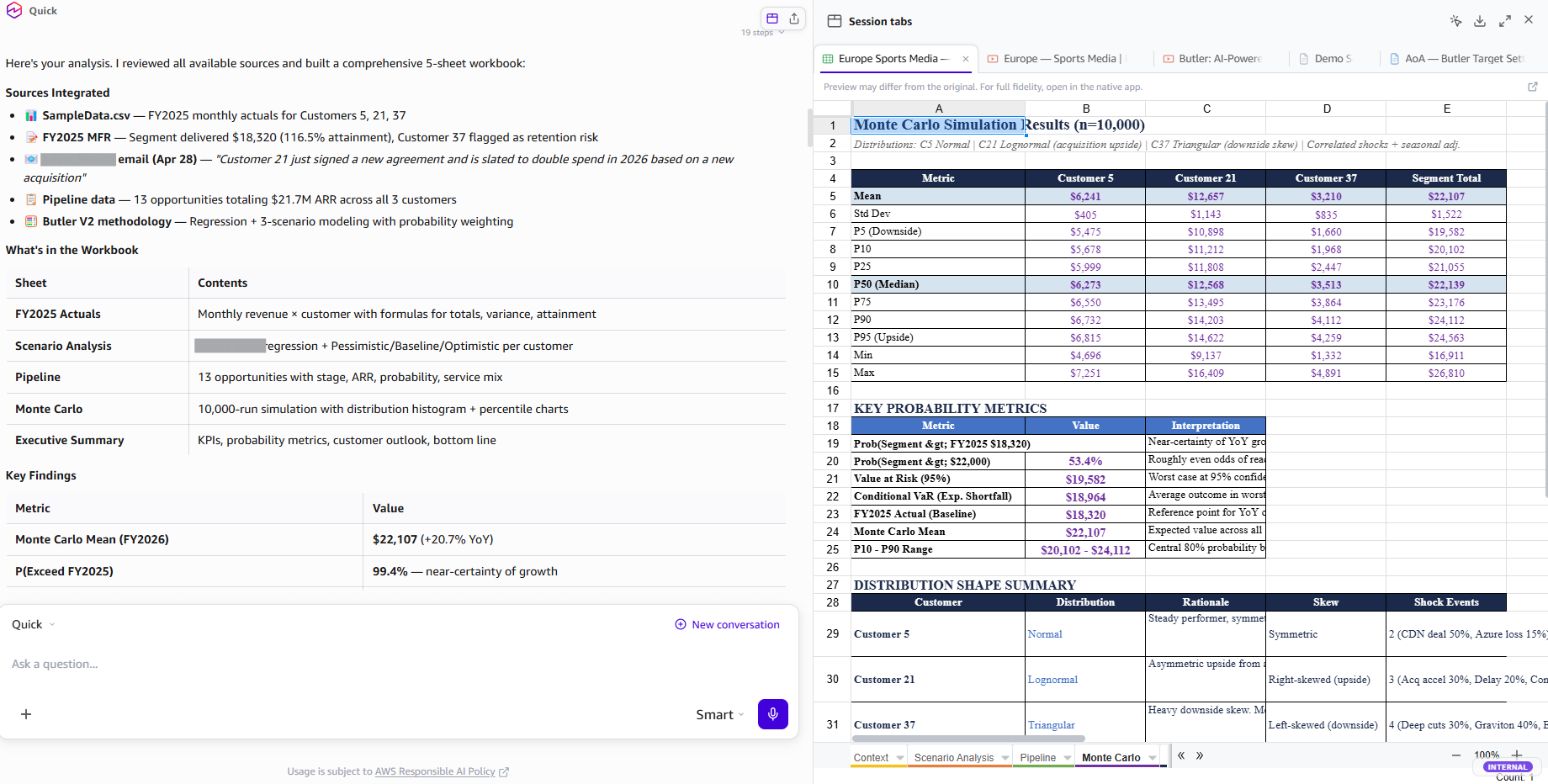
Команда AWS Finance оптимізувала трудомісткі процеси за допомогою Amazon Quick, AI-асистента, який спрощує аналіз даних за допомогою обробки природної мови. Використовуючи чат-ботів і робочі процеси в Quick, команда покращила моделювання сценаріїв та аналіз ризиків, охопивши весь портфель клієнтів з більшою деталізацією, витрачаючи лише 10 хвилин на кожного клієнта.
