Anthropic’s Cowork marks a major shift from chat-based AI to autonomous digital coworkers that can plan and execute real work directly on your computer. By giving the controlled access to local files, Cowork becomes a practical collaborator for reports, analysis, and file management.
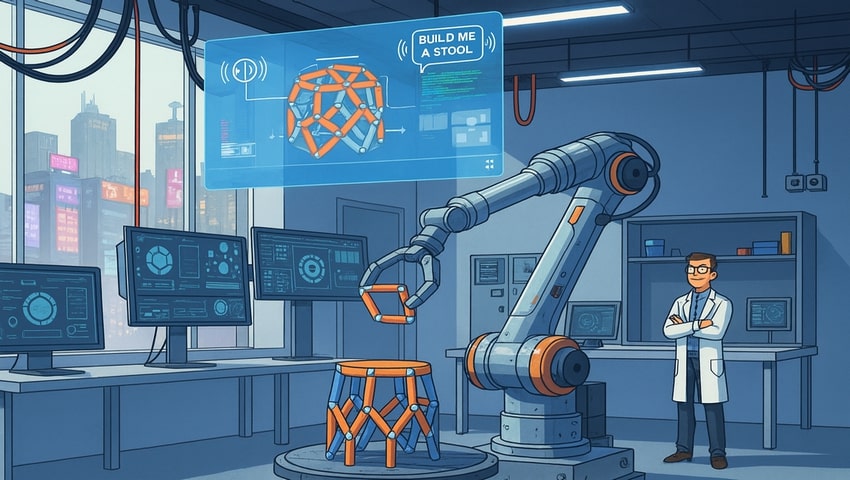
The Speech-to-Reality system transforms spoken commands into physical objects using a combination of natural language processing, 3D generative AI, and robotic assembly. The system enables users to request items like chairs, stools, or shelves and have them assembled by a robotic arm in as little as five minutes.

The most advanced AI models from tech giants like OpenAI and DeepSeek are generating false information at unprecedented rates – and no one knows exactly why. Due to this surge in AI “hallucinations”, the reliability of AI across critical fields is being called into question.

Microsoft’s Phi-4 family is a new generation of compact language models built for complex tasks like math, coding, and planning – often outperforming larger systems. Trained with advanced techniques and curated data, they offer strong reasoning while staying efficient for low-latency use.

GPT-4.5, OpenAI's most advanced AI yet, features improved natural language understanding, enhanced emotional intelligence, and more intuitive conversations. It excels in writing, brainstorming, and problem-solving while minimizing AI hallucinations for more reliable results.
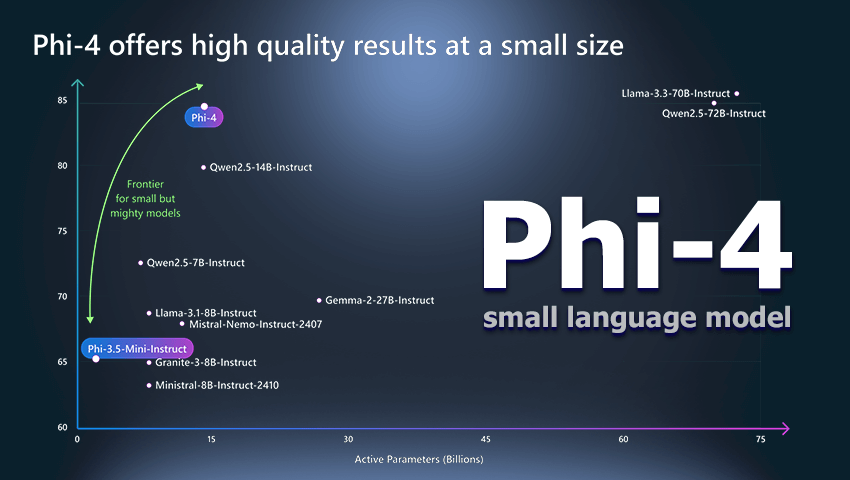
Microsoft has launched the Phi-4 model with open weights under the MIT license, offering researchers and developers unprecedented flexibility. With 14 billion parameters, Phi-4 outperforms its counterparts in solving mathematical problems and multitasking, ensuring efficient work with limited resources.