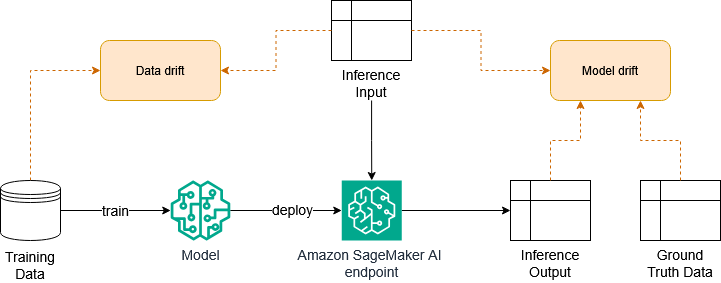
Моделі машинного навчання можуть втрачати свою ефективність після тренування через зміни в навколишньому середовищі. Моніторинг моделей на предмет змін у даних та моделях може запобігти проблемам з точністю, використовуючи такі інструменти, як бібліотека Evidently для Python разом із Amazon SageMaker AI.

Вартість штучного інтелекту стрімко падає, можливості класу GPT-4 тепер коштують менше 1 долара. Незабаром ми побачимо майже безкоштовний штучний інтелект для повсякденних завдань. Це відкриває нові виклики та можливості для систем обробки даних з практично нульовою вартістю обчислень.
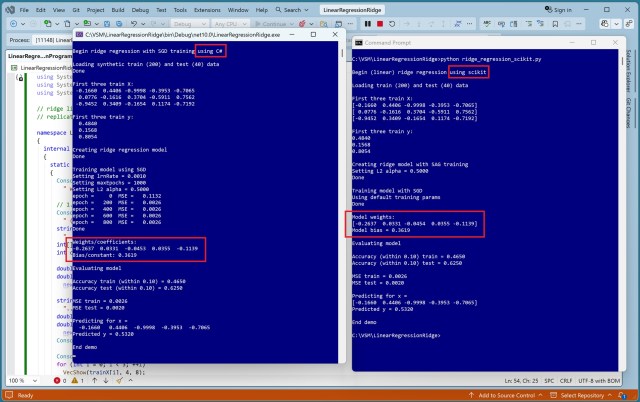
Регресія Ріджа використовує регуляризацію L2 для запобігання перенавчанню шляхом штрафування квадратів вагових коефіцієнтів моделі. Деталі реалізації відрізняються між бібліотекою scikit-learn та демонстраційними прикладами на C#, незважаючи на те, що вони дають однакові результати.

Чат-боти зі штучним інтелектом, такі як ChatGPT та Claude, зараз використовуються для таких завдань, як програмування та розробка додатків. Кандидат у льотчики Повітряних сил США, Джошуа Лінч, створив військовий додаток, використовуючи чат-боти зі штучним інтелектом, не маючи попереднього досвіду програмування.

Джессі Талер призначено директором лабораторії ядерних наук Массачусетського технологічного інституту, де він запроваджуватиме методи штучного інтелекту та машинного навчання в фундаментальних дослідженнях фізики. Лідерство Талера в IAIFI та його акцент на відкриттях, заснованих на штучному інтелекті, мають сприяти новому етапу наукових проривів у лабораторії LNS.