Alibaba's new AI model, QwQ-32B-Preview, challenges ChatGPT with its impressive math and logic skills, outperforming competitors on key benchmarks. Released under an open license, it offers advanced reasoning capabilities but still struggles with tasks requiring strong common-sense understanding.

Anthropic has introduced Claude 3.5 Sonnet, a new AI model capable of controlling a computer similarly to a human. The model uses screenshots of the desktop to navigate applications and perform tasks such as clicking, typing, and gathering information.

Stable Diffusion 3.5, the latest release from Stability AI, introduces three powerful model variants that deliver enhanced image quality, speed, and accessibility for consumer hardware. The models are free for non-commercial use, and integrate advanced safety features to prevent misuse.

Meta has unveiled Movie Gen, an AI-powered tool that creates high-definition videos with synchronized sound from simple text prompts. The model provides advanced video creation and editing features, offering users enhanced control over content generation.

With price cuts, increased rate limits, and faster output, new Gemini models by Google make advanced AI more accessible for developers worldwide. They boost speed, reduce costs, and enhance performance across a wide range of text, code, and multimodal tasks.

OpenAI o1 is designed to excel in complex reasoning tasks across science, coding, and mathematics. The new model aims to improve accuracy by mimicking human-like reasoning and address safety concerns, ensuring more reliable and responsible AI usage.

The latest text-to-image model from Ideogram AI introduces significant advancements that could challenge the dominance of established players like MidJourney and Leonardo AI. New features are already available, including multiple distinct styles, enhanced realism, and advanced prompting tools.

Gen-3 Alpha – new AI model introduces powerful tools for generating high-quality videos, offering creatives unprecedented control and realism. With its advanced features and superior quality, the model pushes the boundaries of AI-driven content creation, outpacing competitors.

During the Spring Update event OpenAI’s presented GPT-4о – the unique omnimodel that integrates text, audio and image processing, allowing it to work faster and more efficiently than ever before.

SenseTime Group's latest AI model, SenseNova 5.0, has sparked a surge in market interest with its impressive advancements, including enhanced knowledge processing, mathematical reasoning, and linguistic abilities.

Llama 3, Meta AI's latest advancement, boasts unmatched language understanding, enhancing its capacity for complex tasks. With expanded vocabulary and advanced safety features, the model ensures improved performance and versatility.

Google’s DeepMind developed a new method for long-form factuality in large language models, – Search-Augmented Factuality Evaluator (SAFE). The AI fact-checking tool has demonstrated impressive accuracy rates, outperforming human fact-checkers.

Stability AI presented the latest advancement in image generative AI models – Stable Diffusion 3. Its expanded parameter range and diffusion transformer architecture ensure smooth generation of complex, high-quality images and accurate text-to-visual translation.

OpenAI's latest creation Sora crafts captivating videos, offering unparalleled realism of visual compositions. Leveraging a fusion of language understanding and video generation the model can interpret text prompts, accommodate various input modalities, and simulate dynamic camera motion.

Drawing inspiration from its predecessor Gemini, Gemma is focused on openness and accessibility, offering versatile models suitable for various devices and frameworks. The model marks a significant step towards democratizing AI while emphasizing its responsible development and transparency.

A groundbreaking NLP model Gemini AI is set to surpass existing benchmarks. With its multimodal prowess, scalability across various domains, and integration potential within Google's ecosystem, Gemini AI represents a significant leap in AI technology.

A team at Stanford has developed Sophia, a new approach that optimizes pretraining of LLMs. Using the two key techniques, it could help researchers to train LLMs in half the time, thus reducing costs and making it affordable for small organizations and academic groups.
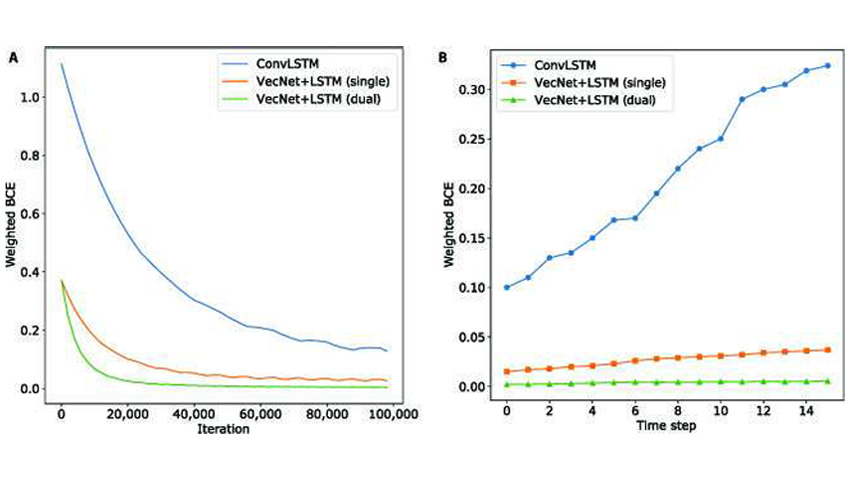
Researchers developed a new approach to motion modeling using relative position change. They evaluated the ability of deep neural networks architectures to model motion using motion recognition and prediction tasks.

Researchers designed a new AI algorithm that is designed to visualize data clusters and other macroscopic features in a way that they are as distinct, easy to observe and human-understandable as possible.

Scholars has developed DetectGPT that can distinguish AI-generated text from human-written text 95% of the time for popular open source LLMs.

Researchers have recently created a new neuromorphic computing system supporting deep belief neural networks (DBNs) - a generative and graphical class of deep learning models.

A team of scientists has developed a machine learning solution to forecast amine emissions from carbon-capture plants using experimental data from a stress test performed at an actual plant in Germany.
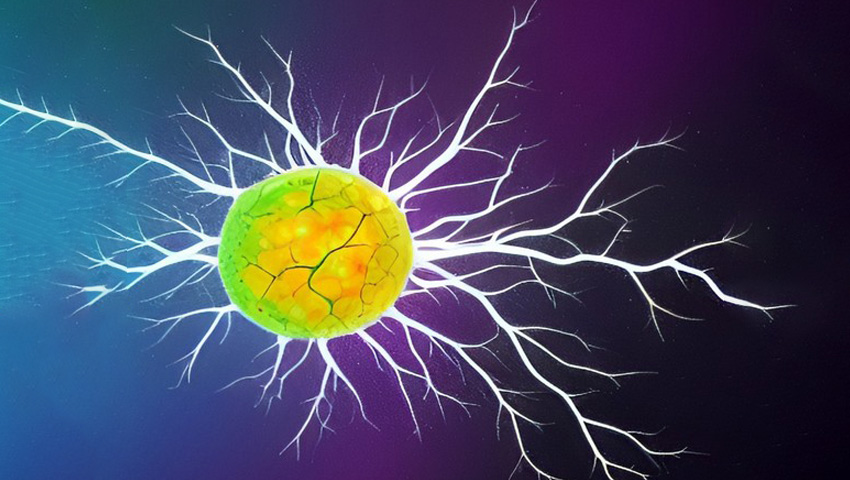
Scientists have developed the first bio-realistic artificial neuron that can effectively interact with real biological neurons.