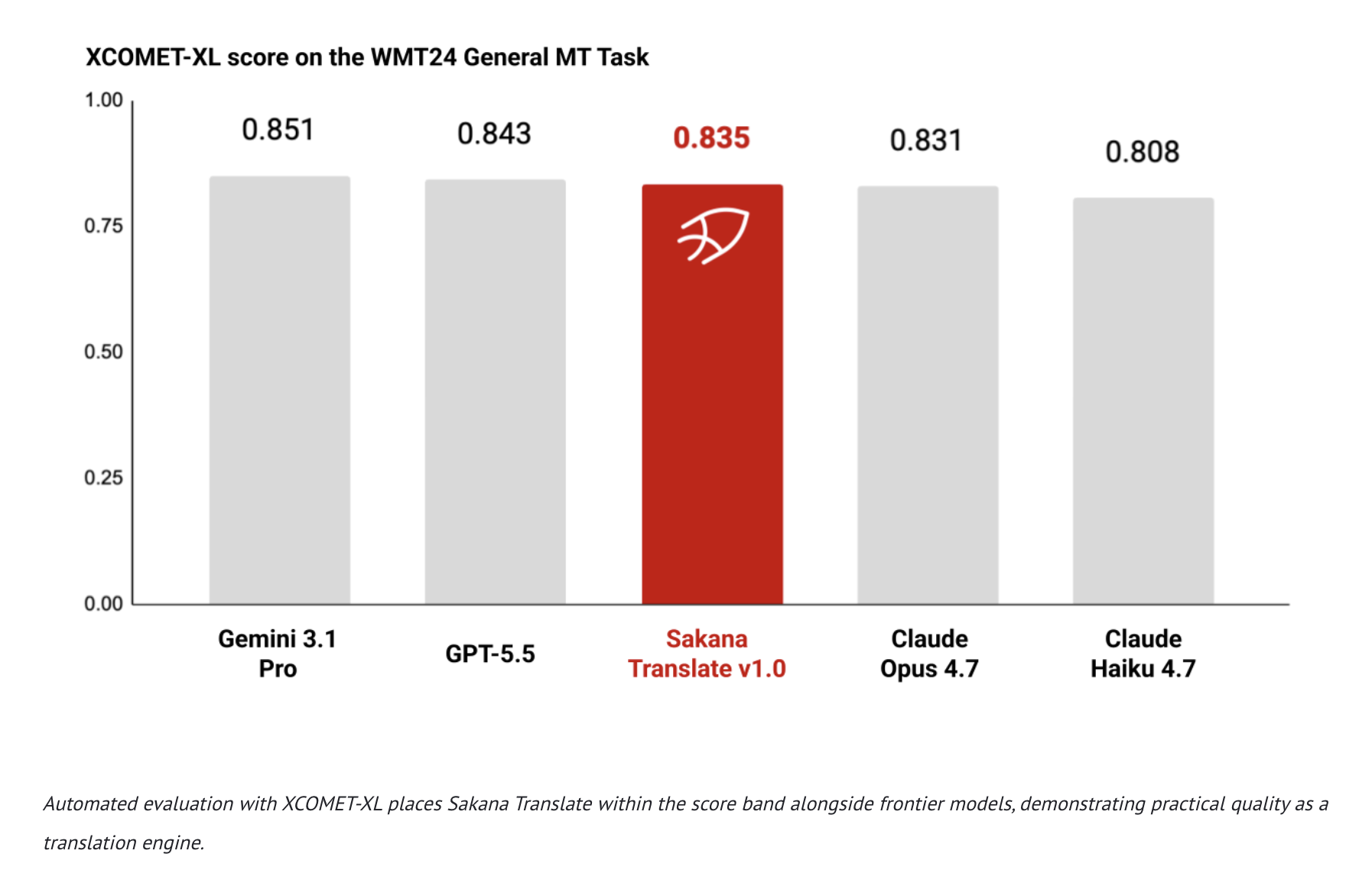
Компанія Sakana AI представляє Sakana Translate, який використовує двигун Namazu для глибокого перекладу між японською, англійською та китайською мовами. Він створений для збереження контексту та культурних особливостей, які часто не враховуються загальними інструментами перекладу.
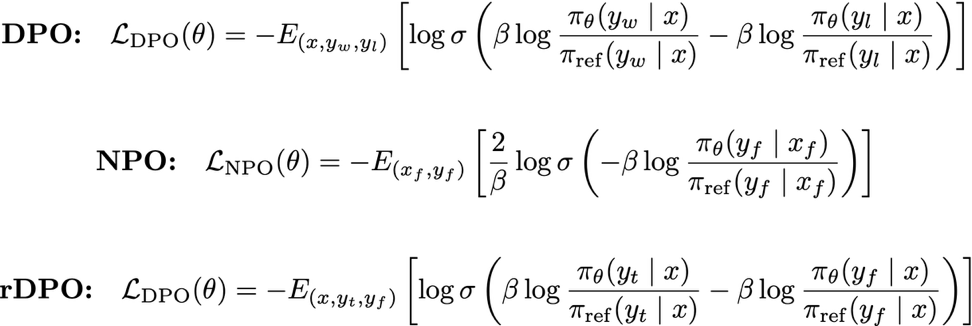
Організації стикаються з проблемами, пов'язаними з тим, що механізми захисту моделей блокують необхідний контент. Технологія rDPO від Amazon Nova зменшує надмірне блокування контенту, зберігаючи при цьому якість моделі, що дозволяє налаштовувати параметри модерації контенту.