Scientists presented a smart bionic finger that can create 3D maps of the internal structure of materials by touching their exterior surface.
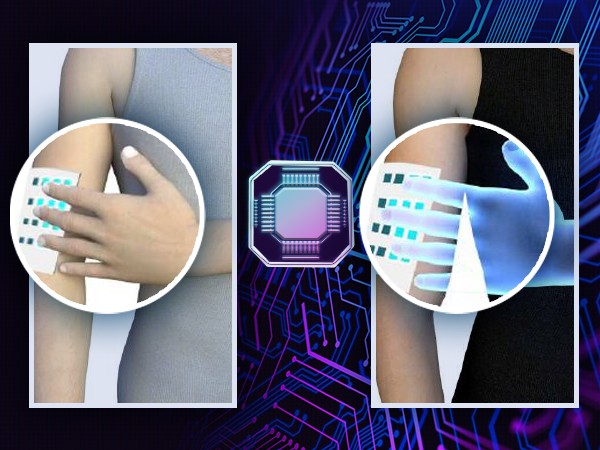
The wireless soft e-skin can both detect and transmit the sense of touch, and form a sensory network, which opens up great possibilities for improving interactive sensory communication.

Meta AI launched LLaMA, a collection of foundation language models that can compete with or even outperform the best existing models such as GPT-3, Chinchilla and PaLM.

MusicLM is a new music generation AI that creates high-quality music based on textual descriptions in a similar way that DALL-E generates images from texts.

Scientists from the University of Michigan conducted a study of robot behavior strategies to restore trust between a bot and a human. Can such strategies fully restore trust and how effective are they after repeated errors?

A group of researchers have created a Bayesian machine, an AI approach that performs computations based on Bayes' theorem, using memristors. It is significantly more energy-efficient than existing hardware solutions, and could be used for safety-critical applications.

Using advances in artificial intelligence engineers at the University of Colorado Boulder are working on a new type of walking cane for blind or visually impaired.

Tel Aviv University researchers have achieved a technological-biological breakthrough: in response to the presence of an odor, the new biological sensor sends data that the robot is able to detect and interpret.

Text-to-speech models usually require significantly longer training samples, while VALL-E creates a much more natural-sounding synthetic voice from just a few seconds.
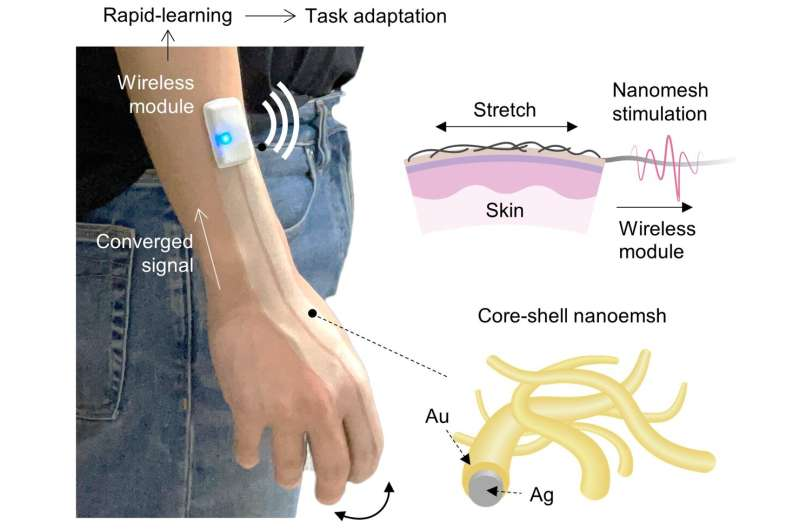
Researchers from Stanford University developed a new type of stretchable biocompatible material that gets sprayed on the back of the hand and can recognize its movements.

Point·E is a new system for text-conditional synthesis of 3D point clouds that first generates synthetic views and then generates colored point clouds conditioned on these views.

Self-driving cars have long been considered the next generation mode of transportation. To enable autonomous navigation of such vehicles numerous different technologies need to be implemented.
New research from the Pacific Northwest National Laboratory uses machine learning, data analysis and artificial intelligence to identify potential nuclear threats.

Researchers have discovered new ways for retailers to use AI in conjunction with in-store cameras to better understand consumer behavior and adapt store layouts to maximize sales.
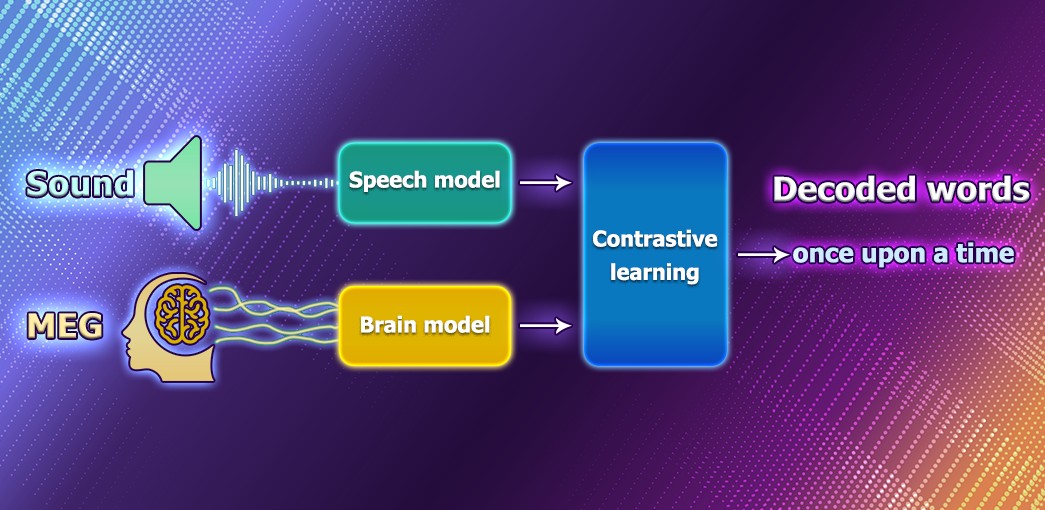
Decoding speech based on brain activity has been a long-established goal of neuroscientists and clinicians. Nowdays, Meta is working on an AI model that can decode speech from noninvasive recordings of brain activity to help people after traumatic brain injury.

Look to Speak is designed to help those with motor function impairments and speech difficulties to communicate more easily. The app lets people use their eyes to select pre-written phrases and have them spoken out loud.

MIT researchers have developed a machine-learning technique that precisely collects and models the underlying acoustics of a location from just a limited number of sound recordings.

By 2050 humanity will have to almost double the global food supply to make sure that every dweller of the planet has enough food. With climate change going at increasing speed, water resources drop and arable lands erode, doing that sustainably will be a huge challenge for us.

During the last decade, one of the biggest issues in the gaming industry is the explosive growth of the AAA video games production cost. Studios are always on the look-up for technologies that could help bring down the cost of game development. Recent advances in the neural image generation models bring some hope that the realization of this dream may be not so far away.

Can computers think? Can AI models be conscious? These and similar questions often pop up in discussions of recent AI progress, achieved by natural language models GPT-3, LAMDA and other transformers. They are nonetheless still controversial and on the brink of a paradox, because there are usually many hidden assumptions and misconceptions about how the brain works and what thinking means. There is no other way, but to explicitly reveal these assumptions and then explore how the human information processing could be replicated by machines.

Now you won’t surprise anyone with filters that improve the quality of photos. But the restoration of old portraits still leaves much to be desired. Older photos tend to be too blurry, so normal image sharpening methods won't work on them.

Facebook has released the NLLB project (No Language Left Behind). The main feature of this development is the coverage of more than two hundred languages, including rare languages of African and Australian peoples. In addition, Facebook has applied a new approach to the machine learning model, where the translation is carried out directly from one language to another, without intermediate translation into English.

A group of scientists using machine learning "rediscovered" the law of universal gravitation.
Animated avatars have long become a part of our lives. But realistic modeling of closing animation still remained an open challenge.
On the one hand, modern physical modeling techniques can generate realistic clothing geometry at interactive speed. On the other hand, modeling a photorealistic appearance usually requires physical rendering, which is too expensive for interactive applications.
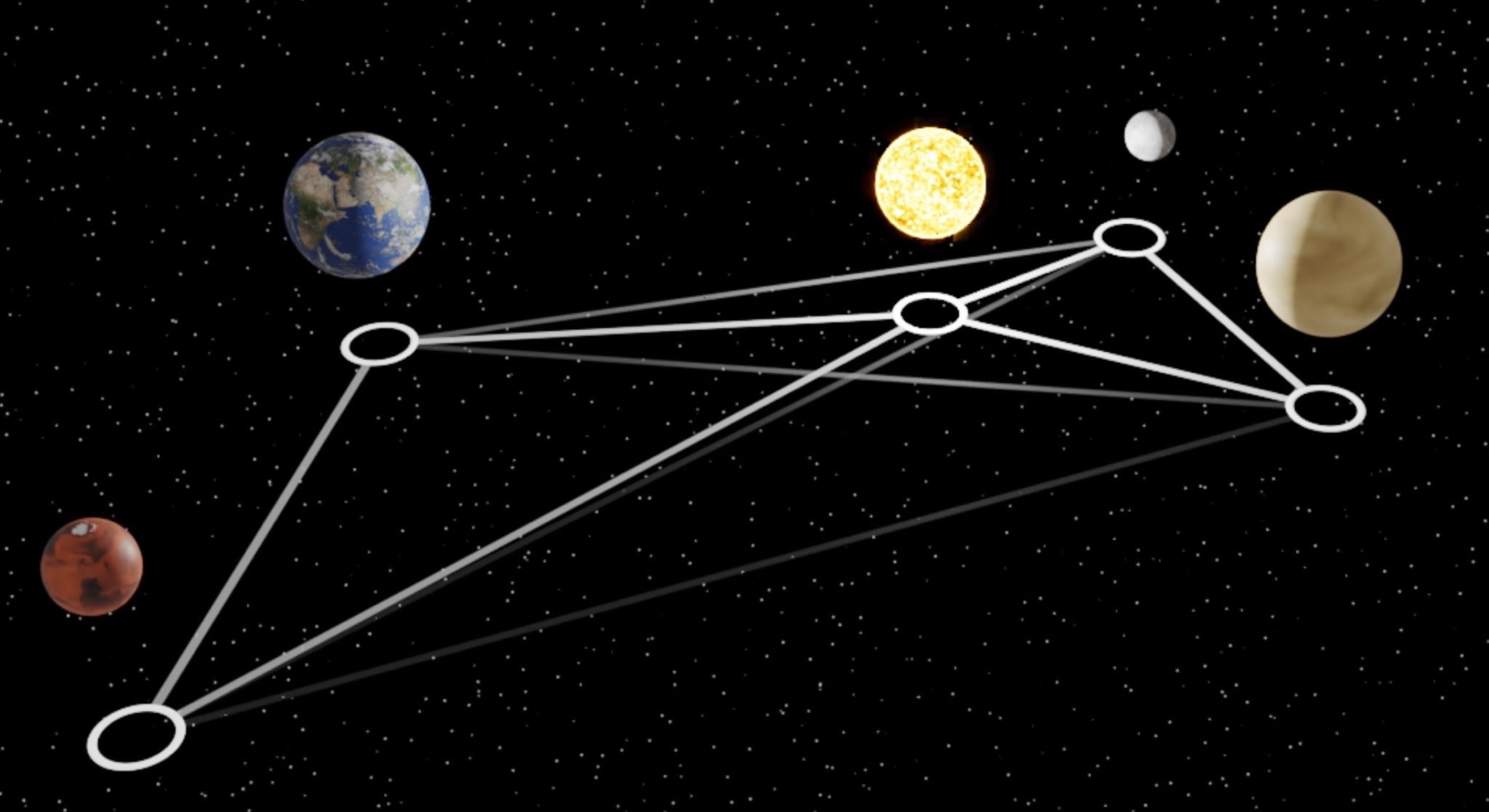
A group of scientists using machine learning "rediscovered" the law of universal gravitation.
To do this, they trained a "graph neural network" to simulate the dynamics of the Sun, planets and large moons of the solar system from 30 years of observations. Then they used symbolic regression to discover the analytical expression for the force law implicitly learned by the neural network.